后缀自动机:O(N)的构建及应用
译者的话:
原文地址http://e-maxx.ru/algo/suffix_automata
俄文用google机翻成英文再翻成中文,错误在所难免,大家多包涵……如果有什么奇怪的话直接略过吧,因为这说明我也没看懂……
后缀自动机
后缀自动机(单词的有向无环图)——是一种强有力的数据结构,让你能够解决许多字符串问题。
例如,使用后缀自动机可以在某一字符串中搜索另一字符串的所有出现位置,或者计算不同子串的个数——这都能在线性时间内解决。
直觉上,后缀自动机可以被理解为所有子串的简明信息。一个重要的事实是,后缀自动机以压缩后的形式包含了一个长度为n的字符串的所有信息,仅需要O(n)的空间。并且,它能在O(n)时间内被构造(如果我们将字母表的大小k视作常数,否则就是O(n*logk))。
历史上,Blumer等人于1983年首次提出了后缀自动机的线性规模,然后在1985-1986年,人们提出了首个线性时间内构建后缀自动机的算法(Crochemore,Blumer等)。在文末链接处查看更多细节。
后缀自动机在英文中被称作“suffix automaton”(复数形式:suffix automata),单词的有向无环图——"direcged acyclic word graph"(简写为“DAWG”)。
后缀自动机的定义
定义.对给定字符串s的后缀自动机是一个最小化确定有限状态自动机,它能够接收字符串s的所有后缀。
下面解释这一定义:
- 后缀自动机是一张有向无环图,其中顶点是状态,而边代表了状态之间的转移。
- 某一状态t_0被称作初始状态,由它能够到达其余所有状态。
- 自动机中的所有转移——即有向边——都被某种符号标记。从某一状态出发的诸转移必须拥有不同的标记。(另一方面,状态转移不能在任何字符上)。
- 一个或多个状态被标记为终止状态。如果我们从初始状态t_0经由任意路径走到某一终止状态,并顺序写出所有经过边的标记,你得到的字符串必然是s的某一后缀。
- 在符合上述诸条件的所有自动机中,后缀自动机有这最少的顶点数。(后缀自动机并不被要求拥有最少的边数)
后缀自动机的最简性质
最简性——后缀自动机的最重要性质是:它包含了所有s的子串的信息。换言之,对于任意从初始状态t_0出发的路径,如果我们写出所经过边上的标记,形成的子串必须是s的子串。相应地,s的任意子串都对应一条从初始状态t_0出发的路径。
为了简化说明,我们称子串“匹配”了从初始状态出发的路径,如果该路径上的边标记组成了这一子串。相应地,我们称任意路径“匹配”某一子串,该子串由路径中边的标记组成。
后缀自动机的每个状态都引领一条或多条从初始状态出发的路径。我们称这个状态有若干匹配这些路径的方法。
构建后缀自动机的实例
下面给出一些对简单的字符串构建后缀自动机的例子。
初始状态被记作t0,终止状态用星号(*)标记。
s=""
s="a"
s="aa"
s="ab"
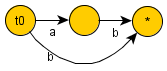
s="aba"

s="abb"

s="abbb"
一个线性时间构建后缀自动机的算法
在我们描述构建算法之前,有必要介绍一些新的概念和简要的证明,它们对理解后缀自动机的概念十分重要。
结束位置endpos,它们的性质及与后缀自动机的联系
考虑字符串s的任意非空子串t。我们称终点集合endpos(t)为:s中所有是t出现位置终点的集合。
我们称两个子串t_1和t_2“终点等价”,如果它们的终点集合一致:endpos(t_1)=endpos(t_2)。因此,所有s的非空子串可以根据终点等价性分成若干类。
事实上对后缀自动机,终点等价字符串仍然保持相同性质。换句话说,后缀自动机中状态数等价于所有子串的终点等价类个数,加上初始状态。每个状态对应一个或多个拥有相同终点集合的子串。
我们将这一陈述作为假定,然后描述一个基于此假设的,线性时间构建后缀自动机的算法——正如我们不久后将会看到的,所有后缀自动机的必须性质,除最小性(即最少顶点数),都将被满足(最小性由Nerode产生,见参考文献)。
关于终点集合,我们给出一些简单但重要的事实。
引理1.两个非空子串u和v(length(u)<=length(v))是终点等价的,当且仅当u在字符串s中仅作为w的后缀出现。
证明是显然的。(译者注:证明的几句话我看不懂,编不下去了……)
引理2.考虑两个非空子集u,w(length(u)<=length(w))。它们的终点集合不相交,或者endpos(w)是endpos(u)的子集。进一步地,这取决于u是否是w的后缀:
证明.假设两个集合endpos(u)和endpos(w)有至少一个公共元素,这就意味着字符串w和u在同一位置结束,即u是w的后缀。因此,在字符串w的每次出现的终点u都会出现,这就意味着endpos(w)包含于endpos(u)。
引理3.考虑一个终点等价类。将该等价类中的子串按长度递减排序。排序后的序列中,每个子串将比上一个子串短,从而是上一个字串的后缀。换句话说,某一终点等价类中的字符串互为后缀,它们的长度依次取区间[x,y]内的所有数。
证明.考虑这个终点等价类。如果它只包含一个子串,那么引理3的正确性显然。假设现在子串的个数多于一个。
根据引理1,两个不同的终点等价子串总满足一个是另一个的严格后缀。因此,在同一终点等价类中的子串不可能有相同的长度。
令w较长,u是等价类中的最短子串。根据引理1,u是w的严格后缀。考虑w任意一个长度为[length(u),length(w)]之间的后缀,由引理1,显然它在终点等价类中。
后缀链接
考虑一个状态v≠t_0.就我们目前所知,有一个确定的子串集合,其中元素和v有着相同的终点集合。并且,如果我们记w是其中的最长者,其余子串均是w的后缀。
我们还知道w的前几个后缀(按照长度降序)在同一个终点等价类中,其余后缀(至少包括空后缀)在别的终点等价类中。令t是第一个这样的后缀——对它我们建立后缀链接。
换言之,v的后缀链接link(v)指向在不同等价类中的w的最长后缀。
在此我们假设初始状态t_0在一个单独的终点等价类中(仅包含空字符串),并且endpos(t_0)={-1,...,length(s)-1}。
引理4.后缀链接组成了一棵以t_0为根的树。
证明.考虑任意状态v≠t_0.后缀链接link(v)指向的状态所对应的字符串长度严格小于它本身(根据后缀链接的定义和引理3)。因此,沿着后缀链接移动,我们将早晚到达t_0,它对应一个空串。
引理5.如果我们将所有合法的终点集合建成一棵树(使得孩子是父母的子集),这棵树将和后缀链接构成的树相同。
证明.终点集合能构成一棵树这一事实由引理2得出(两个终点集合要么不相交,要么一个包含另一个)。
我们现在考虑任意状态v≠t_0,及其后缀链接link(v)。根据后缀链接的定义和引理2得出:
endpos(v)⊂endpos
这和上一引理证明了我们的断言:后缀链接树和终点集合树相同。
这里是一个后缀链接的例子,表示字符串"abcbc":

小结
在学习具体算法之前,总结上面积累的知识,并引入两个辅助符号。
- s的所有子串可以按照它们的终点集合被分成等价类。
- 后缀自动机由一个初始状态t_0和所有不同的终点等价类所对应的状态组成。
- 每个状态v对应一个或多个字符串,我们记longest(v)是其中最长者,len(v)是其长度。我们记shortest(v)是这些字符串中的最短者,其长度为minlen(v)。
- 该状态对应的所有字符串是longest(v)的不同后缀,并且包括[minlen(v),len(v)]之间的所有长度。
- 对每个状态v≠t_0定义的后缀链接指向的状态对应longest(v)的长度为minlen(v)-1的后缀。后缀链接形成一棵以t_0为根的树,而这棵树事实上是所有终点集合的树状包含关系。minlen(v)和link(v)的关系表示如下:minlen(v)=len(link(v))+1.
- 如果我们从任意节点v_0开始沿后缀链接移动,我们早晚会到达初始状态t_0.在此情况下,我们得到了一系列不相交的区间[minlen(v_i),len(v_i)],其并集是一个连续区间。
一个构建后缀自动机的线性时间算法
我们下面描述这个算法。算法是在线的,即,逐个向s中加入字符,并适当地对当前的自动机进行修改。
为了达到线性空间的目的,我们将只存储每个状态的len,link的值,以及转移列表。我们并不支持标记终止状态(我们将展示如果需要,如何在后缀自动机构建完毕后加上这些标记)。
最初自动机由一个状态t_0组成,我们称之为0状态(其余状态将被称作1,2,...)。对此状态,令len=0,为方便起见,将link值设为-1(指向一个空状态)。
因此,现在的任务就变成了实现向当前字符串末尾添加一个字符c的操作。下面我们描述这一操作:
- 令last为对应整个字符串的状态(最初last=0,在每次字符添加操作后我们都会改变last的值)。
- 建立一个新的状态cur,令len(cur)=len(last)+1,而link(cur)的值并不确定。
- 我们最初在last,如果它没有字符c的转移,那就添加字符c的转移,指向cur,然后走向其后缀链接,再次检查——如果没有字符c的转移,就添加上去。如果在某个节点已有字符c的转移,就停止,并且令p为这个状态的编号。
- 如果“某节点已有字符c的转移”这一事件从未发生,而我们来到了空状态-1(经由t_0的后缀指针前来),我们简单地令link(cur)=0,跳出。
- 假设我们停在了某一状态q,是从某一个状态p经字符c的转移而来。现在有两种情况:len(p)+1=len(q)或不然。
- 如果len(p)+1=len(q),那么我们简单地令link(cur)=q,跳出。
- 否则,情况就变得更加复杂。必须新建一个q的“拷贝”状态:建立一个新的状态clone,将q的数据拷贝给它(后缀链接,以及转移),除了len的值:需要令len(clone)=len(p)+1.
- 在拷贝之后,我们将cur的后缀链接指向clone,并将q的后缀链接重定向到clone。
- 最终,我们需要做的最后一件事情就是——从p开始沿着后缀链接走,对每个状态我们都检查是否有指向q的,字符c的转移,如果有就将其重定向至clone(如果没有,就终止循环)。
- 在任何情况下,无论在何处终止了这次添加操作,我们最后都将更新last的值,将其赋值为cur。
如果我们还需要知道哪些节点是终止节点而哪些不是,我们可以在构建整个字符串的后缀自动机之后找出所有终止节点。对此我们考虑对应整个字符串的节点(显然,就是我们储存在变量last中的节点),我们沿着它的后缀链接走,直到到达初始状态,并且将途径的每个节点标记为终止节点。很好理解,如此我们标记了字符串s所有后缀的对应状态,也就是我们想要找出的终止状态。
在下一节中我们从细节上考虑算法的每一步,并证明其正确性。
这里我们仅注意一点:每个字符的添加会导致向自动机中添加一个或两个状态。因此,状态数显然是线性的。
转移数量的线性性,以及算法的线性时间复杂度较难理解,它们将在下面被证明,位于算法正确性的证明之后。
算法的正确性证明
- 我们称转移(p,q)是连续的,如果len(p)+1=len(q)。否则,即len(p)+1<len(q)时,我们称之为不连续转移。
- 正如在算法描述中可以看到的那样,连续转移和不连续转移导致了算法流程的不同分支。连续转移(译者注:俄文中‘连续的’和‘牢靠的’是同一个单词)被如此命名是因为,自第一次出现后,它们将保持不变。相反,不连续转移可能会在向字符串中添加新字符的过程中被改变(可能会改变该边指向的状态)。
- 为了避免歧义,我们称s是我们已经构建了自动机的字符串,它正准备添加当前字符c。
- 算法开始时我们创建了新状态cur,它将匹配整个字符串s+c。我们之所以必须新建一个状态的原因是显然的——在添加新字符后,出现了一个新的终点等价类——一类以新字符串s+c的末尾为结尾的子串。
- 在创建新状态后,算法从和整个字符串s匹配的状态开始,沿着后缀链接移动,在途中试图添加指向cur的,字符c的转移。但我们只会在不和已存在转移冲突的情况下添加新的转移,因此一旦我们遇到了一个字符c的转移,我们就必须立刻停止。
- 最简单的情形——如果我们来到了空状态-1,向途中所有节点添加了字符c的转移。这就意味着字符c在字符串s中先前未曾出现。我们成功地添加了所有的转移,只需要记下状态cur的后缀链接——它显然必须等于0,因为这种情况下cur匹配字符串s+c的一切后缀。
- 第二种情况——当我们进入一个已存在的转移(p,q)时。这意味着我们试图向字符串中添加字符x+c(其中x是字符串s的某一后缀,长度为len(p)),且该字符串先前已经被加入了自动机(即,字符串x+c已经作为子串包含在字符串s中)。因为我们假设字符串s的自动机已被正确构建,我们并不应该添加新的转移。
然而,cur的后缀链接指向哪里有一定复杂性。我们需要将后缀链接指向一个长度恰好和x+c相等的状态,即,该状态的len值必须等于len(p)+1.但这样一种情况可能并不存在:在此情况下我们必须添加一个“分割的”状态。 - 因此,一种可能的情形是,转移(p,q)变得连续,即,len(q)=len(p)+1.在这种情况下,事情变得简单,不必再进行任何分割,我们只需要将cur的后缀链接指向q。
- 另一种更复杂的情况——当转移不连续时,即len(q)>len(p)+1.这意味着状态q不仅仅匹配对我们必须的,长度len(p)+1的子串w+c,它还匹配一个更长的子串。我们不得不新建一个“分割的”状态q:将子串分割成两段,第一段将恰在长度len(p)+1处结束。
如何实现这个“分割”呢?我们“拷贝”一个状态q,将其复制为clone,但参数len(clone)=len(p)+1.我们将q的所有转移复制给clone,因为无论如何我们不想改变经过p的路径。从clone出发的后缀链接总是指向q原先的后缀链接,而且q的后缀链接将指向clone。
在拷贝之后,我们将cur的后缀链接指向clone——我们拷贝它就是为了干这个的。
最后一步——重定向一些指向q的转移,将它们改为指向clone。哪些转移必须被重定向?只需要重定向那些匹配所有w+c的后缀的。即,我们需要持续沿着后缀链接移动,从p开始,只要没有到达空状态-1或者没有到达一个状态,其c的转移指向不同于q的状态。
证明操作个数是线性的
首先,我们曾经说过要保证字母表的大小是常数。否则,那么线性时间就不再成立:从一个顶点出发的转移被储存在B-树中,它支持按值的快速查找和添加操作。因此,如果我们记字母表的大小是k,算法的渐进复杂度将是O(n*logk),空间复杂度O(n)。但是,如果字母表足够小,就有可能牺牲部分空间,不采用平衡树,而对每个节点用一个长度为k的数组(支持按值的快速查找)和一个动态链表(支持快速遍历所有存在的键值)储存转移。这样O(n)的算法就能够运行,但需要消耗O(nk)的空间。
因此,我们假设字母表的大小是常数,即,每个按字符查询转移的操作、添加转移、寻找下一个转移——所有这些操作我们都认为是O(1)的。
如果我们观察算法的所有部分,会发现其中三处的线性时间复杂度并不显然:
- 第一处:从last状态开始,沿着后缀链接移动,并且添加字符c的转移。
- 第二处:将q复制给新状态clone时复制转移。
- 第三处:将指向q的转移重定向到clone。
我们使用众所周知的事实:后缀自动机的大小(状态和转移的数目)是线性的。(对状态个数是线性的证明来自算法本身,对于转移个数是线性的证明,我们将在下面给出,在实现算法之后。)。
那么显然第一处和第二处是渐进线性的,因为每次操作都会增加新的状态和转移。
仍然需要估算第三处总的线性复杂度——在每次添加字符时我们将指向q的转移重定向至clone。
我们不妨关注shortest(link(last))。注意到,在沿着后缀链接上溯的过程中,当前节点的shortest的长度总是严格变小。
显然,在向s中添加新字符之前,shortest(link(last))的长度不小于shortest(p)的长度,因为link(last)至多是p。尔后假设我们由q拷贝得到了节点clone,并试图从p沿后缀链接上溯,将所有通往q的转移重定向为通往clone。设v是shortest(当前节点),在clone刚刚建立完成后,v=short(p)。然后,在每次沿后缀链接上溯时,v的值都会变小,而如果当前节点存在经过字符c通往q的转移,就意味着q对应的字符串集合中包含v+c,也意味着clone包含的字符串集合中包含v+c。换言之,我们为clone包含的字符串集合找到了一个更短的元素,即减少了short(clone)的长度。
在“向s中添加新字符”的整个流程结束后,有link(last)=link(cur)=clone。根据上面的讨论,新的shortest(link(last))的长度变小(或保持不变),而且这一长度减小的值和上溯的操作数同阶。
综上,shortest(link(last))作为s一个后缀的起始位置在整个过程中不断右移,而且每次沿后缀指针上溯都会导致该位置严格右移。由于在程序结束时这一起始位置不超过n,所以这一过程的时间复杂度是线性的。
(虽然没什么用,但同样的讨论可以被用来证明第一处的线性性,以代替对状态个数线性性的证明。)
算法的实现
首先我们描述一个数据结构,它储存特定的一段信息(len,link,转移列表)。如有必要,你可以增加表示终止状态的标签,以及其他需要的信息。我们用STL容器map存储转移列表,其空间复杂度为O(n),而处理整个字符串的时间复杂度为O(n*logk)。
struct state {
int len, link;
map<char,int> next;
};
后缀自动机本身将被储存在一个state类型的数组中。正如下一节中将证明的那样,如果程序中所处理字符串的最大可能长度是MAXN,那么至多会占用2*MAXN-1个状态。同时,我们储存变量last——当前匹配整个字符串的状态。
const int MAXLEN = 100000; state st[MAXLEN*2]; int sz, last;我们给出初始化后缀自动机的函数(新建一个初始状态):
void sa_init() {
sz = last = 0;
st[0].len = 0;
st[0].link = -1;
++sz;
/*
// 若关于不同的字符串多次建立后缀自动机,就需要执行这些代码:
for (int i=0; i<MAXLEN*2; ++i)
st[i].next.clear();
*/
}
最后,我们给出基础函数的实现——向当前字符串的尾部添加一个字符,并相应地修改后缀自动机:void sa_extend (char c) {
int cur = sz++;
st[cur].len = st[last].len + 1;
int p;
for (p=last; p!=-1 && !st[p].next.count(c); p=st[p].link)
st[p].next[c] = cur;
if (p == -1)
st[cur].link = 0;
else {
int q = st[p].next[c];
if (st[p].len + 1 == st[q].len)
st[cur].link = q;
else {
int clone = sz++;
st[clone].len = st[p].len + 1;
st[clone].next = st[q].next;
st[clone].link = st[q].link;
for (; p!=-1 && st[p].next[c]==q; p=st[p].link)
st[p].next[c] = clone;
st[q].link = st[cur].link = clone;
}
}
last = cur;
}
像前面提到的那样,如果牺牲部分空间(空间复杂度增至O(nk),其中k是字母表大小),就能够对任何k实现O(n)构建自动机——但这将会在每个状态中建立一个长度为k的数组(用于快速按字符查询转移)和一个转移链表(用于快速遍历或者复制所有转移)。后缀自动机的其他性质
状态的数量
由长度为n的字符串s建立的后缀自动机的状态个数不超过2n-1(对于n>=3)。
上面描述的算法证明了这一性质(最初自动机包含一个初始节点,第一步和第二步都会添加一个状态,余下的n-2步每步至多由于需要分割,增加两个状态)。
不过,即使不涉及算法,这一性质也容易证明。注意到状态个数等于不同的终点集合的个数。此外,终点集合按“子女是父节点的不同子集”这一原则构成一棵树。
考虑这棵树,将其稍作扩充:若一个内部节点只有一个儿子,那就意味着该儿子的终点集合不包含其父亲终点集合中的至少一个值;那么我们就创建一个虚拟节点,其终点集合为这个值。最终,我们得到了一棵树,其内部节点度数均>1,而叶子节点个数不超过n。因此,这棵树的结点个数不超过2n-1.自然,原树的结点个数也不超过2n-1.
这样我们就独立于算法地证明了这一性质。
有趣的是,这一上限无法被改善,即存在达到这一上限的例子:
"abbbb..."
从第三次开始,每次添加字符时都会进行分割,因此结点个数将达到2n-1.
转移的数量
由长度为n的字符串s建立的后缀自动机中,转移的数量不超过3n-4(对于n>=3)。
证明.
我们计算“连续的”转移个数。考虑以t_0为初始节点的自动机的最长路径树。这棵树将包含所有连续的转移,树的边数比结点个数小1,这意味着连续的转移个数不超过2n-2.
我们再来计算不连续的转移个数。考虑每个不连续转移;假设该转移——转移(p,q),标记为c。对自动机运行一个合适的字符串u+c+w,其中字符串u表示从初始状态到p经过的最长路径,w表示从q到任意终止节点经过的最长路径。一方面,对所有不连续转移,字符串u+c+w都是不同的(因为字符串u和w仅包含连续转移)。另一方面,每个这样的字符串u+c+w,由于在终止状态结束,它必然是完整串s的一个后缀。由于s的非空后缀仅有n个,并且完整串s不能是某个u+c+w(因为完整串s匹配一条包含n个连续转移的路径),那么不连续转移的总共个数不超过n-1.
将这两个限制加起来,我们就得到了总数限制3n-3.注意到虽然状态个数限制可以被数据"abbbb..."达到,但这个数据并未达到3n-3的转移个数上限。它的转移个数是3n-4,符合要求。
有趣的是,仍然存在达到转移个数上限的数据:
"abbb...bbbc"。
与后缀树的联系,在后缀自动机上建立后缀树及反之
我们证明两个定理,它们能说明后缀树和后缀自动机之间的相互关系。
首先我们假定输入字符串的每个后缀都在其后缀树中对应一个节点(对于任意字符串而言并不一定成立:例如,对于字符串 "aaa..." )。在后缀树的典型实现中,我们通过在字符串的末尾加上一个特殊符号(例如"#"或"$")来保证这一点。
方便起见,我们引入如下记号:rev(s)——将字符串s反过来写,DAWG(s)——这是由字符串s建立的后缀自动机,ST(s)——这是s的后缀树。
我们介绍“扩展指针”的概念:对于树节点v和字符c,ext[c,v]指向树中对应于字符串c+v的节点(如果路径c+v在某边的终点结束,那就将其指向该边的较低点);如果这样一条路径c+v不在树中,那么扩展指针未定义。在某种意义上,扩展指针的对立面就是后缀链接。
定理1.DAWG(s)中后缀链接组成的树就是后缀树ST(rev(s))。
定理2.图DAWG(s)的边都能用后缀树ST(rev(s))的扩展指针表示。另外,DAWG(s)中的连续转移就是ST(rev(s))中反向的后缀指针。
这两条定理允许使用两个数据结构之一在O(n)的时间内构建另外一个——这两个简单的算法将在下面定理3,4讨论。
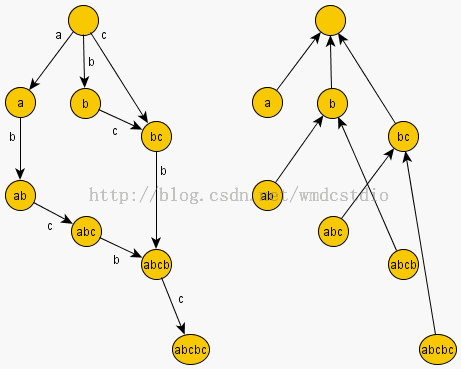
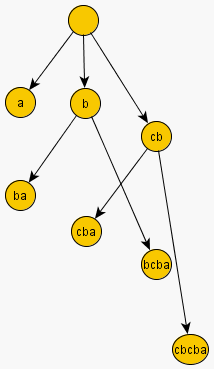
出于说明需要,我们下面展示一个包含后缀链接的后缀自动机的例子,以及其倒序字符串的相应后缀树。例如,令字符串s="abcbc"。
DAWG("abcbc")(出于简便我们在每个状态上标出其识别的最长串):
ST("cbcba"):
引理.对任意两个子串u和w,如下三个陈述是等价的:
- 在字符串s中endpos(u)=endpos(w)
- 在字符串rev(s)中firstpos(rev(u))=firstpos(rev(w))
- 在后缀树ST(rev(s))中,rev(u)和rev(w)匹配从根开始的一段相同路径。
证明十分显然:如果两个字符串的起始位置集合相同,那么一个字符串只作为另外一个的前缀出现,这意味着在后缀树中,二者之间并没有其他节点。
因此,后缀自动机中的状态和后缀树中的节点一一对应。
定理1的证明.
后缀自动机中的状态和后缀树中的节点一一对应.
考虑任意后缀链接y=link(x)。根据后缀链接的定义,longest(y)是longest(x)的一个后缀,并且y是所有满足条件(和x的终点集合不同)的状态中使len(y)最大者。
在rev(s)中,这意味着link(x)指向x所对应字符串的最长前缀,该前缀对应一个不同的状态y。换句话说,后缀链接link(x)指向后缀树中节点x的父亲。
定理2的证明.
后缀自动机中的状态和后缀树中的节点一一对应。
考虑后缀自动机DAWG(s)中的任意转移(x,y,c)。这意味着y是包含子串longest(x)+c的终点集合等价类。对于rev(s),y对应了一个子串,该子串的firstpos(在文本rev(s)中)和c+rev(longest(x))的firstpos相同。
这意味着:
rev(longest(y))=ext[c,rev(longest(x))].
(译者注:这里的用法并不严谨……请自行把字符串和节点对应)
也就是该定理的第一部分,我们还需要证明第二部分:自动机中的所有连续转移对应树中的后缀指针。对于连续转移,有length(y)=length(x)+1,即在标识字符c后我们到达了一个状态,它是一个不同的等价类。这意味着在rev(s)的后缀树中,x节点对应的字符串恰好是y节点所对应字符串的,长度比它小1的后缀——也就是说,后缀树中y的后缀指针指向x,(x,y)就是树中的反向后缀指针。
定理得证。
定理3.使用后缀自动机DAWG(s),我们可以用O(n)的时间构建后缀树ST(rev(s))。
定理4.使用后缀树ST(rev(s)),我们可以用O(n)的时间构建后缀自动机DAWG(s)。
定理3的证明.
后缀树ST(rev(s))的节点和DAWG(s)中的状态一一对应。树中与自动机中状态v相对应的节点表示一个长度为len(v)的字符串。
根据定理1,ST(rev(s))中的边恰好是把DAWG(s)的后缀链接反向,而边的标记可以借助不同状态的len计算(译者注:从叶子开始,利用自动机中状态的len值计算后缀树中的节点对应于哪个子串),或者更方便地,对自动机中每个状态我们都能知道其endpos集合中的一个元素(在构建后缀自动机时维护)。
至于树中的后缀指针,我们可以基于定理2构建:查找自动机中所有的连续转移,对所有这样的转移(x,y)我们都在树中添加一个后缀指针link[y]=x。
因此,在O(n)时间内我们就可以构建一棵后缀树及其中的后缀指针。
(如果我们认为字母表的大小k并非常数,那么重建操作将花费O(n*logk)的时间。)
定理4的证明.
后缀自动机DAWG(s)包含的状态和ST(rev(s))中的节点一一对应。对每个状态v,其对应的最长字符串longest(v)都和后缀树中从根到v的路径翻转后形成的字符串相同。
根据定理2,为了构建自动机中的所有转移,我们需要找到所有扩展ext[c,v]的指针。
首先,注意到其中的一些指针直接由树中的后缀指针得到。事实上,如果对于树中任意节点x,我们考虑其后缀指针y=link[x],那就意味着自动机中有一个从y指向x的连续转移,标记为树节点x所对应字符串的第一个字符。
不过,只是这样我们并不能找到所有的扩展。额外地,有必要从叶子到根遍历后缀树,而且对于每个节点v都遍历其所有儿子,对每个儿子观察所有扩展指针ext[c,w],如果该指针上的字符c在节点v中还未发现,就将其复制到v中:
ext[c,v]=ext[c,w],如果ext[c,w]=nil.
这一过程将在O(n)时间内完成,如果我们认为字母表的大小是常数。
最终,还需要建立后缀自动机中的后缀链接。而根据定理1,后缀链接可以直接由后缀树ST(rev(s))的边获得。
这样,我们就得到使用从倒序字符串的后缀树建立后缀指针的O(n)算法。
(不过,若字母表的大小k是变量,那么渐进复杂度就是O(n*logk))。
在解决问题中的应用
下面看在后缀自动机的帮助下我们能做什么。
简便起见,我们假设字母表的大小k为常数。
存在性查询
问题.给定文本T,询问格式如下:给定字符串P,问P是否是T的子串。
复杂度要求.预处理O(length(T)),每次询问O(P)。
算法.我们对文本T用O(length(T))建立后缀自动机。
现在回答单次询问。假设状态——变量v,最初是初始状态T_0.我们沿字符串P给出的路径走,因此从当前状态经转移来到新的状态v。如果在某时刻,当前状态没有要求字符的转移,那么答案就是"no"。如果我们处理了整个字符串P,答案就是"yes"。
显然这一算法将在时间O(length(P))内运行完毕。并且,该算法实际上找出了P在文本中出现过的最长前缀——如果模式串使得这些前缀都很短,算法将比处理全部模式串要快得多。
不同的子串个数
问题.给定字符串S,问它有多少不同的子串。
复杂度要求.O(length(S))。
算法.我们将字符串S建立后缀自动机。
在后缀自动机中,S的任意子串都对应自动机中的一条路径。答案就是从初始节点t_0开始,自动机中不同的路径条数。
已知后缀自动机是一张有向无环图,我们可以考虑用动态规划计算不同的路径数量。
也就是,令d[v]为从状态v开始的不同路径条数(包括长度为零的路径),则有转移:

即d[v]是v所有后继节点的d值之和加上1.
最终答案就是d[t_0]-1(减一以忽略空串)。
不同子串的总长
问题.给定字符串S,求其所有不同子串的总长度。
复杂度要求.O(length(S)).
算法.这一问题的答案和上一题类似,但现在我们必须考虑两个状态:不同子串的个数d[v]和它们的总长ans[v].
上一题已描述了d[v]的计算方法,而ans[v]的计算方法如下:
即取所有后继节点w的ans值,并将它和d[w]相加。因为这是每个字符串的首字母。
字典序第k小子串
问题.给定字符串S,一系列询问——给出整数K_i,计算S的所有子串排序后的第K_i个。
复杂度要求.单次询问O(length(ans)*Alphabet),其中ans是该询问的答案,Alphabet是字母表大小。
算法.这一问题的基础思路和上两题类似。字典序第k小子串——自动机中字典序第k小的路径。因此,考虑从每个状态出发的不同路径数,我们将得以轻松地确定第k小路径,从初始状态开始逐位确定答案。
最小循环移位
问题.给定字符串S,找到和它循环同构的字典序最小字符串。
复杂度要求.O(length(S)).
算法.我们将字符串S+S建立后缀自动机。该自动机将包含和S循环同构的所有字符串。
从而,问题就简化成了在自动机中找出字典序最小的,长度为length(S)的路径,这很简单:从初始状态开始,每一步都贪心地走,经过最小的转移。
出现次数查询
问题.给定文本T,询问格式如下:给定字符串P,希望找出P作为子串在文本T中出现了多少次(出现区间可以相交)。
复杂度要求.预处理O(length(T)),单次询问O(length(P)).
算法.我们将文本T建立后缀自动机。
然后我们需要进行预处理:对自动机中的每个状态v都计算cnt[v],等于其endpos(v)集合的大小。事实上,所有在T中对应同一状态的字符串都在T中出现了相同次数,该次数等于endpos中的位置数。
不过,我们无法对所有状态明确记录endpos集合,所以我们只计算其大小cnt.
为了实现这一点,如下处理。对每个状态,如果它不是由“拷贝”而来,最初就赋值cnt=1.然后我们按长度len降序遍历所有序列,并将当前的cnt[v]加给后缀链接:
cnt[link(v)]+=cnt[v].
你可能会说我们并没有对每个状态计算出了正确的cnt值。
为什么这是对的?不经“拷贝”而来的状态恰好有length(S)个,而且其中的第i个是我们添加第i个字符时得到的。因此,最初这些状态的cnt=1,其他状态的cnt=0.
然后我们对每个状态v执行如下操作:cnt[link(v)]+=cnt[v].其意义在于,如果某字符串对应状态v,曾在cnt[v]中出现过,那么它的所有后缀都同样在其中出现。
这样,我们就掌握了如何对自动机中所有状态计算cnt值的方法。
在此之后,询问的答案就变得平凡——只需要返回cnt[t],其中t是模式串P所对应的状态。
首次出现位置查询
问题.给定文本T,询问格式如下:给定字符串P,求P在文本中第一次出现的位置。
复杂度要求.预处理O(length(T)),单次询问O(length(P)).
算法.对文本T建立后缀自动机。
为了解决这一问题,我们需要预处理firstpos,找到自动机中所有状态的出现位置,即,对每个状态v我们希望找到一个位置firstpos[v],代表其第一次出现的位置。换句话说,我们希望预先找出每个endpos(v)中的最小元素(我们无法明确记录整个endpos集合)。
维护这些firstpos的最简单方法是在构建自动机时一并计算,当我们创建新的状态cur时,一旦进入函数sa_extend(),就确定该值:
firstpos(cur)=len(cur)-1
(如果我们的下标从0开始)。
当拷贝节点q时,令:
firstpos(clone)=firstpos(q),
(因为只有一个别的可能值——firstpos(cur),显然更大)。
这样就得到了查询的答案——firstpos(t)-length(P)+1,其中t是模式串P对应的状态。
所有出现位置查询
问题.给定文本T,询问格式如下:给定字符串P,要求给出P在T中的所有出现位置(出现区间可以相交)。
复杂度要求.预处理O(length(T))。单次询问O(length(P)+answer(P)),其中answer(P)是答案集合的大小,即,要求时间复杂度和输入输出同阶。
算法.对文本T建立后缀自动机,和上一个问题相似,在构建自动机的过程中对每个状态计算第一次出现的终点firstpos。
假设我们收到了一个询问——字符串P。我们找到了它对应的状态t。
显然应当返回firstpos(t)。还有哪些位置?我们考虑自动机中那些包含了字符串P的状态,即那些P是其后缀的状态。
换言之,我们需要找出所有能通过后缀链接到达状态t的状态。
因此,为了解决这一问题,我们需要对每个节点储存指向它的所有后缀链接。为了找到答案,我们需要沿着这些翻转的后缀链接进行DFS/BFS,从状态t开始。
这一遍历将在O(answer(P))时间内结束,因为我们不会访问同一状态两次(因为每个状态的后缀链接仅指向一个点,因此不可能有两条路径通往同一状态)。
然而,两个状态的firstpos值可能会相同,如果一个状态是由另一个拷贝而来。但这不会影响渐进复杂度,因为每个非拷贝得到的节点只会有一个拷贝。
此外,你可以轻松地除去那些重复的位置,如果我们不考虑那些拷贝得来的状态的firstpos。事实上,所有拷贝得来的状态都被其“母本”状态的后缀链接指向。因此,我们对每个节点记录标签is_clon,我们不考虑那些is_clon=true的状态的firstpos。这样我们就得到了answer(P)个不重复地状态。
给出一个离线版本的实现:
struct state {
...
bool is_clon;
int first_pos;
vector<int> inv_link;
};
... 后缀自动机构建完毕 ...
for (int v=1; v<sz; ++v)
st[st[v].link].inv_link.push_back (v);
...
// 回答询问——返回所有的出现位置(出现区间可能有重叠)
void output_all_occurences (int v, int P_length) {
if (! st[v].is_clon)
cout << st[v].first_pos - P_length + 1 << endl;
for (size_t i=0; i<st[v].inv_link.size(); ++i)
output_all_occurences (st[v].inv_link[i], P_length);
}
查询不在文本中出现的最短字符串
问题.给定字符串S和字母表。要求找出一个长度最短的字符串,使得它不是S的子串。
复杂度要求.O(length(S)).
算法.在字符串S的后缀自动机上进行动态规划。
令d[v]为节点v的答案,即,我们已经输入了字符串的一部分,匹配到v,我们希望找出有待添加的最少字符数量,以到达一个不存在的转移。
计算d[v]非常简单。如果在v处某个转移不存在,那么d[v]=1:用这个字符来“跳出”自动机,以得到所求字符串。
否则,一个字符串无法达到要求,因此我们必须取所有字符中的最小答案:
原问题的答案等于d[t_0],而所求字符串可以用记录转移路径的方法得到。
求两个字符串的最长公共子串
问题.给定两个字符串S和T。要求找出它们的最长公共子串,即一个字符串X,它同时是S和T的子串。
复杂度要求.O(length(S)+length(T)).
算法.我们对字符串S建立后缀自动机。
我们按照字符串T在自动机上走,查找它每个前缀在S中出现过的最长后缀。换句话说,对字符串T中的每个位置,我们都想找出S和T在该位置结束的最长公共子串。
为了实现这一点,我们定义两个变量:当前状态v和当前长度l。这两个变量描述了当前的匹配部分:其长度和状态,对应哪个字符串(如果不储存长度就无法确定这一点,因为一个状态可能匹配多个有不同长度的字符串)。
最初,p=t_0,l=0,即,匹配部分为空。
现在我们考虑字符T[i],我们希望找到这个位置的答案。
- 如果自动机中的状态v有一个符号T[i]的转移,我们可以简单地走这个转移,然后将长度l加一。
- 如果状态v没有该转移,我们应当尝试缩短当前匹配部分,为此应当沿着后缀链接走:
v=link(v).
在此情况下,当前匹配长度必须被减少,但留下的部分尽可能多。显然,应令l=len(v):
l=len(v).
若新到达的状态仍然没有我们想要的转移,那我们必须再次沿着后缀链接走,并且减少l的值,直到我们找到一个转移(那就返回第一步),或者我们最终到达了空状态-1(这意味着字符T[i]并未在S中出现,所以令v=l=0然后继续处理下一个i)。
原问题的答案就是l曾经达到的最大值。
这种遍历方法的渐进复杂度是O(length(T)),因为在一次移动中我们要么将l加一,要么沿着后缀链接走了若干次,每次都会严格减少l。因此,l总共的减少值之和不可能超过length(T),这意味着线性时间复杂度。
代码实现:
string lcs (string s, string t) {
sa_init();
for (int i=0; i<(int)s.length(); ++i)
sa_extend (s[i]);
int v = 0, l = 0,
best = 0, bestpos = 0;
for (int i=0; i<(int)t.length(); ++i) {
while (v && ! st[v].next.count(t[i])) {
v = st[v].link;
l = st[v].length;
}
if (st[v].next.count(t[i])) {
v = st[v].next[t[i]];
++l;
}
if (l > best)
best = l, bestpos = i;
}
return t.substr (bestpos-best+1, best);
}
多个字符串的最长公共子串
问题.给出K个字符串S_1~S_K。要求找出它们的最长公共子串,即一个字符串X,它是所有S_i的子串。
复杂度要求.O(∑length(S_I)*K).
算法.将所有S_i连接在一起成为一个新的字符串T,其中每个S_i后要加上一个不同的分隔符D_i(即加上K个额外的不同特殊字符D_1~D_K):
我们对字符串T构建后缀自动机。
现在我们需要在后缀自动机找出一个字符串,它是所有字符串S_i的子串。注意到如果一个子串在某个字符串S_j中出现过,那么后缀自动机中存在一条以这个子串为前缀的路径,包含分隔符D_j,但不包含其他分隔符D_1,...,D_j-1,D_j+1,...,D_k。
因此,我们需要计算“可达性”:对自动机中的每个状态和每个字符D_i,计算是否有一条从该状态开始的路径,包含分隔符D_i,但不包含别的分隔符。很容易用DFS/BFS或者动态规划实现。在此之后,原问题的答案就是字符串longest(v),其中v能够到达所有的分隔符。
OJ上的题目
可以用后缀自动机解决的题目:
- SPOJ#7258 SUBLEX "Lexicographical Substring Search"
参考文献
我们首先给出和后缀自动机有关的一些第一手研究:
- A. Blumer, J. Blumer, A. Ehrenfeucht, D. Haussler, R. McConnell.Linear Size Finite Automata for the Set of All Subwords of a Word. An Outline of Results [1983]
- A. Blumer, J. Blumer, A. Ehrenfeucht, D. Haussler.The Smallest Automaton Recognizing the Subwords of a Text[1984]
- Maxime Crochemore. Optimal Factor Transducers [1985]
- Maxime Crochemore. Transducers and Repetitions [1986]
- A. Nerode. Linear automaton transformations [1958]
此外,还有一些当代资源,这一主题在许多有关字符串算法的书籍中被提到:
- Maxime Crochemore, Wowjcieh Rytter. Jewels of Stringology [2002]
- Bill Smyth. Computing Patterns in Strings [2003]
- Билл Смит. Методы и алгоритмы вычислений на строках [2006]