Clustered Index & Non Clustered Index
聚簇索引和非聚簇索引都是为了增加数据检索速度而存在的.
在配置上, 每个表只能有一个聚簇索引,而能有200多个非聚簇索引。
在物理分配上, 每个表的数据都是分配在页上,一个页大概有8k左右,假设一条数据占1000字节的话,那么8000条数据占8000*1k/8k = 1000页面,这些数据存在于数据块中。
如果对这些数据中的某一10字节的字段做聚簇索引的话,8000 * 0.01K /8 = 10 页面,那么10页面作为存储这些索引而存在。并存放于索引块
如果对这些数据中的某一10字节的字段做非聚簇索引的话,2 * 8000 * 0.01K /8 = 20 页面,那么20页面作为存储这些索引而存在。并存放于索引块。乘2 的原因请看以下叙述。
在功能上, 聚簇索引后,数据按照索引的顺序来排序,所以索引所指向的就是数据层里对应的相关数据。
非聚簇索引后,数据不会按照索引的顺序来排序,所以数据库会先按字理或逻辑先生成首层索引, 再根据首层索引生成第二层索引,第二层索引
所指向的才是数据层里对应的相关数据。
在性能上, 聚簇索引在大多数的情况下对该索引的查询操作性能是最好的,查询先通过索引层(按上述的例子中,最多需要搜索10页)找到对应数据存在位置,就算是多条符合记录的数据,也是在旁边的数据位置中就能找到
非聚簇索引在大多数的情况下对该索引的查询操作性能比聚簇索引稍次,查询也先通过首层索引(按上述的例子中,最多搜索10页)找到对应第二层索引存在位置,由第二层索引层再找到数据的物理位置。
索引虽然可以增加查询速度,但也有以下缺陷,需要在设置时注意
1. 占用空间,虽然索引块增长速度不如数据块那么急剧,但毕竟也是消耗空间的。
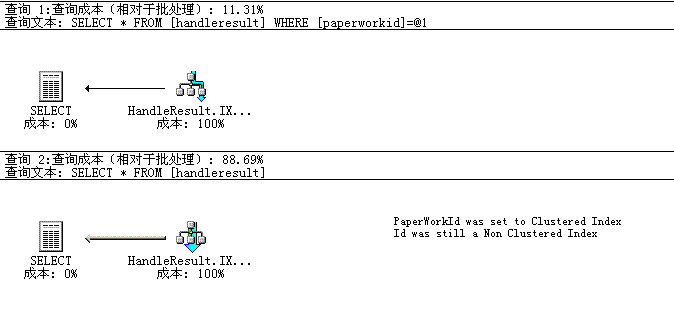
2. 在select * 的访问语句时, 数据库会先搜索聚簇和非聚簇索引的索引块的索引,再搜索数据块,这种情况下表里完全不设索引的性能高于设了聚簇索引的性能(按上例要额外搜索10个页),设了聚簇的性能比设非聚簇的要好(按上例非聚簇要额外搜索20个页)