mysql数据记录基本操作(对数据的增删查改)
关于cmd中输入中文,可以在cmd中输入chcp查看当前使用的是那种语言的,最常用的就是65001和936,65001设置编码显示为utf8格式,936是简体中文的代码。为了可以在cmd中输入中文可以在cmd中输入chcp 936
1、mysql对数据的查询
1.1 、 select基本语法
select语句的使用非常广泛,也可以用来检索不引用任何表的计算行,例如直接用select计算两个整数的和:
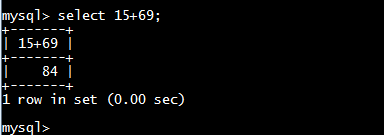
在mysql中使用select的基本语法:
select [straight_join] [sql_small_result] [sql_big_result]
[high_priority]
[distinct | distinctrow | all]
select_expression, ……
[into {outfile | dumpfile} ‘file_name’ export_options]
[from table_references
[where where_definition]
[group by col_name, …]
[having where_definition]
[order by {unsigned_integer | col_name | formula} [asc | desc] , …]
[limit [offset,] rows]
[procedure procedure_name] ]
其中select_expression表示需要查询的字段名,table_references表示从此处指定的表或视图中查询数据,where where_definition表示指定查询条件,col_name表示按照指定的字段进行分组,having where_definition表示满足这个条件的表达式才能输出,order by按照指定的字段排序,asc为顺序,desc为逆序,procedure procedure_name表示指定的存储过程名称。
注:使用select语句,所有要使用的关键字必须精确地按照上面的顺序指定,否则会出错。
1.2、单表查询
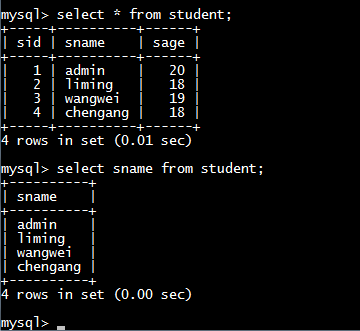
1.2.1、查询所有字段或部分字段
查询指定字段:
select 查询字段1,查询字段2,……from table_name;
查询所有字段:
select * from table_name;
*代表所有字段,也可以在select后边列出所有的字段,但是比较麻烦。
1.2.2、根据条件查询
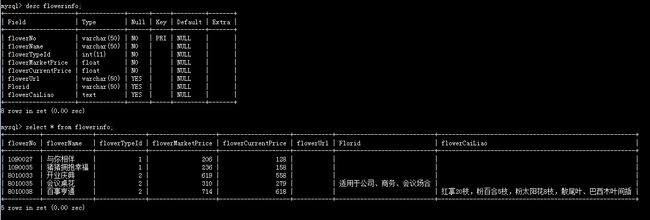
先创建一张表,并添加了一些数据:
大多数情况下,需要按照条件完成查询:
select 查询字段 from table_name where 条件表达式;
在比较条件中<>表示不等于,等价于!= , between add 用法为:
where 字段名 [not] between 取值1 add 取值2;
between add 的取值范围是大于等于“取值1”小于等于“取值2”,not between add的取值范围与between add相反。

这里选择double类型的字段flowerMarketPrice的取值范围为[200,310]
in的用法:
[not] in (元素1、元素2、元素3, … , 元素n)
in可以判断某个字段的值是否在指定的集合中。

这里选择float类型字段flowerCurrentPrice的值在集合[128,558,618,999]中的数据。
and 和or 的用法:
条件表达式1 and/or 条件表达式2 [… and/or 条件表达式n];
and 和 or 都用来联合多个查询条件,and为交集,or为并集。
like的用法:
like用来判断是否与指定的字符串匹配: [not] like ‘字符串’;
‘字符串’必须添加单引号或者引号,字符串的参数值可以是一个完整的字符串,也可以是包含百分比或者下划线的统配字符。
- 百分比(%):代表任意长度的字符串,长度可以为0。如:a%n表示以字母a开头,以字母n结束的任意长度的字符串。
- 下划线(_):只能代表单个字符。如:a_n表示以a开头n结尾的三个字符。
这里对varchar类型的字段flowerNo值,选择里边包含有字母3的数据。‘%3’为以3结尾,’3%’为以3开头,’%3%’为字符串中包含有3
1.2.3、分组查询
可以通过group by实现分组查询,将查询的结果按照某个字段或者多个字段进行分组,指定字段值相同的为一组:
group by 字段名 [having 条件表达式] [with rollup]
字段名是多个的时候中间用逗号分隔。“having条件表达式”和with rollup都是可选的,满足having条件表达式的将会被显示出来,with rollup会在所有记录的最后加上一条,该记录是上面所有记录的总和。

按照int类型字段flowerTypeId值group by
1.2.4、having查询
一般情况下having语句和group by一起使用,可以限制查询结果显示的情况,和where条件查询类似。但是where作用于表或者视图,having作用于分组后的记录,用于选择满足条件的分组。

分组后选择flowerMarketPrice大于等于300的。
1.2.5、排序查询
数据库中查询出来的语句可能是无序的,或者排列顺序不是我们所期望的,通常需要按照某个字段来排序,这就用到排序了:
order by 字段名 [asc | desc]
asc:顺序(由小到大) desc:逆序(由大到小)
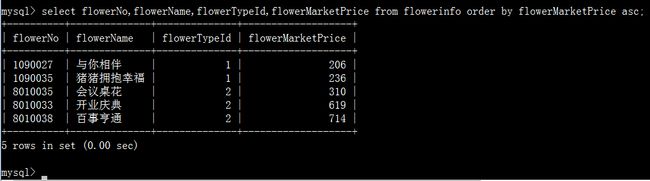
按照flowerMarketPrice值顺序排列。
1.2.6、limit限制查询数量
limit可以指定查询结果从哪条记录开始,也可指定显示多少条数据。
limit [初始位置,] 查询记录数量
“初始位置”指定从哪条记录开始显示,从0开始。如果是从第一条记录开始显示,则初始位置为1。

按照flowerMarketPrice顺序排序后,查询第3、4两条数据(从第2+1条数据开始查询,查询两条)。
1.2.7、其它查询
- 避免重复查询
如果没有给数据库表中的字段添加唯一性或逐渐约束,这些字段就会有可能存在着重复的值。mysql可以指定distinct关键字来消除重复记录:
select distinct 字段名 - 查询集合函数
集合函数是mysql中自带函数,可以直接拿来使用。mysql中常用的集合函数包括cout()、avg()、sum()、max()、min()。
count():用来统计记录的总条数。
查询表中总共有多少条记录:
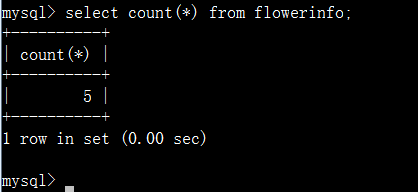
查询表中字段值的记录数:
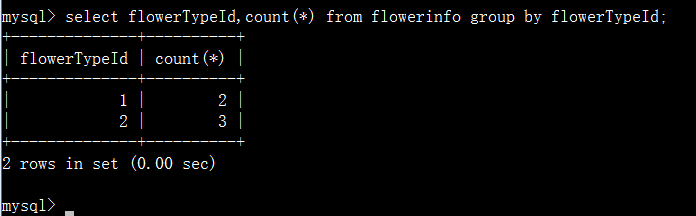
可以看待flowerTypeId值为1的有两条数据,值为2的有三条数据。
avg():求平均数,使用该函数可以求出表中某个字段取值的平均值。
直接计算flowerMarketPrice的平均值:
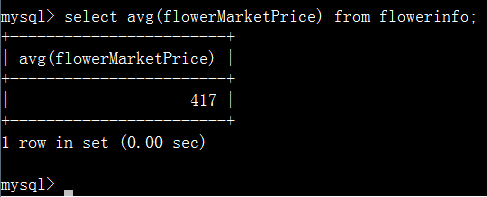
按照flowerTypeId分组后计算每组的平均值:
sum():计算表中某个字段的总和。
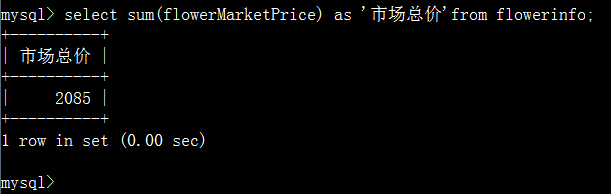
max()和min():求出某个字段的最大值和最小值。
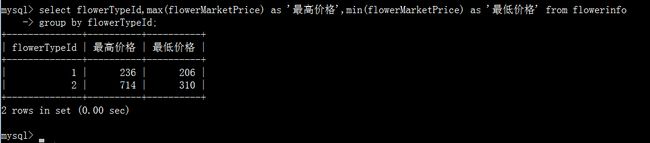
这里按照flowerTypeId分组后计算每组的最大最小值。
1.3、多表查询
1.3.1、内连接查询
- 使用inner join on 查询
最常用的就是两个表的查询:
select 字段名列表 from 表名1 inner join 表名2 on 表名1.字段名=表名2.字段名
一般情况下,会省略inner关键字。上述代码等价于一下代码:
select 字段名列表 from 表名1 join 表名2 on 表名1.字段名=表名2.字段名 - 在from之后查询
基本语法:
select 字段名列表 from 表1, 表2 where 表1.字段名=表2.字段名
为表重新制定名称时可以使用一下语法:
select a.字段1,b.字段1 from 表1 as a, 表2 as b where a.字段名=b.字段名
1.3.2、外连接查询
外连接查询可以查询两个或两个以上的表,与内连接查询相似,当该字段值相等的时,可以查询出该表的记录;此外该字段值不相等的记录也可以查询出来。分为左外连接查询和右外连接查询,通过outer join关键字实现:
select 字段表 from 表1 left|right [outer] join 表2 on 表1.字段=表2.字段
上述代码等价于以下代码:
select a.字段1,b.字段1 from 表1 as a left|right [outer] join 表2 as b on a.字段=b.字段
- 左外连接查询
左外连接查询可以查询出“表1”所指的表中的所有记录,而“表2”所指表中只能查询出匹配的记录。 - 右外连接查询
右外连接查询可以查询出“表2”所指的表中的所有记录,“表1”所指的表中只能查询出匹配的记录。
1.4、子查询
子查询是将一个查询语句嵌套在另一个查询语句中,内层查询语句的结果可为外层查询语句提供查询条件。可实现多个表之间的查询。
子查询中可以包括in、not in、exists、not exists、any和all关键字,也可以通过比较运算符(如=、!=、>=、<=等)进行查询。
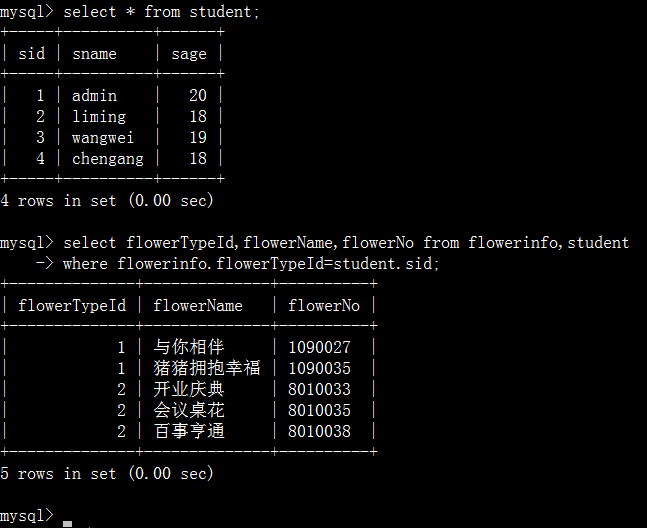
1.4.1、通过比较运算符查询

这里是在student表中找到sname为‘liming’的sid,找出flowerinfo表中flowerTypeId和sid相等的数据。
1.4.2、通过in查询
一个查询语句的条件可能落在另一个select语句的查询结果中,这时可以通过in关键字进行判断。
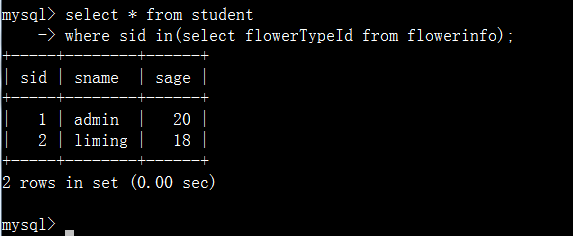
查询出了student表中sid与flowerinfo表中flowerTypeId相等的数据。
1.4.3、通过exists查询
使用exists关键字时,内层查询语句不反悔查询的记录,返回一个真假值,内层返回真值,外层查询语句将会进行查询,而内层查询返回假值时,外层查询语句不进行查询或者查询不出来任何记录。

1.4.4、通过all和any查询
all关键字表示满足所有条件,使用该关键字时,只有满足内层查询语句返回的所有结果,才能执行外层查询语句。
一般all会和比较运算符一起使用,如: >=all表示大于等于所有值。
这里查询student表中sid>=flowerinfo表中所有flowerTypeId的值。
1.5、正则表达式查询
关于正则表达式可以在这个网站学习,里边还有一个校验器:
http://www.jb51.net/tools/zhengze.html
mysql中使用正则表达式查询使用regexp关键字:
字段名 regexp “匹配方式”;
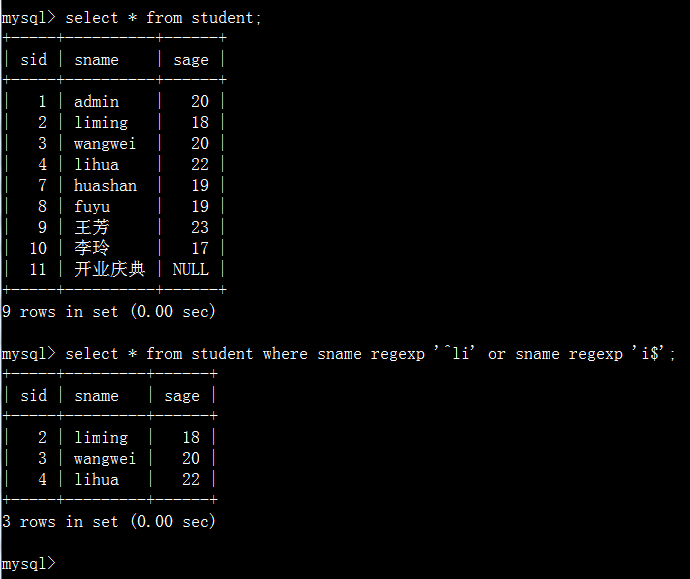
从student表中选择出sname以“li”开头或者以“i”结尾的数据。
2、添加数据
2.1、插入单条数据
语法:
insert into 表名[(字段名列表)] values(字段值1,字段值2,…,字段值n)
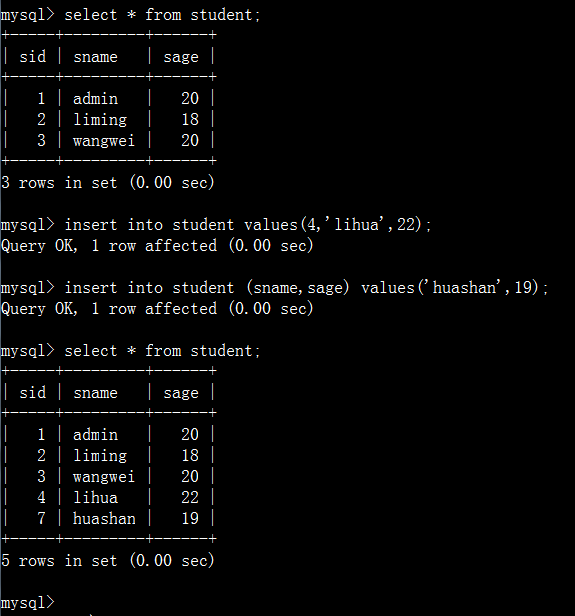
2.2、插入多条数据
语法:
insert into 表名 [(字段名列表)] values(取值1),(取值2),…,(取值n);
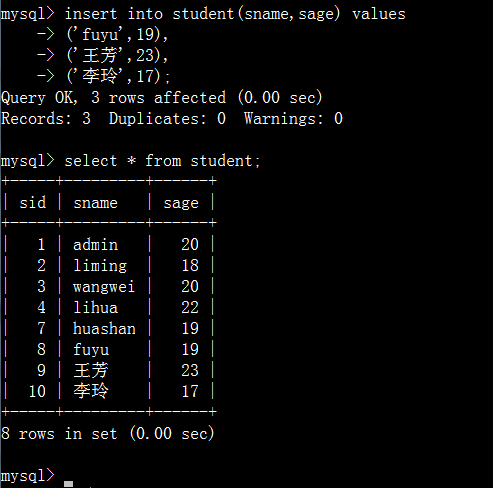
2.3、将A表数据插入B表
语法:
insert into 表名1(字段名列表) select 字段名列表2 from 表名2 where 条件表达式;
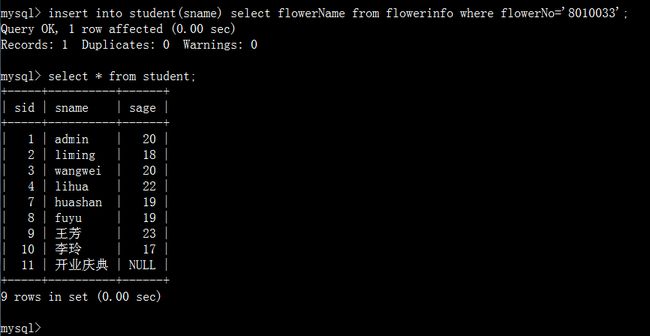
3、更新数据
mysql中通过update语句来更新已有的数据:
update 表名 set 字段1=值1,字段2=值2,……,字段n=值n where 条件表达式
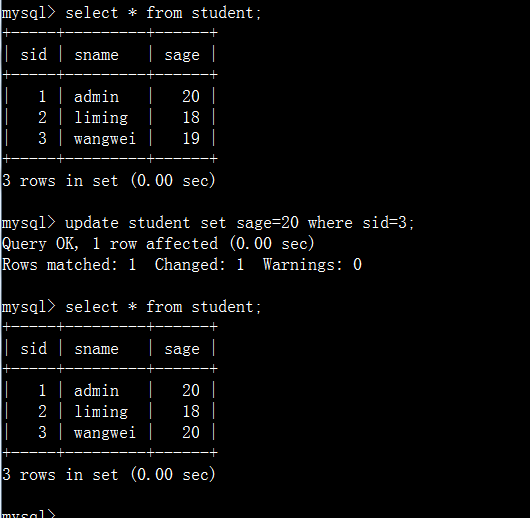
4、删除数据
语法:
delete from 表名 [where 条件表达式]
删除符合条件的数据
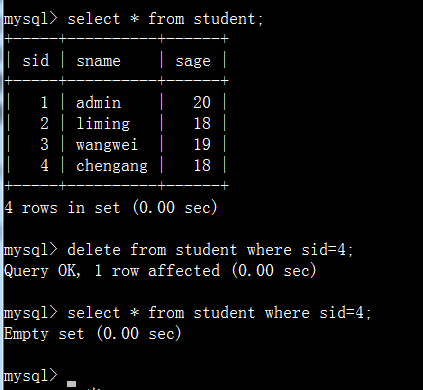
还有一种方法是:
truncate table 表名;//删除表中所有数据
参考书目:《MySQL5 数据库应用入门与提高》侯振云、肖进 编著——清华大学出版社