Spark MLlib Logistic Regression逻辑回归算法
1.1 逻辑回归算法
1.1.1 基础理论
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0和1上。
它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响。
Logistic函数(或称为Sigmoid函数),函数形式为:
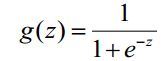
Sigmoid 函数在有个很漂亮的“S”形,如下图所示:

给定n个特征x=(x1,x2,…,xn),设条件概率P(y=1|x)为观测样本y相对于事件因素x发生的概率,用sigmoid函数表示为:

那么在x条件下y不发生的概率为:
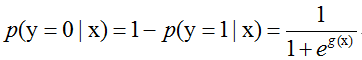
假设现在有m个相互独立的观测事件y=(y1,y2,…,ym),则一个事件yi发生的概率为(yi= 1)
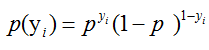
当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):
然后我们的目标是求出使这一似然函数的值最大的参数估计,最大似然估计就是求出参数,使得![]()
取得最大值,对函数取对数得到![]()
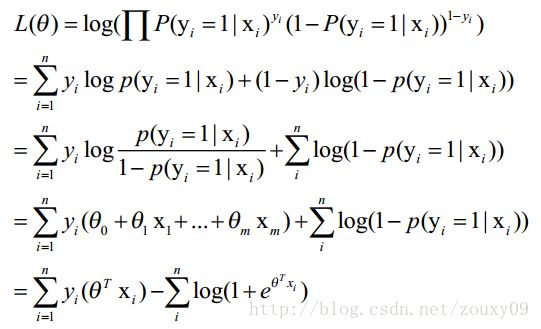
这时候,用L(θ)对θ求导,得到:
1.1.2 梯度下降算法
θ更新过程:
θ更新过程可以写成:
向量化Vectorization
Vectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。
如上式,Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization。
下面介绍向量化的过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知![]() 可由一次计算求得。
可由一次计算求得。
θ更新过程可以改为:
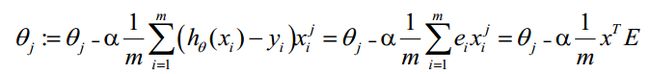
综上所述,Vectorization后θ更新的步骤如下:
(1)求![]() ;
;
(2)求;
(3)求![]() 。
。
1.1.3 正则化
在实际应该过程中,为了增强模型的泛化能力,防止我们训练的模型过拟合,特别是对于大量的稀疏特征,模型复杂度比较高,需要进行降维,我们需要保证在训练误差最小化的基础上,通过加上正则化项减小模型复杂度。在逻辑回归中,有L1、L2进行正则化。
损失函数如下:
在损失函数里加入一个正则化项,正则化项就是权重的L1或者L2范数乘以一个,用来控制损失函数和正则化项的比重,直观的理解,首先防止过拟合的目的就是防止最后训练出来的模型过分的依赖某一个特征,当最小化损失函数的时候,某一维度很大,拟合出来的函数值与真实的值之间的差距很小,通过正则化可以使整体的cost变大,从而避免了过分依赖某一维度的结果。当然加正则化的前提是特征值要进行归一化。
对于线性回归

Regularized Logistic Regression 实际上与 Regularized Linear Regression 是十分相似的。
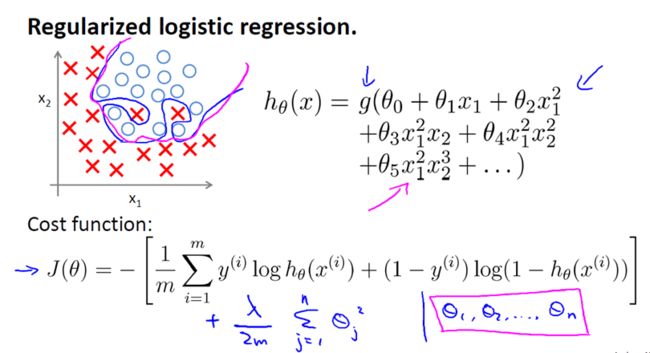
同样使用梯度下降:

1.2 Spark Mllib Logistic Regression源码分析
1.2.1 LogisticRegressionWithSGD
Logistic回归算法的train方法,由LogisticRegressionWithSGD类的object定义了train函数,在train函数中新建了LogisticRegressionWithSGD对象。
package org.apache.spark.mllib.classification
// 1 类:LogisticRegressionWithSGD
class LogisticRegressionWithSGD private[mllib] (
privatevar stepSize: Double,
privatevar numIterations: Int,
privatevar regParam: Double,
privatevar miniBatchFraction: Double)
extends GeneralizedLinearAlgorithm[LogisticRegressionModel] with Serializable {
privateval gradient = new LogisticGradient()
privateval updater = new SquaredL2Updater()
overrideval optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)
overrideprotectedval validators = List(DataValidators.binaryLabelValidator)
/**
* Construct a LogisticRegression object with default parameters: {stepSize: 1.0,
* numIterations: 100, regParm: 0.01, miniBatchFraction: 1.0}.
*/
defthis() = this(1.0, 100, 0.01, 1.0)
overrideprotected[mllib] def createModel(weights: Vector, intercept: Double) = {
new LogisticRegressionModel(weights, intercept)
}
LogisticRegressionWithSGD类中参数说明:
stepSize: 迭代步长,默认为1.0
numIterations: 迭代次数,默认为100
regParam: 正则化参数,默认值为0.0
miniBatchFraction: 每次迭代参与计算的样本比例,默认为1.0
gradient:LogisticGradient(),Logistic梯度下降;
updater:SquaredL2Updater(),正则化,L2范数;
optimizer:GradientDescent(gradient, updater),梯度下降最优化计算。
// 2 train方法
object LogisticRegressionWithSGD {
/**
* Train a logistic regression model given an RDD of (label, features) pairs. We run a fixed
* number of iterations of gradient descent using the specified step size. Each iteration uses
* `miniBatchFraction` fraction of the data to calculate the gradient. The weights used in
* gradient descent are initialized using the initial weights provided.
* NOTE: Labels used in Logistic Regression should be {0, 1}
*
* @param input RDD of (label, array of features) pairs.
* @param numIterations Number of iterations of gradient descent to run.
* @param stepSize Step size to be used for each iteration of gradient descent.
* @param miniBatchFraction Fraction of data to be used per iteration.
* @param initialWeights Initial set of weights to be used. Array should be equal in size to
* the number of features in the data.
*/
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
miniBatchFraction: Double,
initialWeights: Vector): LogisticRegressionModel = {
new LogisticRegressionWithSGD(stepSize, numIterations, 0.0, miniBatchFraction)
.run(input, initialWeights)
}
}
train参数说明:
input:样本数据,分类标签lable只能是1.0和0.0两种,feature为double类型
numIterations: 迭代次数,默认为100
stepSize: 迭代步长,默认为1.0
miniBatchFraction: 每次迭代参与计算的样本比例,默认为1.0
initialWeights:初始权重,默认为0向量
run方法来自于继承父类GeneralizedLinearAlgorithm,实现方法如下。
1.2.2 GeneralizedLinearAlgorithm
LogisticRegressionWithSGD中run方法的实现。
package org.apache.spark.mllib.regression
/**
* Run the algorithm with the configured parameters on an input RDD
* of LabeledPoint entries starting from the initial weights provided.
*/
def run(input: RDD[LabeledPoint], initialWeights: Vector): M = {
// 特征维度赋值。
if (numFeatures < 0) {
numFeatures = input.map(_.features.size).first()
}
// 输入样本数据检测。
if (input.getStorageLevel == StorageLevel.NONE) {
logWarning("The input data is not directly cached, which may hurt performance if its"
+ " parent RDDs are also uncached.")
}
// 输入样本数据检测。
// Check the data properties before running the optimizer
if (validateData && !validators.forall(func => func(input))) {
thrownew SparkException("Input validation failed.")
}
val scaler = if (useFeatureScaling) {
new StandardScaler(withStd = true, withMean = false).fit(input.map(_.features))
} else {
null
}
// 输入样本数据处理,输出data(label, features)格式。
// addIntercept:是否增加θ0常数项,若增加,则增加x0=1项。
// Prepend an extra variable consisting of all 1.0's for the intercept.
// TODO: Apply feature scaling to the weight vector instead of input data.
val data =
if (addIntercept) {
if (useFeatureScaling) {
input.map(lp => (lp.label, appendBias(scaler.transform(lp.features)))).cache()
} else {
input.map(lp => (lp.label, appendBias(lp.features))).cache()
}
} else {
if (useFeatureScaling) {
input.map(lp => (lp.label, scaler.transform(lp.features))).cache()
} else {
input.map(lp => (lp.label, lp.features))
}
}
//初始化权重。
// addIntercept:是否增加θ0常数项,若增加,则权重增加θ0。
/**
* TODO: For better convergence, in logistic regression, the intercepts should be computed
* from the prior probability distribution of the outcomes; for linear regression,
* the intercept should be set as the average of response.
*/
val initialWeightsWithIntercept = if (addIntercept && numOfLinearPredictor == 1) {
appendBias(initialWeights)
} else {
/** If `numOfLinearPredictor > 1`, initialWeights already contains intercepts. */
initialWeights
}
//权重优化,进行梯度下降学习,返回最优权重。
val weightsWithIntercept = optimizer.optimize(data, initialWeightsWithIntercept)
val intercept = if (addIntercept && numOfLinearPredictor == 1) {
weightsWithIntercept(weightsWithIntercept.size - 1)
} else {
0.0
}
var weights = if (addIntercept && numOfLinearPredictor == 1) {
Vectors.dense(weightsWithIntercept.toArray.slice(0, weightsWithIntercept.size - 1))
} else {
weightsWithIntercept
}
createModel(weights, intercept)
}
其中optimizer.optimize(data, initialWeightsWithIntercept)是逻辑回归实现的核心。
oprimizer的类型为GradientDescent,optimize方法中主要调用GradientDescent伴生对象的runMiniBatchSGD方法,返回当前迭代产生的最优特征权重向量。
GradientDescentd对象中optimize实现方法如下。
1.2.3 GradientDescent
optimize实现方法如下。
package org.apache.spark.mllib.optimization
/**
* :: DeveloperApi ::
* Runs gradient descent on the given training data.
* @param data training data
* @param initialWeights initial weights
* @return solution vector
*/
@DeveloperApi
def optimize(data: RDD[(Double, Vector)], initialWeights: Vector): Vector = {
val (weights, _) = GradientDescent.runMiniBatchSGD(
data,
gradient,
updater,
stepSize,
numIterations,
regParam,
miniBatchFraction,
initialWeights)
weights
}
}
在optimize方法中,调用了GradientDescent.runMiniBatchSGD方法,其runMiniBatchSGD实现方法如下:
/**
* Run stochastic gradient descent (SGD) in parallel using mini batches.
* In each iteration, we sample a subset (fraction miniBatchFraction) of the total data
* in order to compute a gradient estimate.
* Sampling, and averaging the subgradients over this subset is performed using one standard
* spark map-reduce in each iteration.
*
* @param data - Input data for SGD. RDD of the set of data examples, each of
* the form (label, [feature values]).
* @param gradient - Gradient object (used to compute the gradient of the loss function of
* one single data example)
* @param updater - Updater function to actually perform a gradient step in a given direction.
* @param stepSize - initial step size for the first step
* @param numIterations - number of iterations that SGD should be run.
* @param regParam - regularization parameter
* @param miniBatchFraction - fraction of the input data set that should be used for
* one iteration of SGD. Default value 1.0.
*
* @return A tuple containing two elements. The first element is a column matrix containing
* weights for every feature, and the second element is an array containing the
* stochastic loss computed for every iteration.
*/
def runMiniBatchSGD(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
stepSize: Double,
numIterations: Int,
regParam: Double,
miniBatchFraction: Double,
initialWeights: Vector): (Vector, Array[Double]) = {
//历史迭代误差数组
val stochasticLossHistory = new ArrayBuffer[Double](numIterations)
//样本数据检测,若为空,返回初始值。
val numExamples = data.count()
// if no data, return initial weights to avoid NaNs
if (numExamples == 0) {
logWarning("GradientDescent.runMiniBatchSGD returning initial weights, no data found")
return (initialWeights, stochasticLossHistory.toArray)
}
// miniBatchFraction值检测。
if (numExamples * miniBatchFraction < 1) {
logWarning("The miniBatchFraction is too small")
}
// weights权重初始化。
// Initialize weights as a column vector
var weights = Vectors.dense(initialWeights.toArray)
val n = weights.size
/**
* For the first iteration, the regVal will be initialized as sum of weight squares
* if it's L2 updater; for L1 updater, the same logic is followed.
*/
var regVal = updater.compute(
weights, Vectors.dense(new Array[Double](weights.size)), 0, 1, regParam)._2
// weights权重迭代计算。
for (i <- 1 to numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
// 采用treeAggregate的RDD方法,进行聚合计算,计算每个样本的权重向量、误差值,然后对所有样本权重向量及误差值进行累加。
// sample是根据miniBatchFraction指定的比例随机采样相应数量的样本 。
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
// 保存本次迭代误差值,以及更新weights权重向量。
if (miniBatchSize > 0) {
/**
* NOTE(Xinghao): lossSum is computed using the weights from the previous iteration
* and regVal is the regularization value computed in the previous iteration as well.
*/
// updater.compute更新weights矩阵和regVal(正则化项)。根据本轮迭代中的gradient和loss的变化以及正则化项计算更新之后的weights和regVal。
stochasticLossHistory.append(lossSum / miniBatchSize + regVal)
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble), stepSize, i, regParam)
weights = update._1
regVal = update._2
} else {
logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero")
}
}
logInfo("GradientDescent.runMiniBatchSGD finished. Last 10 stochastic losses %s".format(
stochasticLossHistory.takeRight(10).mkString(", ")))
(weights, stochasticLossHistory.toArray)
}
runMiniBatchSGD的输入、输出参数说明:
data 样本输入数据,格式 (label, [feature values])
gradient 梯度对象,用于对每个样本计算梯度及误差
updater 权重更新对象,用于每次更新权重
stepSize 初始步长
numIterations 迭代次数
regParam 正则化参数
miniBatchFraction 迭代因子,每次迭代参与计算的样本比例
返回结果(Vector, Array[Double]),第一个为权重,每二个为每次迭代的误差值。
在MiniBatchSGD中主要实现对输入数据集进行迭代抽样,通过使用LogisticGradient作为梯度下降算法,使用SquaredL2Updater作为更新算法,不断对抽样数据集进行迭代计算从而找出最优的特征权重向量解。在LinearRegressionWithSGD中定义如下:
privateval gradient = new LogisticGradient()
privateval updater = new SquaredL2Updater()
overrideval optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)
runMiniBatchSGD方法中调用了gradient.compute、updater.compute两个方法,其实现方法如下。
1.2.4 gradient & updater
1)gradient
//计算当前计算对象的类标签与实际类标签值之差
//计算当前平方梯度下降值
//计算权重的更新值
//返回当前训练对象的特征权重向量和误差
class LogisticGradient(numClasses: Int) extends Gradient {
defthis() = this(2)
overridedef compute(data: Vector, label: Double, weights: Vector): (Vector, Double) = {
val gradient = Vectors.zeros(weights.size)
val loss = compute(data, label, weights, gradient)
(gradient, loss)
}
overridedef compute(
data: Vector,
label: Double,
weights: Vector,
cumGradient: Vector): Double = {
val dataSize = data.size
// (weights.size / dataSize + 1) is number of classes
require(weights.size % dataSize == 0 && numClasses == weights.size / dataSize + 1)
numClasses match {
case2 =>
/**
* For Binary Logistic Regression.
*
* Although the loss and gradient calculation for multinomial one is more generalized,
* and multinomial one can also be used in binary case, we still implement a specialized
* binary version for performance reason.
*/
val margin = -1.0 * dot(data, weights)
val multiplier = (1.0 / (1.0 + math.exp(margin))) - label
axpy(multiplier, data, cumGradient)
if (label > 0) {
// The following is equivalent to log(1 + exp(margin)) but more numerically stable.
MLUtils.log1pExp(margin)
} else {
MLUtils.log1pExp(margin) - margin
}
case _ =>
/**
* For Multinomial Logistic Regression.
*/
val weightsArray = weights match {
case dv: DenseVector => dv.values
case _ =>
thrownew IllegalArgumentException(
s"weights only supports dense vector but got type ${weights.getClass}.")
}
val cumGradientArray = cumGradient match {
case dv: DenseVector => dv.values
case _ =>
thrownew IllegalArgumentException(
s"cumGradient only supports dense vector but got type ${cumGradient.getClass}.")
}
// marginY is margins(label - 1) in the formula.
var marginY = 0.0
var maxMargin = Double.NegativeInfinity
var maxMarginIndex = 0
val margins = Array.tabulate(numClasses - 1) { i =>
var margin = 0.0
data.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataSize) + index)
}
if (i == label.toInt - 1) marginY = margin
if (margin > maxMargin) {
maxMargin = margin
maxMarginIndex = i
}
margin
}
/**
* When maxMargin > 0, the original formula will cause overflow as we discuss
* in the previous comment.
* We address this by subtracting maxMargin from all the margins, so it's guaranteed
* that all of the new margins will be smaller than zero to prevent arithmetic overflow.
*/
val sum = {
var temp = 0.0
if (maxMargin > 0) {
for (i <- 0 until numClasses - 1) {
margins(i) -= maxMargin
if (i == maxMarginIndex) {
temp += math.exp(-maxMargin)
} else {
temp += math.exp(margins(i))
}
}
} else {
for (i <- 0 until numClasses - 1) {
temp += math.exp(margins(i))
}
}
temp
}
for (i <- 0 until numClasses - 1) {
val multiplier = math.exp(margins(i)) / (sum + 1.0) - {
if (label != 0.0 && label == i + 1) 1.0else0.0
}
data.foreachActive { (index, value) =>
if (value != 0.0) cumGradientArray(i * dataSize + index) += multiplier * value
}
}
val loss = if (label > 0.0) math.log1p(sum) - marginY else math.log1p(sum)
if (maxMargin > 0) {
loss + maxMargin
} else {
loss
}
}
}
}
2)updater
//weihtsOld:上一次迭代计算后的特征权重向量
//gradient:本次迭代计算的特征权重向量
//stepSize:迭代步长
//iter:当前迭代次数
//regParam:正则参数
//以当前迭代次数的平方根的倒数作为本次迭代趋近(下降)的因子
//返回本次剃度下降后更新的特征权重向量
//使用了L2 regularization(R(w) = 1/2 ||w||^2),weights更新规则为:
![]()
/**
* :: DeveloperApi ::
* Updater for L2 regularized problems.
* R(w) = 1/2 ||w||^2
* Uses a step-size decreasing with the square root of the number of iterations.
*/
@DeveloperApi
class SquaredL2Updater extends Updater {
overridedef compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
// add up both updates from the gradient of the loss (= step) as well as
// the gradient of the regularizer (= regParam * weightsOld)
// w' = w - thisIterStepSize * (gradient + regParam * w)
// w' = (1 - thisIterStepSize * regParam) * w - thisIterStepSize * gradient
val thisIterStepSize = stepSize / math.sqrt(iter)
val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVector
brzWeights :*= (1.0 - thisIterStepSize * regParam)
brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights)
val norm = brzNorm(brzWeights, 2.0)
(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)
}
}
1.3 Mllib Logistic Regression实例
1、数据
数据格式为:标签, 特征1 特征2 特征3……
0 128:51 129:159 130:253 131:159 132:50 155:48 156:238 157:252 158:252 159:252 160:237 182:54 183:227 184:253 185:252 186:239 187:233 188:252 189:57 190:6 208:10 209:60 210:224 211:252 212:253 213:252 214:202 215:84 216:252 217:253 218:122 236:163 237:252 238:252 239:252 240:253 241:252 242:252 243:96 244:189 245:253 246:167 263:51 264:238 265:253 266:253 267:190 268:114 269:253 270:228 271:47 272:79 273:255 274:168 290:48 291:238 292:252 293:252 294:179 295:12 296:75 297:121 298:21 301:253 302:243 303:50 317:38 318:165 319:253 320:233 321:208 322:84 329:253 330:252 331:165 344:7 345:178 346:252 347:240 348:71 349:19 350:28 357:253 358:252 359:195 372:57 373:252 374:252 375:63 385:253 386:252 387:195 400:198 401:253 402:190 413:255 414:253 415:196 427:76 428:246 429:252 430:112 441:253 442:252 443:148 455:85 456:252 457:230 458:25 467:7 468:135 469:253 470:186 471:12 483:85 484:252 485:223 494:7 495:131 496:252 497:225 498:71 511:85 512:252 513:145 521:48 522:165 523:252 524:173 539:86 540:253 541:225 548:114 549:238 550:253 551:162 567:85 568:252 569:249 570:146 571:48 572:29 573:85 574:178 575:225 576:253 577:223 578:167 579:56 595:85 596:252 597:252 598:252 599:229 600:215 601:252 602:252 603:252 604:196 605:130 623:28 624:199 625:252 626:252 627:253 628:252 629:252 630:233 631:145 652:25 653:128 654:252 655:253 656:252 657:141 658:37
1 159:124 160:253 161:255 162:63 186:96 187:244 188:251 189:253 190:62 214:127 215:251 216:251 217:253 218:62 241:68 242:236 243:251 244:211 245:31 246:8 268:60 269:228 270:251 271:251 272:94 296:155 297:253 298:253 299:189 323:20 324:253 325:251 326:235 327:66 350:32 351:205 352:253 353:251 354:126 378:104 379:251 380:253 381:184 382:15 405:80 406:240 407:251 408:193 409:23 432:32 433:253 434:253 435:253 436:159 460:151 461:251 462:251 463:251 464:39 487:48 488:221 489:251 490:251 491:172 515:234 516:251 517:251 518:196 519:12 543:253 544:251 545:251 546:89 570:159 571:255 572:253 573:253 574:31 597:48 598:228 599:253 600:247 601:140 602:8 625:64 626:251 627:253 628:220 653:64 654:251 655:253 656:220 681:24 682:193 683:253 684:220
……
2、代码
//1 读取样本数据
valdata_path = "/user/tmp/sample_libsvm_data.txt"
valexamples = MLUtils.loadLibSVMFile(sc, data_path).cache()
//2 样本数据划分训练样本与测试样本
valsplits = examples.randomSplit(Array(0.6, 0.4), seed = 11L)
valtraining = splits(0).cache()
valtest = splits(1)
valnumTraining = training.count()
valnumTest = test.count()
println(s"Training: $numTraining, test: $numTest.")
//3 新建逻辑回归模型,并设置训练参数
valnumIterations = 1000
valstepSize = 1
valminiBatchFraction = 1.0
valmodel = LogisticRegressionWithSGD.train(training, numIterations, stepSize, miniBatchFraction)
//4 对测试样本进行测试
valprediction = model.predict(test.map(_.features))
valpredictionAndLabel = prediction.zip(test.map(_.label))
//5 计算测试误差
valmetrics = new MulticlassMetrics(predictionAndLabel)
valprecision = metrics.precision
println("Precision = " + precision)