深入解析开源项目之Universal-Image-Loader(二)缓存篇
珍惜作者劳动成果,如需转载,请注明出处。
http://blog.csdn.net/zhengzechuan91/article/details/50292871
Universal-Image-Loader (Github地址) 是一个优秀的图片加载开源项目,Github地址在 ,很多童鞋都在自己的项目中用到了。优秀的项目从来都是把简单留给开发者,把复杂封装在框架内部。ImageLoader作为Github上Star数过万的项目,备受开发者青睐,所以我们有必要搞清楚它的内部实现。
在上一篇博客中我们分析了ImageLoader框架的整体实现原理,还没有看过的直接坐电梯到 深入解析开源项目之ImageLoader(一)框架篇 。
ImageLoader缓存之内存篇

由上图我们可以看出:
MemoryCache接口定义了Bitmap缓存相关操作;
抽象类BaseMemoryCache中则使用HashMap保存了Bitmap的软/弱引用;
LimitedMemoryCache类则使用LinkedList保存了Bitmap强引用,并加入了对最大可用内存的限定。
BaseMemoryCache中的代码很简单,只是简单的将Bimtap从保存软/弱引用的HashMap中添加或移除。
接下来我们看看LimitedMemoryCache中是怎样实现将Bitmap缓存在内存中的:
/* LimitedMemoryCache.java */
public boolean put(String key, Bitmap value) {
//这个字段表示是否添加到强引用成功
boolean putSuccessfully = false;
int valueSize = getSize(value);
int sizeLimit = getSizeLimit();
int curCacheSize = cacheSize.get();
//如果Bitmap尺寸没超过限定尺寸
if (valueSize < sizeLimit) {
while (curCacheSize + valueSize > sizeLimit) {
//如果添加Bitmap后超过了限定尺寸,根据抽象方
//法removeNext()移除强引用列表中的Bitmap,
//直到小于限定尺寸
Bitmap removedValue = removeNext();
if (hardCache.remove(removedValue)) {
curCacheSize = cacheSize.addAndGet(-getSize(removedValue));
}
}
//添加到强引用的列表中
hardCache.add(value);
cacheSize.addAndGet(valueSize);
putSuccessfully = true;
}
//添加到软/弱引用中
super.put(key, value);
return putSuccessfully;
}在看看LimitedMemoryCache的移除操作:
/* LimitedMemoryCache.java */
public Bitmap remove(String key) {
Bitmap value = super.get(key);
if (value != null) {
//软/弱引用存在,移除强引用
if (hardCache.remove(value)) {
cacheSize.addAndGet(-getSize(value));
}
}
//移除软/弱引用
return super.remove(key);
}
再看看/cache/memory/impl实现中,分为三类:
| 实现MemeryCache | 继承LimitedMemoryCache | 继承BaseMemoryCache |
|---|---|---|
| FuzzyKeyMemoryCache | FIFOLimitedMemoryCache | WeakMemoryCache |
| LimitedAgeMemoryCache | LargestLimitedMemoryCache | |
| LruMemoryCache | LRULimitedMemoryCache | |
| UsingFreqLimitedMemoryCache |
下面逐一对上面的实现分析:
实现MemeryCache
FuzzyKeyMemoryCache
用到了装饰模式,对MemoryCache的put(String key, Bitmap value)方法进行加强处理:先移除key相同的Bitmap,再添加新的key对应的Bitmap:
/* FuzzyKeyMemoryCache.java */
public boolean put(String key, Bitmap value) {
synchronized (cache) {
String keyToRemove = null;
for (String cacheKey : cache.keys()) {
if (keyComparator.compare(key, cacheKey) == 0) {
//找到Uri相同的
keyToRemove = cacheKey;
break;
}
}
//先移除Uri相同的Cache
if (keyToRemove != null) {
cache.remove(keyToRemove);
}
}
//再将新的key对应的值放入Cache
return cache.put(key, value);
}
LimitedAgeMemoryCache
也是对MemoryCache的装饰,对MemeryCache的get(String key)做了加强处理:当我们在获取内存Cache中的Bitmap时,如果超过最大存活时间则不在返回
/* LimitedAgeMemoryCache.java */
public Bitmap get(String key) {
Long loadingDate = loadingDates.get(key);
if (loadingDate != null && System.currentTimeMillis() - loadingDate > maxAge) {
//如果超过最大存活时间,则从Cache中移除掉
cache.remove(key);
loadingDates.remove(key);
}
return cache.get(key);
}LruMemoryCache
在LinkedHashMap中保存了Bitmap的强引用,并限定了强引用的最大内存,这里稍微解释下LinkedHashMap的构造方法:
/* LruMemoryCache.java */
this.map = new LinkedHashMap<String, Bitmap>(0, 0.75f, true);主要是最后一个参数:返回true表示排序的顺序是从最远使用到最近使用,而返回false顺序则为插入时的顺序。
再来看LruMemoryCache#put()方法的实现:
/* LruMemoryCache.java */
public final boolean put(String key, Bitmap value) {
synchronized (this) {
size += sizeOf(key, value);
//如果之前没有没有添加过,添加后返回null
Bitmap previous = map.put(key, value);
//说明该key对应的Bitmap已经存在
if (previous != null) {
size -= sizeOf(key, previous);
}
}
//遍历LinkedList,移除最远使用的Bitmap,直到小于最大
//限定的内存大小
trimToSize(maxSize);
return true;
}移除的操作如下:
/* LruMemoryCache.java */
public final Bitmap remove(String key) {
synchronized (this) {
//移除key对应的Bitmap,存在则返回该Bitmap,否则返
//回null
Bitmap previous = map.remove(key);
//如果移除的Bitmap存在
if (previous != null) {
size -= sizeOf(key, previous);
}
return previous;
}
}我们看到map实例化时并不是线程安全的,所以在所有的操作中都有同步锁。
继承LimitedMemoryCache
我们知道这类Cache缓存都是软/弱引用和限定内存的强引用的结合(强引用是List,软引用是Map),重写LimitedMemoryCache主要是来实现removeNext()方法,以指定超过内存最大限定后移除Bitmap的规则。
FIFOLimitedMemoryCache
先进先出队列
/* FIFOLimitedMemoryCache.java */
public boolean put(String key, Bitmap value) {
//成功添加到强引用和软/弱引用中,其中在超出内存限定后会
//对内存中的Bitmap缩减
if (super.put(key, value)) {
//添加到队列中
queue.add(value);
return true;
} else {
return false;
}
}我们看到queue是没限定内存的,难道不怕在我们滑动列表的过程中内存溢出?
如果你注意到了这个细节,说明你代码看的很仔细,我们来分析下这块的逻辑:我们在调用super.put(key, value)时,如果发现内存超出了限定值,我们会根据removeNext()来依次删除强引用中的Bitmap,而在FIFOLimitedMemoryCache中,removeNext()实现如下:
/* FIFOLimitedMemoryCache.java */
protected Bitmap removeNext() {
return queue.remove(0);
}LinkedList默认就是根据插入时的顺序的,所以直接返回第一个元素,同时从queue中移除了第一个元素,所以也达到了限定内存的目的。
/* FIFOLimitedMemoryCache.java */
public Bitmap remove(String key) {
Bitmap value = super.get(key);
//如果软/弱引用存在
if (value != null) {
//从队列移除
queue.remove(value);
}
//从强引用和软/弱引用移除
return super.remove(key);
}这个queue与父类强引用其实是一样的,都是LinkedList,queue之所以存在是因为为了代码的一致性,父类中并没有对外部(包括子类)暴露强引用,我们没办法对强引用直接操作,所以大家都是缓存一份自己的队列。
LargestLimitedMemoryCache
在put()时保存了每个Bitmap的size,这个类主要实现了超过内存限定后删除Bitmap的removeNext()方法:找出占用内存最大的图片返回。
LRULimitedMemoryCache
利用LinkedHashMap的特性实现LRU的特点,重点也是重写了removeNext()方法:
/* LRULimitedMemoryCache.java */
//用LinkedHashMap来保存Bitmap
private final Map<String, Bitmap> lruCache = Collections.synchronizedMap(new LinkedHashMap<String, Bitmap>(INITIAL_CAPACITY, LOAD_FACTOR, true));跟LruMemoryCache中的Map实现方式相似:
/* LRULimitedMemoryCache.java */
protected Bitmap removeNext() {
Bitmap mostLongUsedValue = null;
synchronized (lruCache) {
Iterator<Entry<String, Bitmap>> it = lruCache.entrySet().iterator();
if (it.hasNext()) {
Entry<String, Bitmap> entry = it.next();
mostLongUsedValue = entry.getValue();
it.remove();
}
}
return mostLongUsedValue;
}由于LinkedHashMap的特点,以上方法每次迭代lruCache时,都是先删除最远使用的。
UsingFreqLimitedMemoryCache
用一个HashMap来保存每个Bitmap的使用次数,当调用put()方法时,使用次数置零,当调用get()方法时,使用次数加1。removeNext()的实现方式比较简单:直接找出hashmap中使用次数最少的,然后返回。
到此,对ImageLoader内存缓存的分析结束。
ImageLoader缓存之磁盘篇
看完内存缓存的分析,再来看看磁盘缓存的逻辑。
相关的接口和类的关系如下:
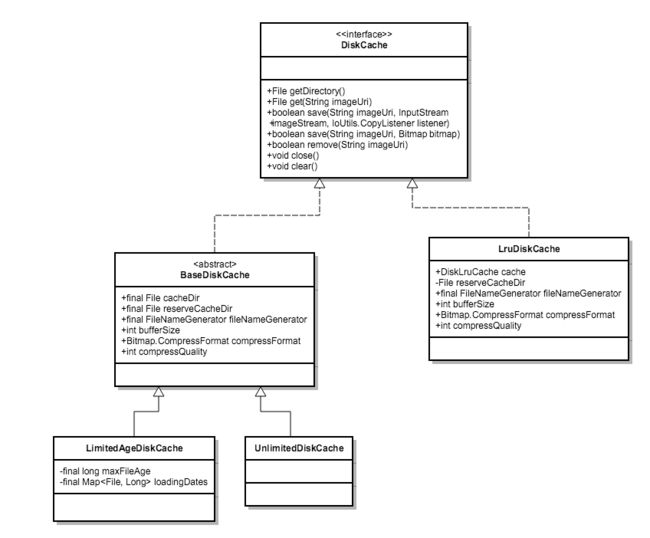
DiskCache
首先是DiskCache接口定义了磁盘的一些基本操作:
/* DiskCache.java */
public interface DiskCache {
File getDirectory();
File get(String imageUri);
boolean save(String imageUri, InputStream imageStream, IoUtils.CopyListener listener) throws IOException;
boolean save(String imageUri, Bitmap bitmap) throws IOException;
boolean remove(String imageUri);
void close();
void clear();
}BaseDiskCache
而基类BaseDiskCache则实现了这些基本操作,并定义了一些默认值
/* BaseDiskCache.java */
//默认的buffer大小为32k
public static final int DEFAULT_BUFFER_SIZE = 32 * 1024;
//默认的图片格式为PNG
public static final Bitmap.CompressFormat DEFAULT_COMPRESS_FORMAT = Bitmap.CompressFormat.PNG;
//默认的图片质量为100
public static final int DEFAULT_COMPRESS_QUALITY = 100;
save(String imageUri, InputStream imageStream, IoUtils.CopyListener listener)方法从输入流读取数据,然后根据imageUri,将数据读取到磁盘上。
这个方法最主要的代码是:
/* BaseDiskCache.java */
loaded = IoUtils.copyStream(imageStream, os, listener, bufferSize);
我们看看copyStream()方法的实现:
/* BaseDiskCache.java */
//返回true表示成功的读取了输入流,返回false则表示listener
//中断了输入流的读取。
public static boolean copyStream(InputStream is, OutputStream os, CopyListener listener, int bufferSize)
throws IOException {
int current = 0;
int total = is.available();
if (total <= 0) {
total = DEFAULT_IMAGE_TOTAL_SIZE;
}
final byte[] bytes = new byte[bufferSize];
int count;
//拦截加载
if (shouldStopLoading(listener, current, total)) return false;
while ((count = is.read(bytes, 0, bufferSize)) != -1) {
os.write(bytes, 0, count);
current += count;
//拦截加载
if (shouldStopLoading(listener, current, total)) return false;
}
//如果是buffer类型,flush()
os.flush();
return true;
}我们看看shouldStopLoading()listener中是怎么拦截的:
/* BaseDiskCache.java */
private static boolean shouldStopLoading(CopyListener listener, int current, int total) {
if (listener != null) {
boolean shouldContinue = listener.onBytesCopied(current, total);
if (!shouldContinue) {
if (100 * current / total < CONTINUE_LOADING_PERCENTAGE) {
return true;
}
}
}
return false;
}当设置了listener拦截数据后,每次得到current和total并处理后,通知回来是否还要继续读取输入流,如果不继续读取,则会判断当前加载进度是否超过了75%,超过75%会强制加载完,否则会停止读取。
也就是说,当我们不想继续传输的时候,我们只需要将listener的onBytesCopied()方法返回false即可。
而save(String imageUri, Bitmap bitmap)方法则是通过Bitmap#compress(CompressFormat format, int quality, OutputStream stream)方法则是将Bitmap直接缓存在imageUri所在的磁盘目录下。
BaseDiskCache中的File都是通过getFile(String imageUri)来取的:
我们看看这个方法的代码:
/* BaseDiskCache.java */
protected File getFile(String imageUri) {
String fileName = fileNameGenerator.generate(imageUri);
File dir = cacheDir;
if (!cacheDir.exists() && !cacheDir.mkdirs()) {
if (reserveCacheDir != null && (reserveCacheDir.exists() || reserveCacheDir.mkdirs())) {
dir = reserveCacheDir;
}
}
return new File(dir, fileName);
}我们发现除了缓存目录cacheDir,还可以通过构造方法设置备用的目录reserveCacheDir,以便在cacheDir不可用时使用。
UnlimitedDiskCache
UnlimitedDiskCache是BaseDiskCache(无抽象方法)的默认实现,没有增加任何处理。
LimitedAgeDiskCache
而LimitedAgeDiskCache则是在BaseDiskCache的基础上,用HashMap缓存了每个文件保存时的时间戳。
/* LimitedAgeDiskCache.java */
public File get(String imageUri) {
File file = super.get(imageUri);
if (file != null && file.exists()) {
boolean cached;
Long loadingDate = loadingDates.get(file);
if (loadingDate == null) {
cached = false;
loadingDate = file.lastModified();
} else {
cached = true;
}
//如果超过了maxFileAge则直接删除掉
if (System.currentTimeMillis() -
loadingDate > maxFileAge) {
file.delete();
loadingDates.remove(file);
} else if (!cached) {
//如果文件存在但是loadingDates中找不到时,将
//此文件的时间戳加到loadingDates中
loadingDates.put(file, loadingDate);
}
}
return file;
}LruDiskCache
接下来我们主要分析下LruDiskCache,这个类直接实现了DiskCache,并借助于专门封装LRU算法的DiskLruCache类来完成磁盘的实际操作。
DiskLruCache
让我们先来看看LruDiskCache主要用到的DiskLruCache中的接口:
| 返回值类型 | 方法 | 方法说明 |
|---|---|---|
| DiskLruCache | open() | 创建DiskLruCache实例 |
| Snapshot | get() | 获取缓存实体Entry的快照-读 |
| Editor | edit() | 获取实体Entry的编辑器-写 |
| boolean | remove() | 移除LRU中的实体Entry-删 |
实例化 - open()
DiskLruCache的构造方法是private类型的,所以只能通过open()方法获取DiskLruCache的实例,其它的操作都要是这个实例来完成。
参数的含义分别如下:
| 返回类型 | 参数 | 说明 |
|---|---|---|
| File | directory | 缓存文件存储路径 |
| int | appVersion | 应用版本号 |
| int | valueCount | 每个key对应的value的数量 |
| long | maxSize | 缓存的最大size |
| int | maxFileCount | 缓存的最大数量 |
而LruDiskCache中获取DiskLruCache代码如下:
/* LruDiskCache.java */
//appVersion和valueCount为1,maxSize和maxFileCount
//外部传入。
cache = DiskLruCache.open(cacheDir, 1, 1, cacheMaxSize, cacheMaxFileCount);
读 - get()
根据key查找Entry的快照,并提供了Snapshot#getFile(int index)来获取这个文件和Snapshot#getInputStream(int index)来获取输入流,其中参数index即为open()方法参数valueCount的下标。
LruDiskCache中获取文件代码如下:
/* LruDiskCache.java */
//根据key取到实体的快照snapshot
snapshot = cache.get(getKey(imageUri));
//通过snapshot的getFile()获取文件
return snapshot == null ? null : snapshot.getFile(0);这里getFile()参数为0,这是因为我们在前面open()方法时定义了valueCount = 1,每个key只有一个value与之对应。
写 - edit()
根据key查找Entry的编辑器,Entry写入相关的操作都是通过Editor来完成的,然后提供了Editor#newInputStream(int index)构建输入流或Editor#newOutputStream(int index)构建输出流。
LruDiskCache中写入磁盘的代码如下:
/* LruDiskCache.java */
//根据key去获取编辑器editor
DiskLruCache.Editor editor = cache.edit(getKey(imageUri));
//通过editor构建输出流,这里生成了dirty文件
OutputStream os = new
BufferedOutputStream(editor.newOutputStream(0), bufferSize);
boolean copied = false;
//将输入流imageStream写入dirty(tmp格式)文件
copied = IoUtils.copyStream(imageStream, os, listener, bufferSize);
edit()只是获取到一个Editor的实例,最后别忘了调用Editor#commit()提交或调用Editor#abort()丢弃此次编辑。而commit()方法通过将dirty文件renameTo()为clean文件完成文件写入的。
这里说说Editor#newInputStream(int index)和Editor#newOutputStream(int index)这两个方法
前者构建的输入流是read时需要的,实际调用的是Entry#getCleanFile(int i)文件的输入流
/* DiskLruCache$Editor.java */
public InputStream newInputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
try {
return new FileInputStream(entry.getCleanFile(index));
} catch (FileNotFoundException e) {
return null;
}
}
}这个clean文件是在commit()时,从dirty文件renameTo()来的。
而后者构建的输出流是write时需要的,实际调用的是Entry#getDirtyFile(int i)文件的输出流,这个dirty文件(带tmp后缀)生成是在调用Editor#newOutputStream(int index)时,在LruDiskCache中是在save()时生成:
/* DiskLruCache$Editor.java */
public OutputStream newOutputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
File dirtyFile = entry.getDirtyFile(index);
FileOutputStream outputStream;
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e) {
}
return new FaultHidingOutputStream(outputStream);
}删 - remove()
移除LRU缓存中的key对应的实体。这个方法一般不需要手动调用,因为会在调用DiskLruCache#close()、DiskLruCache#flush()或执行cleanupCallable任务(DiskLruCache#remove(String key)、DiskLruCache#get(String key)、DiskLruCache#commit()、DiskLruCache#abort()都有调用到)时都会自动调用trimToSize()和trimToFileCount()分别根据设置的最大size和最大数量来遍历LRU队列lruEntries前面的实体Entry。
对缓存部分的思考
看完了缓存部分的代码,我们可能还会有一些疑惑:
首先,磁盘缓存时文件名的生成是根据Uri还是[Uri][width][height],我们看到在ImageLoader中使用displayImage()加载图片时,直接判断的是MemoryCache,并没有判断DiskCache,而实际使用到DiskCache是在我们取不到MemoryCache时,就会去加载LoadAndDisplayImageTask任务,而这个任务构造方法传入的参数是Uri,所以磁盘加载是根据Uri生成的文件名。
还有,网络上下载的图片文件名可能会有一些非法字符,保存在磁盘的时候可能会异常,这个问题是怎么解决的呢?
/* BaseDiskCache.java */
protected File getFile(String imageUri) {
//根据fileNameGenerator规则生成imageUri文件名
String fileName = fileNameGenerator.generate(imageUri);
File dir = cacheDir;
if (!cacheDir.exists() && !cacheDir.mkdirs()) {
if (reserveCacheDir != null && (reserveCacheDir.exists() || reserveCacheDir.mkdirs())) {
dir = reserveCacheDir;
}
}
return new File(dir, fileName);
}通过取imageUri的hashcode或md5就能很好的解决这个问题。
最后一个问题,在分析框架的时候我们说通过配置ImageLoaderConfiguration$Builder的denyCacheImageMultipleSizesInMemory()就能来保证我们不同尺寸的图片只会有一份数据,而默认的不同尺寸的会有多份数据,这个是怎么做到的呢?
分析框架时我们就知道,内存中存放的key的格式为[imageUri]_[width]x[height],这里width和height是ImageAware的值,默认情况下,会产生多个尺寸的key。
但当设置了denyCache*()这个方法后,在build()的时候,MemoryCache默认会创建FuzzyKeyMemoryCache实例进行包装:
/* ImageLoaderConfiguration$Builder.java */
if (denyCacheImageMultipleSizesInMemory) {
memoryCache = new FuzzyKeyMemoryCache(memoryCache, MemoryCacheUtils.createFuzzyKeyComparator());
}第二个参数自定义的Comparator实际就是只对比key的Uri部分,如果两者Uri相同,则认为是同一个key。
这样,在我们put()的时候,如果发现Uri相同的,则删除之前的,在将新的key对应的Bitmap放入,就达到了一个Uri只对应一份数据的目的。
至此,我们已经分析完了ImageLoader中关于框架和缓存的全部。如果对这个项目还有疑问,可以留言讨论。