mysql优化实战(explain && 索引)
|
1、sql工具:Navicat
2、sql数据库,使用openstack数据库作为示例
|
|
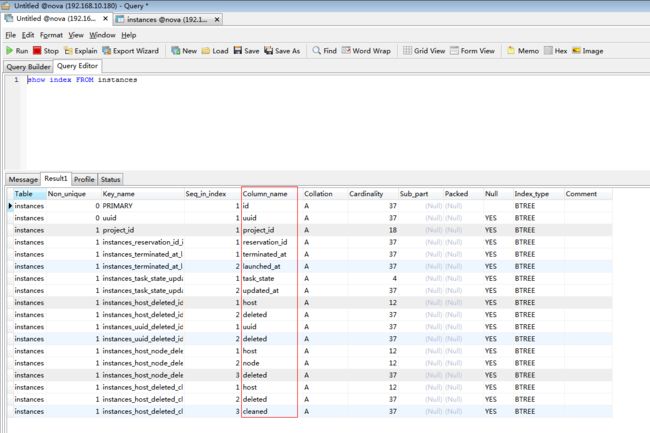
show index from instances
|
|
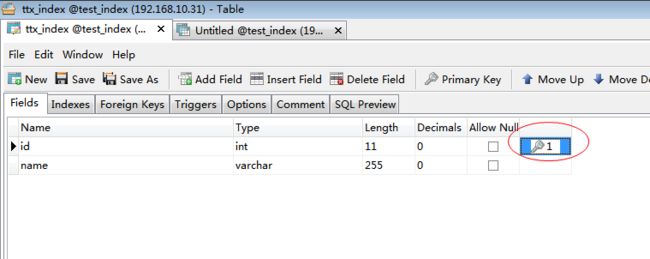
Table:数据库表名
Non_unique:索引不能包括重复词,则为0。可以,则为1。
Key_name:索引的名称。
索引中的列序列号,从1开始。
列名称
列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机 会就越大。
如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
指示关键字如何被压缩。如果没有被压缩,则为NULL。
如果列含有NULL,则为YES。如果没有,则该列为NO。
用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
Comment:注释。 |

|
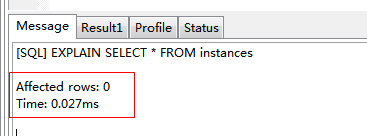
EXPLAIN SELECT * FROM instances
|

|
table:显示这一行的数据是关于哪张表的 type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句 key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引 key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好 ref:显示索引的哪一列被使用了,如果可能的话,是一个常数 rows:MYSQL认为必须检查的用来返回请求数据的行数 Extra:关于MYSQL如何解析查询的额外信息。将在下表中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢 extra列返回的描述的意义:
|
|
EXPLAIN SELECT * FROM instances WHERE id=1
|

|
SELECT id, display_name FROM instances WHERE id=1
|

|
EXPLAIN SELECT * FROM instances WHERE display_name = "vm1"
|

|
SELECT COUNT(*) FROM instances
|
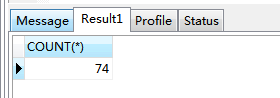
|
insert instances(display_name) select display_name from instances
|
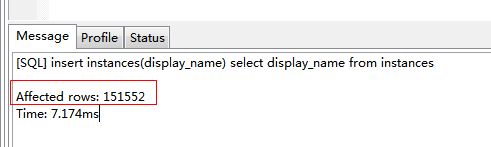
|
SELECT COUNT(*) FROM instances
|
|
SELECT id, display_name FROM instances WHERE id=1
|
|
SELECT * FROM instances WHERE display_name = 'test_index_dispaly_name'
|
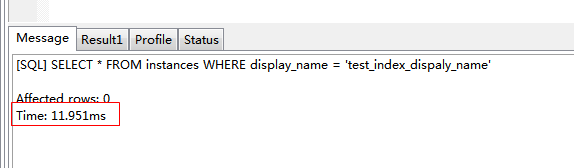
|
SELECT * FROM instances WHERE id=1
|
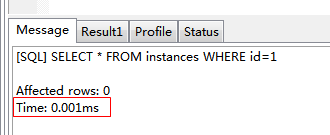
|
时间关系,此处暂且未总结,后续有时间补上。若有需要请自行网上查找。
|