基于spark mllib的LDA模型训练源码解析
一直想写一篇关于LDA模型训练的源代码走读,但是因为个人水平以及时间原因未能如愿,今天想起来就记录了一下源码走读过程。有什么解释的不太清楚或者错误的地方请大家指正。
LDA模型训练大致经过以下这些步骤:
- 输入数据(已转换为Vector)和参数设置
- 根据LDA选择的算法初始化优化器
- 迭代优化器
- 获得LDA模型
下面对每一步的源码进行代码跟进。完整的项目可以到我的github下载
1. 输入数据和参数设置
文件:ckooc-ml/algorithm/utils/LDAUtils.scala
入口方法:train()
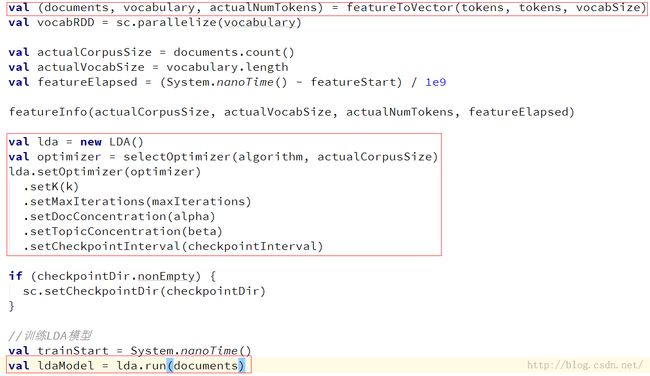
主要是红框中的三个部分:数据向量化、LDA优化器参数设置、执行训练
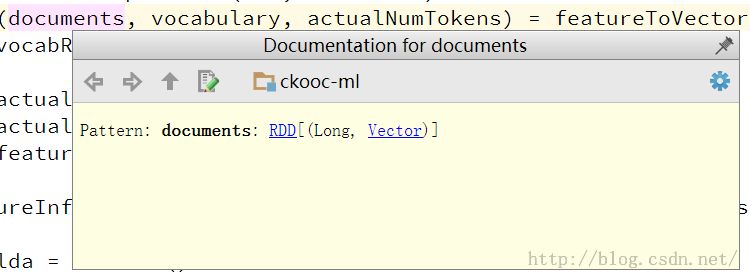
这里document中的Long类型是每个文档的ID,后面Vector是tokens的向量表示,主要形式是(词汇表大小,token的index数组,token对应的WC的数组)
LDA优化器参数设置主要是对训练时需要用到的主题数、迭代次数、初始alpha、初始beta等进行设置
run方法时LDA训练的主入口,方法具体实现如下:
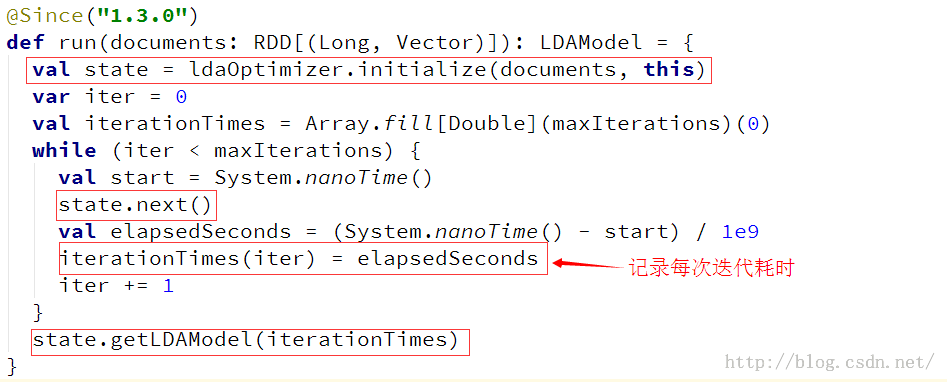
主要实现三个功能:优化器的初始化、迭代优化器、获取模型。后面对这几部分进行详细解析。
2. 根据LDA选择的算法初始化优化器
因为这里我使用的是EM算法,所以跟进LDAOptimizer.scala中直接看EMLDAOptimizer的initialize(docs: RDD[(Long, Vector)], lda:LDA)方法即可。
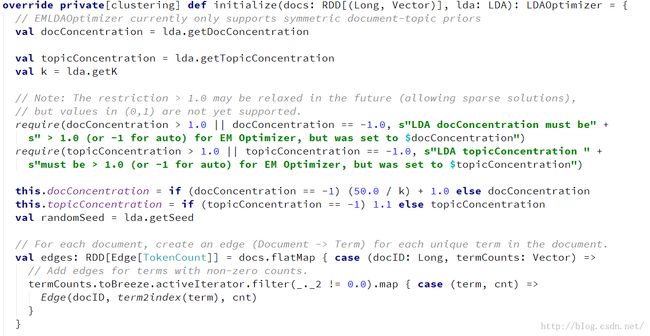
详细解析:
2.1设置参数
2.2设置alpha和beta

注意:默认的alpha= (50.0 / K) + 1.0,beta = 1.1.通常情况下不用对这两个超参数的初始值进行特殊设置,直接使用默认值即可。
2.3因为LDA模型训练使用的是图计算,故在此生成图的边(Document -> Term)

每条边包含文档ID,词的索引、词对应的WC,其中term2index方法功能如下:
![]()
2.4生成图的各个节点

从上述代码可以看到每个节点都是由一个节点ID和对应的由随机函数产生的关于主题的随机向量组成,节点ID又和边关联(VertexId= edge.srcId或edge.dstId)
2.5构建图以及优化器参数设置

3. 迭代优化器
优化器的迭代主要是由优化器的next()方法实现:
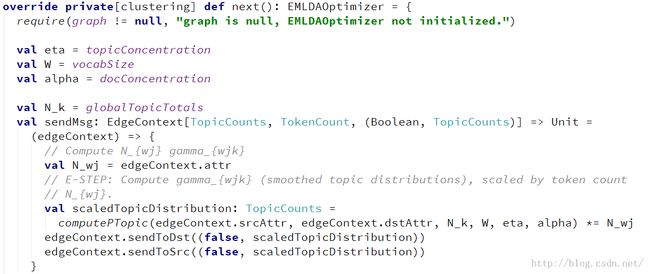
这一步的实现主要使用了EM算法总的来说分为两步E-Step和M-Step,这两步的解释如下:
- E-Step:假定参数已知,计算此时隐变量的后验概率。
- M-Step:带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数
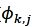 和
和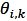 。
。
详细解析:
3.1 E-Step,计算每篇文档的后验概率,形成一个后验主题概率分布
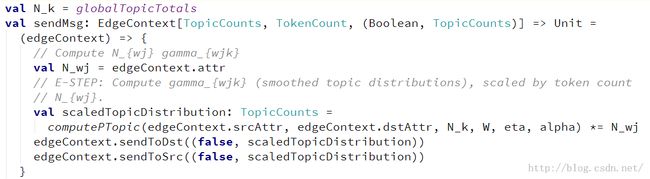
这里主要计算每个主题的后验概率的方法时computePTopic()方法:
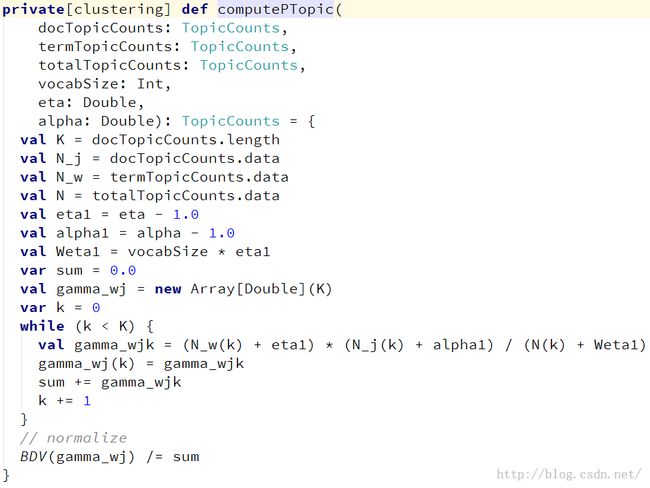
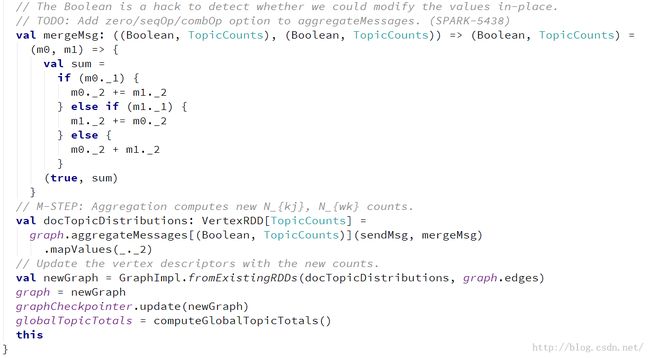
3.2 M-Step,根据后验概率分布计算![]() 和
和![]()
3.3根据新的![]() 和
和![]() 来更新图,为下一次迭代做准备
来更新图,为下一次迭代做准备
EM算法的实现也可以参考:“通俗理解LDA主题模型”中关于pLSA和LDA的参数估计部分
4. 获得LDA模型
这一部分比较简单,直接使用训练好的graph等信息生成一个DistributedLDAModel即可
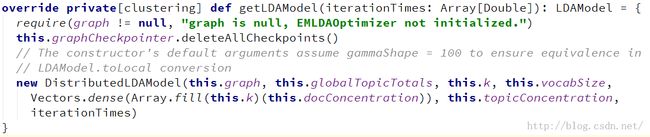
5. 总结
以上就是spark上整个的LDA模型训练过程。总结下来还是挺简单的,主要就以下几个步骤:
- 初始参数构造图(边:doc-term,顶点:doc-topics)
- 使用EM算法,计算每个doc的,形成doc 的后验主题分布
- 根据后验主题分布计算参数和
- 根据参数和更新图
- 得到模型
其中2-4步根据迭代次数进行迭代