逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
对于有m个样本的训练集 ,
,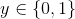 。在上篇介绍决策边界的时候已经介绍过了在logistic回归中的假设函数为: 。因此我们定义logistic回归的代价函数(cost function)为:
。在上篇介绍决策边界的时候已经介绍过了在logistic回归中的假设函数为: 。因此我们定义logistic回归的代价函数(cost function)为: , 下面来解释下这两个公式,先来看y=1时,
, 下面来解释下这两个公式,先来看y=1时, ,画出的函数图像为:
,画出的函数图像为:
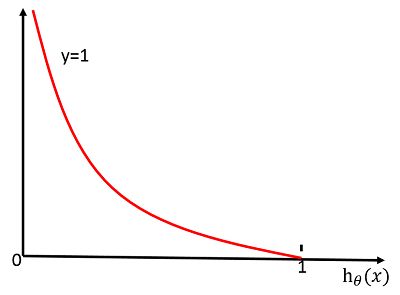
从图中可以看出,y=1,当预测值 时,可以看出代价函数cost的值为0,这正是我们希望的。如果预测值 即
时,可以看出代价函数cost的值为0,这正是我们希望的。如果预测值 即 ,意思是预测y=1的概率为0,但是事实上y=1,因此代价函数
,意思是预测y=1的概率为0,但是事实上y=1,因此代价函数 相当于给学习算法一个惩罚。
相当于给学习算法一个惩罚。
同理我们也可以画出当y=0时,函数 的图像:
的图像:
同样也能看出上面y=1时介绍的那些信息,我就不再说了。
对于上面的代价函数, ,其中 可以写成更加简洁的形式: ,这个公式更加简洁,可以看出,当y=1时,公式变为,当y=0时,公式变为 与上面的公式完全等价。因此代价函数为:
为了求解使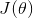 最小的参数
最小的参数 ,还是要用梯度下降(gradient descent),即
,还是要用梯度下降(gradient descent),即
 ,
,
看来其和线性回归中的梯度下降函数形式一模一样,但其实是不一样的,因为在logistic回归中
。
为了让大家明白从公式怎么推到公式 的,我把这个公式的求导过程写一下:
的,我把这个公式的求导过程写一下:
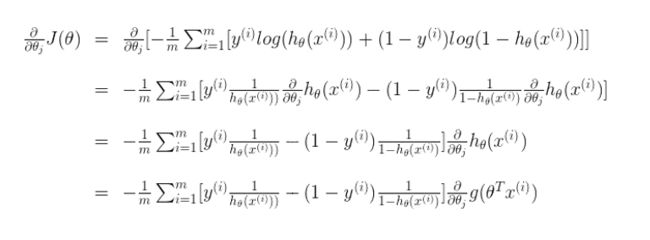
大家可以自己在纸上推推,对求导不熟悉的可以去补补高数上,微积分。
关于logistic回归里的代价函数和梯度下降就介绍到这。还有一些高级优化算法,如 conjugate gradient、BFGS和L-BFGS这些算法不需要手动选择学习率 ,而且收敛的速度要远快于梯度下降。但是这些算法太过复杂,不太容易搞明白。
,而且收敛的速度要远快于梯度下降。但是这些算法太过复杂,不太容易搞明白。
注意:再强调一下,写博客不容易,尤其编辑公式很花费时间。转载或者引用请注明原文作者和链接,尊重原创。最近发现有人公然复制博客当成自己的原创,这种行为不值得尊重。