[置顶] 基于领域的算法 —— 利用用户行为数据一 —— 《推荐系统实践》阅读笔记二
为了让推荐结果符合用户口味,我们需要深入了解用户。用户的行为不是随机的,而是蕴含着许多模式的。基于用户行为分析的推荐算法是个性化推荐系统的重要算法,仅仅基于用户行为数据设计的推荐算法学术上称作“协同过滤算法”。协同过滤,就是指用户可以齐心协力,通过不断地和网站互动,是自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
系统过滤算法,包含基于领域的算法、隐语义模型、基于图的算法等。
下面我们先从用户行为数据的一些特点讲起,再详细讲解上述各类算法。
1、用户行为数据
1.1 简介
用户行为数据在网站上最简单的存放形式就是日志。网站在运行过程中都会产生大量原始日志,很多互联网业务会把多种原始日志按照用户行为汇总成会话日志,其中每个会话表示一次用户行为和对应的服务。会话日志通常存储在分布式数据仓库中,如支持离线分析的Hadoop Hive和支持在线分析的Google Dremel。
用户行为在个性化推荐系统中一般分为两种:显性反馈行为,和隐性反馈行为。显性反馈行为包括用户明确表示对物品喜恶的行为。隐性反馈行为指的是那些不能明确反映用户喜恶的行为,但数据量更大。在很多网站中,很多用户甚至只有隐性反馈数据。
互联网中的用户行为有很多种,用一种统一的方式来表示所有行为很困难。一种叫可行的用户行为的统一表示可以包含以下部分:
user id,item id,behavior type,context(上下文),behavior weight,behavior content。
1.2 用户行为中蕴含的规律
互联网上的很多数据分布都满足Power Law分布,在互联网领域也称作长尾分布:。
有意义的是,很多用户行为数据也蕴含着这种规律,例如:
这些规律并不是只存在于一两个网站中的特例,而是存在于很多网站中的普遍规律。对
个物品产生过行为用户数;
被
对应物品流行度为
对应用户活跃度为
对应用户活跃度为
等等。。。。
2、基于领域的算法
2.1 基于用户的协同过滤算法
1、 UserCF是推荐系统中最古老的算法,其诞生标志着推荐系统的诞生。UserCF算法主要包含两个步骤:
(1) 找到和目标用户兴趣相似的用户集合
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品,并将其推荐给目标用户。
2、 UserCF算中(1)中,用户之间的兴趣相似度可以通过余弦相似度公式计算
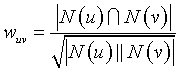
实际上,用户间对冷门物品采取过同样的行为更能说明他们兴趣的相似度,因此,我们可以通过惩罚用户间共同兴趣列表中热门物品的影响(通过下式可见是用分子惩罚的),对上述用户相似度计算式进行改进
3、 UserCF算中(2)中,度量用户对某物品的感兴趣程度可以用:
其中r为用户v对物品i的兴趣指数。
4、UserCF算法(与改进兴趣相似度公式后的User-IIF算法)的Python实现
### UserCF algorithm ### def UserSimilarity(train): # input trainSet is a dict, for example: # train = {'A':{'a':rAa, 'b':rAb, 'd':rAd}, 'B':{...}, ...} # build the inverse table for item_users item_users_table = dict() for user, items in train.items(): for item in items.keys(): if item not in item_users_table: item_users_table[item] = set() item_users_table[item].add(user) # calculate co-rated items between users # item_users_table = {'a':set('A','B'), 'b':set('A','C'), ...} C = dict() # this is the member of W N = dict() for item, users in item_users_table.items(): for uu in users: N[uu] += 1 for vv in users: if uu == vv: continue ## simple cosine user similarity C[uu][vv] += 1 ## modified cosine user similarity C[uu][vv] += 1 / math.log(1.0+len(item)) # calculate final similarity matrix W W = dict() for uu, related_user in C.items(): for vv, Cuv in related_user.items(): W[uu][vv] = Cuv / math.sqrt(N[uu]*N[vv]) return W def Recommend(train, user_u, W, K): rank = dict() uu = user_u interacted_items = train[uu] # S(u,K) ahead of N(i) for vv, Wuv in sorted(W[uu].items, key=itemgetter(1), reverse=True)[0:K]: for item, rvi in train[vv].items(): if item in interacted_items.keys(): continue # filter the items which user interacted before rank[item] += Wuv * rvi return rank
5、 算法性能分析
(1) UserCF算法中重要参数K与推荐算法的精度指标(Recall和Precision)并不成线性增长关系,且精度对K也不是特别敏感。
(2) K越大,参考的人越多,结果就越趋近于全局热门物品,因而导致流行度指数越高,即推荐结果的新颖度降低。
(3) 随着K增大,推荐物品的流行度增加,算法将倾向于推荐热门物品,从而对长尾物品挖掘能力变差,造成算法覆盖率降低。
(4) UserCF算法固有缺点在于:一则,随着网站的用户数目增多,计算用户兴趣相似度矩阵W将越来越困难,其运算时间复杂度和空间复杂度的增长与用户数的增长近似成平方关系。二来,UserCF算法难以对其推荐的结果作出解释,不太适用于商品推荐、视频推荐等场景。
2.2 基于物品的协同过滤算法
1、 ItemCF算法是目前业界应用最多的算法。ItemCFB算法并不是利用物品的内容属性计算物品之间的相似度,而是通过分析大量用户的行为来记录并计算物品之间的相似性,因此可以利用用户的历史行为给推荐结果提供推荐。ItemCF算法主要分为两步:
(1) 计算物品之间的相似度
(2) 根据物品的相似度以及用户的历史行为给用户生成推荐列表
2、 ItemCF算法(1)中,在前提“每个用户的兴趣都局限在某几个方面”下,可以用下式计算
当上式还存在一个问题,由于每个用户的兴趣列表都会对物品的相似度产生贡献,但活跃用户的兴趣显然没有非活跃用户的兴趣那么集中,应该使活跃用户对物品相似度的贡献低于不活跃用户才合理,因此可以引进IUF,即用户活跃度对数的倒数的参数,对上式进行改进:
实际上,IUF只是对活跃用户做了一种软性惩罚, 实际计算中,往往直接把过于活跃的用户的兴趣列表忽略掉,完全不将其纳入相似度计算中,同时避免了相似度矩阵过于稠密。
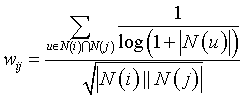
3、 ItemCF算法(2)中,度量用户对某物品的感兴趣程度可以用:
4、 ItemCF算法(与改进兴趣相似度公式后的Item-IUF算法)的Python实现
### ItemCF algorithm ### def ItemSimilarity(train): # calculate co-rated users between items C = dict() N = dict() for user, items in train.items(): for ii in items: N[ii] += 1 for jj in items: if ii == jj: continue ## the simple cosine item similarity C[ii][jj] += 1 ## the modified cosine item similarity C[ii][jj] += 1 / math.log(1.0+len(user)) # calculate final similarity matrix W W = dict() for ii, related_items in C.items(): for jj, Cij in related_items.items(): W[ii][jj] = Cij / math.sqrt(N[ii]*N[jj]) return W def Recommend(train, user_u, W, K): rank = dict() uu = user_u interacted_items = train[uu] # N(u) ahead of S(j,K) for item, rui in interacted_items.items(): for jj, Wij in sorted(W[item].items, key = itemgetter(1), reverse = True)[0:K]: if jj in interacted_items.keys(): continue # filter the items which user interacted before rank[jj].weight += Wij * rui rank[jj].reason[item] = Wij * rui # give the reason of recommendation return rank
5、 算法性能分析
(1) 同样,ItemCF算法中参数K也不与结果精度呈正相关或者负相关。
(2) 区别于UserCF,参数K对ItemCF结果的流行度并不是完全正相关的,随着K增大,流行度逐渐提高但最终会缓慢下降。
(3) 同UserCF,K的增加会降低系统的覆盖率。
(4) 注意,通过将ItemCF的相似度矩阵按列最大值归一化,可以提高系统的准确率、覆盖率和多样性,即
。
(5) ItemCF算法的覆盖率和新颖度都不高,是由于热门物品在相似度矩阵计算中造成了太大的影响,一般可以在wij的分母上对N(i)取指数1-alpha,N(j)取指数alpha,通过调整使热门物品的alpha大于0.5,甚至更大,对其作出惩罚,可以一定程度上牺牲精度而显著提高覆盖率和新颖性。但此方法依然效果一般,即在不同领域的最热门物品之间往往具有较高的相似度情况下,仅仅靠用户行为数据很难解决上述问题。此时,只能依靠引入物品的内容数据解决此问题,比如对不用领域的物品降低权重等,当然这些暂时不是协同过滤的讨论范畴。
2.3 UerCF 与ItemCF 比较
1、 从二者的推荐原理来看,UserCF的推荐结果着重于反应和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维系用户的历史兴趣,即,前者的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而后者更加个性化,反映了用户自己的兴趣传承。2、 从技术角度来看,UserCF需要维护一个用户相似度矩阵,而ItemCF需要维护一个物品相似度矩阵。3、 从这两点,大致能看出为什么文章分享网站Digg使用前者,而亚马逊使用了后者。4、 这从另一方面又启示我们,离线实验的性能并不是选择推荐算法的决定性要素,反而应该按照以下顺序来选取:(1)应该满足产品的需求,例如是否需要提供推荐解释(2)需要看实现代价,也就是用户更多还是物品更多(3)离线指标和点击率等在线指标不一定成正比,即使离线指标不太好也没关系,何况经过各种优化改进,一般都不会太差。5、 来份优缺点对表表:![[置顶] 基于领域的算法 —— 利用用户行为数据一 —— 《推荐系统实践》阅读笔记二_第1张图片](http://img.e-com-net.com/image/info5/27b56e1a1a5342beb5e8dc4417f3382d.jpg)