关于oracle数据库读取数据的三种方式
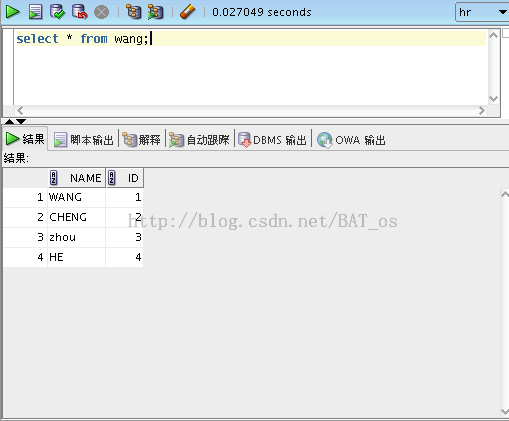
打开oracle sqldeveloper,连接到HR模式下的数据库,在SQL工作表中,执行如下语句:
CREATE TABLE WANG(
Name varchar2(6),
ID number );
然后向表中插入如下语句:
INSERT INTO WANG VALUES(‘WANG’,1);
INSERT INTO WANG VALUES(‘CHENG’,2);
INSERT INTO WANG VALUES(‘ZHOU’,3);
INSERT INTO WANG VALUES(‘HE’,4);
Commit;
在Sqldeveloper查询入下图所示:
下面将分别介绍三种数据读取方式:
1.通过全表扫描
在使用全表扫描的时候,利用多块读,oracle读取表中的所有行,可以提高全表扫描的速度,可以大大的减少I/O的次数,是一种很好的读取方法,通常采用全表扫描,但是读取较大的表时,不建议采取全表扫描的方法。
那我们查看下采取全表扫描先:
在sql工作表中执行
Explain plan for select * from wang;
Select * from table(dbms_xplan.display);
如下图:
发现第七行TABLE ACCESS FULL了吧。
2.通过ROWID
我们在对表对象采取数据插入时,会隐含创建ROWID,是64进制数,它是数据行所存储的数据块地址,所以我们可以通过查找ROWID可以快速查找到我们想要查找的数据。ROWID中指出了对象编号,数据文件编号,块号,行号。那我们来看下到底什么是ROWID。
在SQL工作表中执行
Select name,id ,rowid from wang;
如下图所示:
ROWID总共有十八位,以第一行的ROWID为例:
AAASVp AAE AAAAKP AAA
它是64进制数,我们来分析下rowid中各个字符代表什么:
A~Z 代表0~25
a~z 代表26~51
0~9 代表52~61
+ 代表 62
/ 代表 63
细心的读者可以发现我把上面的十八位分成了四小组:
第一组(前六位):是代表对象的编号
第二组(三位):文件编号
第三组(六位):块编号
第四组(三位):行号
既然是十六进制数,那我们转换成十进制数看看先(以对象编号为例):
AAASVp
0+0+0+18*64*64+ 21*64+ 41=75113
我们可以在视图中查找对象编号来验证上面我们通过ROWID计算得到的对象编号正确性。打开sqlplus窗口,执行下面语句:
Select object_name,data_object_id from dba_objects where object_name=’wang’;
结果如下图:
通过上面的实验,你是否理解ROWID的含义了呢,同理,文件编号,块编号,行编号可以通过此方法得到验证,读者自己可以尝试去实验。
我们可以比较ROWID和全表扫描哪个更快:
在sqldeveloper的SQL工作表中执行:
Explain plan for select * from wang where rowid=’AAASVp AAE AAAAKP AAA’;
Select * from table(dbms_xplan.display);
结果如下图:
通过比较,通过ROWID查找数据是最快的。
3.通过索引
我们可以通过索引找到数据行的 ROWID,然后通过ROWID直接到表中查找数据,这种方式为索引查找或者称为索引扫描。因为一个ROWID对应一个数据行,所以这种方式是采用的单块读取。索引中不仅存储索引值,还存储相应的ROWID。索引查找分为两步,扫描索引找到相应的ROWID,人后找到对应的ROWID然后从表中读取相应的数据。每次都是单块的I/O去读,由于索引比较小,而且经常使用,一般会被缓存到内存中,并且第一步通常是逻辑读(数据可以从内存中得到),由于表数据较大,第二步通常为物理读(逻辑读的速度是大于物理读取,物理读性能比较低)。我们创建了索引,但是是否使用是ORACLE根据CBO优化器计算的结果选择,普通用户是无法干预的。
我们来做下实验,访问路径走主键索引的查询(此时已在sqldeveloper中把WANG.ID设为主键)。
在Sqldeveloper中的SQL工作表中执行以下语句:
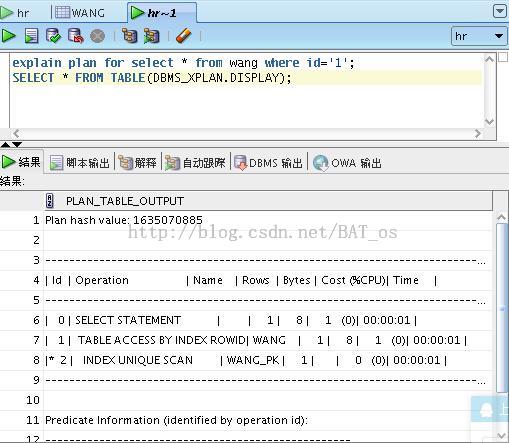
Explain plan for select * from wang where id=’1’;
Select * from table(dbms_xplan.display);
结果如下图:
由下图我们可以看出访问路径走的是主键索引,所以你看到的是INDEX UNIQUE SCAN,首先是索引扫描,然后是根据索引查找到ROWID进行表的访问。
你也许会问,我们不是没有创建索引吗,怎么会通过索引来查找呢,因为我们在指定主键时,Oracle会自动创建主键索引,是唯一索引。我们可以创建一般索引,唯一索引,位图索引等。
完整语法:
CREATE (UNIQUE|BITMAP) INDEX [用户名.]索引名 ON [用户名.]表名 (列名 [ ASC | DESC], [列名 [ ASC | DESC]]...)
[ TABLESPACE 表空间名 ]
[ PCTFREE 正整型数 ]
[ INITRANS 正整型数 ]
[ MAXTRANS 正整型数 ]
[ 存储子句 ]
[ LOGGING | NOLOGGING ]
[ NOSORT ]
ORACLE自动创建的主键索引是什么样的呢?那我们来看看先:
Select * from user_indexes where table_name=’WANG’;

我们知道原来这个索引名字叫WANG_PK,知道为什么叫主键索引了吧,索引涉及到优化,不是我们创建了索引,就会使用索引,要根据优化器选择。事物都有两面性,它可以帮助我们快速找到想要的数据,但是在有些情况下会带来性能开销,不要认为使用索引就是好事。索引扫描有四种方式:唯一扫描,范围扫描,全扫描,快速扫描,这里不一一叙述。有时候我们创建了索引,我们也可以限制索引,如我们使用了函数,但是没有创建基于该函数的索引。鉴于本人水平有限,索引涉及的内容远远超过这些,对有兴趣的读者可以更深入的了解索引。Oracle是一座巨大矿山,值得学数据库的你去探索,oracle中它真的很棒,从它的体系结构到很小的一部分可以说都做的很好,给我们带来很大的方便,在这个多用户的时代,它的优势更加的显著,市场占有率可以说明这一点。