Python与机器学习(四)决策树
1.决策树概念:
决策树经常用于处理分类问题,也是最经常使用的数据挖掘算法。决策树的一个重要任务是为了数据中所蕴含的知识信息,并从中提取一系列的规则,而创建这些规则的过程就是机器学习的过程。例如一个典型例子就是根据天气情况分类星期天是否适合打球。
如果星期天的天气是晴天,温度很高,湿度很高,并且有很大的风,那么根据决策树的规则,这里是沿着最左侧的分支向下,最后判定为不打球。
决策树从名字上看就可以知道这是一个树形结构,将实例从根节点排列到某个叶子节点来分类实例,叶子节点即为实例所属的分类。分类过程从根节点开始,根据实例与节点对应属性的属性值判断下一步移动的方向,直至到达叶子节点。
2.决策树优缺点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据;
缺点:可能会产生过度匹配问题;
适用数据类型:数值型和标称型
3.决策树的一般流程:
1.收集数据:可以使用任何方法;
2.准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化;
3.分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预测;
4.训练算法:构造树的数据结构;
5.测试算法:使用经验树计算错误率;
6.使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
4.决策树算法
目前使用较为广泛的决策树算法是ID3算法和C4.5算法,这两种算法都是采用自顶向下的贪婪搜索遍历可能的决策树空间。
4.1 ID3算法
ID3算法是一种贪心算法,起源于概念学习系统,以信息熵的下降数度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。简单地说,ID3算法的核心问题是选取在树的每个节点要测试的属性,即应该选取哪些属性,选取的属性应该放在树中的哪个位置。这就涉及到划分数据集。
划分数据集的目的是使得数据从无序状态变成有序状态,例如上面提到的是否适合打球的例子,我们可以先根据天气划分,再根据湿度和风力划分,当然,也可以先根据风力划分,再根据天气和湿度划分。也就是说对于同一数据集有多种划分数据的方式,而每种方式所对应的预测结果可能是不一样的,那么究竟该如何选择最佳的划分方法?这里就有一个新的概念——信息增益。
信息增益(information gain)是划分数据集前后信息发生的变化,计算每个属性划分数据集后获得的信息增益,信息增益越大的属性就是最好的划分选择。在计算信息增益前,还需要了解一个概念——熵(entropy),熵是信息期望值,其公式为:
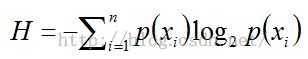
其中P(xi)是选择分类i的概率,n是所有分类属性的数目。
那么,一个属性A相对于数据集S的信息增益可表示为:
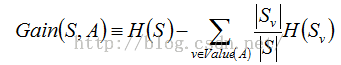
其中,Value(A)是属性A中所有可能值的集合,S(v)是集合S中属性A的值为v的子集。
下面我们用一个例子来熟悉信息增益的计算。数据集S是20个天气情况和打球与否的样本实例,其中打球有12个,不打球有8个,记作:S=[12+,8-];现在根据风力(即属性A)大小划分,风力大的子集中,打球有3个,不打球有6个,记作:S大=[3+,6-];风力小的子集中,打球有9个,不打球有2个,记作:S小=[9+,2-]。根据信息增益的计算公式:
计算出来的结果是0.18149632952867534
根据不同的属性划分可以得到不同的信息增益,然后按照信息增益最大的属性进行数据集划分,迭代这一过程,直至构造出一课完整的树(即该树能够完全分类样本实例,或所有属性都用到),且树种每个结点都是能够很好划分数据的属性。
4.2 C4.5算法
C4.5是基于ID3算法的改进,与ID3相比,C4.5使用信息增益率来选择属性,并对构造的决策树进行剪枝,防止过拟合,同时还能处理非离散数据和不完整数据。
信息增益率使用“分裂信息”值将信息增益规范化,分裂信息的计算公式为:
分裂信息表示通过将数据集S划分成对应于属性A的v个可能值的划分所产生的信息。
那么信息增益率就是:
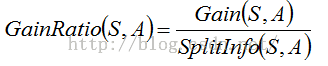
关于C4.5算法的详细介绍可以参看文章1和文章2
5.Python程序
5.1.计算给定数据集的香农熵
#trees.py
#计算给定数据集的香农熵
from math import log
def createDataSet():#创建数据集和标签集
dataSet = [[1,1,'maybe'],[1,0,'yes'],[1,1,'yes'],[0,1,'no'],[0,0,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
def calcShannonEnt(dataSet):#计算香农熵
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1] #读取当前实例类别
if currentLabel not in labelCounts.keys(): #将类别加入到字典中,并统计类别数目
labelCounts[currentLabel] = 0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts: #计算概率和熵
prob = float(labelCounts[key])/numEntries
shannonEnt -=prob*log(prob,2)
return shannonEnt
#test.py
#测试,计算香农熵
import trees
from math import log
myDat,labels = trees.createDataSet()
print(myDat)
shannonEnt=trees.calcShannonEnt(myDat)
print(shannonEnt)
输出结果为:
数据集:[[1, 1, 'yes'], [1, 0, 'yes'], [1, 1, 'yes'], [0, 1, 'no'], [0, 0, 'no']]
香农熵:0.9709505944546686
若将数据集中第一个实例的类别改为maybe,则结果为:
数据集:[[1, 1, 'maybe'], [1, 0, 'yes'], [1, 1, 'yes'], [0, 1, 'no'], [0, 0, 'no']]
香农熵:1.5219280948873621
由此可以看出,混合数据的类型越多,熵越高
5.2 绘制决策树
#treePlotter.py
#coding = utf-8
import matplotlib.pyplot as plt
from pylab import mpl
#matplotlib添加中文字体,注意每个要显示的汉字串前要添加U
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False #由于更改了字体导致显示不出负号,则将axes设置为false,默认的是true
#定义文本框和箭头格式
decisionNode = dict(boxstyle="sawtooth",fc="0.8")
leafNode = dict(boxstyle="round4",fc="0.8")
arrow_args = dict(arrowstyle="<-")
def plotNode(nodeTxt,centerPt,parentPt,nodeType): #绘制带箭头的注解
createPlot.ax1.annotate(nodeTxt,xy=parentPt,xycoords='axes fraction',\
xytext=centerPt,textcoords='axes fraction',\
va="center",ha="center",bbox=nodeType,arrowprops=arrow_args)
def createPlot(inTree):
fig = plt.figure(1,facecolor='white')
fig.clf()
createPlot.ax1 = plt.subplot(111,frameon=False)
plotNode(U'决策节点', (0.5,0.1), (0.1,0.5), decisionNode)
plotNode(U'叶节点',(0.8,0.1), (0.3,0.8), leafNode)
plt.show()
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0] #myTree.keys是dict_key类型,不支持索引取值,需要转换成list
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == "dict": #测试节点的数据类型是否为字典
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree): #获取树的层数
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == "dict": #测试节点的数据类型是否为字典
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth :
maxDepth = thisDepth
return maxDepth
def retrieveTree(i): #预定义树的结构
listOfTrees = [{'no surfacing': {0: 'no', 1: {'flippers':\
{0: 'no', 1: 'yes'}},3:'maybe'}},
{'no surfacing': {0: 'no', 1: {'flippers': \
{0: {'head': {0:'no', 1: 'yes'}},1:'no'}}}}
]
return listOfTrees[i]
def plotMidText(cntrPt,parentPt,txtString): #在父子节点间填充文本信息
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid,yMid,txtString)
def plotTree(myTree,parentPt,nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree) #计算宽与高
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff,plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt,str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#trees.py
'''
使用决策树的分类函数
'''
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
if testVec[featIndex] in secondDict.keys():
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
else:
print('测试数据输入有误!')
return 'no class'
return classLabel
'''
#使用pickle模块存储决策树
'''
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename,'rb')
return pickle.load(fr)
#test.py
#获取树的叶子树和深度
myDat,labels = trees.createDataSet()
myTree = treePlotter.retrieveTree(0)
#myLabels = labels
#myTree = trees.createTree(myDat, labels)
print('决策树叶子数:',treePlotter.getNumLeafs(myTree))
print('决策树深度:',treePlotter.getTreeDepth(myTree))
#使用决策树的分类函数
print('输入数据[1,1]的决策结果:',trees.classify(myTree, labels, [1,1]))
#存储和获取决策树
trees.storeTree(myTree, 'D:/classifierStorage.txt')
print(trees.grabTree('D:/classifierStorage.txt'))
#绘图
treePlotter.createPlot(myTree)
绘制的决策树:
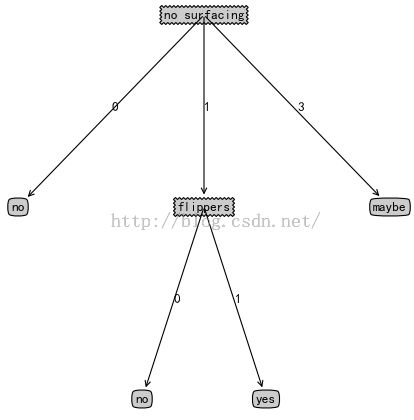
决策树叶子数: 4
决策树深度: 2
输入数据[1,1]的决策结果: yes
5.3 用决策树预测隐形眼镜类型
测试数据集在此下载
修改treePlotter.py中的createPlot函数:
def createPlot(inTree):
fig = plt.figure(1,facecolor='white')
fig.clf()
axprops = dict(xticks=[],yticks=[])
createPlot.ax1 = plt.subplot(111,frameon=False,**axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree,(0.5,1.0),'')
plt.show()
测试语句:
fr = open('D:/lenses.txt')
lenses = [inst.strip().split('\t')[1:] for inst in fr.readlines()]
print(lenses)
lensesLabels = ['age','prescript','astigmatic','tearRate']
labels = ['age','prescript','astigmatic','tearRate']
print('隐形眼镜标签集:',lensesLabels)
lensesTree = trees.createTree(lenses, labels)
print('隐形眼镜标签集:',labels,lensesLabels)
print('隐形眼镜数据集:',lenses)
print('隐形眼镜决策树:',lensesTree)
treePlotter.createPlot(lensesTree)
print(trees.classify(lensesTree, lensesLabels, ['1','1','1','2']))
测试结果:
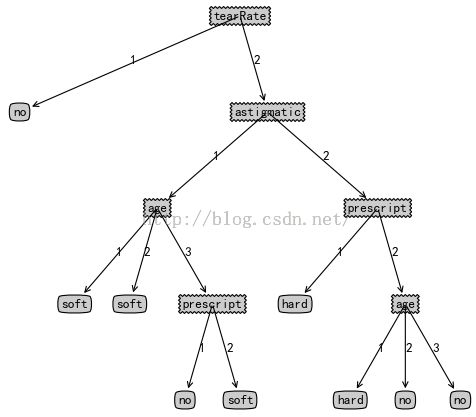
输入数据[1,1,1,2]的决策: soft