spark-streaming系列------- 4. Spark-Streaming Job的生成和执行
Spark-Streaming Job的生成和执行可以通过如下图表示:
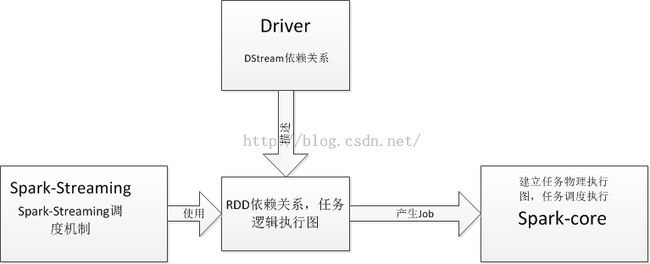
Spark-Streaming Job的生产和和执行由以下3个部分相互作用生成:
Driver程序:用户通过编写Driver程序描述了DStream的依赖关系,Driver程序根据DStream描述的依赖关系描述了RDD的依赖关系,也就是描述了Streaming Job的逻辑执行图
Spark-Streaming模块:根据Driver程序描述的Streaming Job的逻辑执行图,调度和产生Job
Spark-core模块:根据Job中的逻辑执行图指定任务物理执行图,将Spark-Streaming Job分解成Task,分配给各个Executor实际执行Spark-Streaming Job
本篇文章以如下代码为例,说明以上3个部分是如何执行Spark-Streaming Job的
<pre name="code" class="java">package spark_security.login_users
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.immutable.HashSet
/**
* Created by on 2015/10/28.
*/
object DStreamExample {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("example")
/*
* 创建StreamingContext,在这个对象里面会创建DStreamGraph对象
* */
val ssc = new StreamingContext(sparkConf, Seconds(1))
val kafkaParams = Map[String, String](
"metadata.broker.list" -> "1.1.1.1",
"group.id" -> "123",
"auto.offset.reset" -> "smallest"
)val topicsSet = HashSet("test")
/*
* 创建InputDStream,并且将这个InputDStream加入到DStreamGraph.inputStreams数组中
* */
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
/*
* 创建MappedDStream
* */
val message2 = messages.map(line => line + "111")
.filter(line => line.length > 10)
/*
* 将上述建立的InputDStream拷贝后加入到DStreamGraph.outputStreams
* */
message2.foreachRDD(rdd =>
/*
* 这个方法将Streaming Job提交到Spark-core任务调度模块实际执行
* */
rdd.collect
)
ssc.start()//开始进入Spark-Streaming任务调度,产生Spark-Streaming Job
ssc.awaitTermination()
}
}
Driver首先创建StreamingContext对象,在创建这个对象的时候,会创建DStreamGraph对象,DStreamGraph对象描述了如何创建Streaming Job
Spark-Streaming要处理的DStream首先放在输入流里面,当需要输出的时候(也就是创建Spark-Streaming Job的时候),会将输入流中的DStream放到输出流中。在Spark1.5,只有DStream.foreachRDD会触发将输入流中的DStream放到输出流。DStream.foreachRDD代码如下:
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit = ssc.withScope {
// because the DStream is reachable from the outer object here, and because
// DStreams can't be serialized with closures, we can't proactively check
// it for serializability and so we pass the optional false to SparkContext.clean
new ForEachDStream(this, context.sparkContext.clean(foreachFunc, false)).register()
}
private[streaming] def register(): DStream[T] = {
ssc.graph.addOutputStream(this)//将InputStream中的DStream加入到OutputStream
this
}
DStreamGraph.inputStreams表示输入流,DStreamGraph.outputStreams表示输出流。并且DStream.foreachRDD会创建ForEachDStream对象,这个类的定义为:
<pre name="code" class="java">
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit
) extends DStream[Unit](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] = {
/*
* 计算出已经包含依赖关系的RDD,依赖关系在驱动程序执行的时候建立,
* parent.getOrCompute会调用parent.compute方法,由于DStream的所有子类都没有重写getOrCompute方法,但是重写了compute方法,
* 所以parent.getOrCompute方法调用的是DStream.getOrCompute方法,DStream.getOrCompute方法会调用各个DStream子类(比如MappedDStream)的compute方法
* 这样RDD和DStream的依赖关系就建立起来了
* 在这里foreachFunc并没有实际执行,而是定义了jobFunc方法,jobFunc方法里面会调用foreachFunc
* */
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time) {
ssc.sparkContext.setCallSite(creationSite)
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
}
在例子程序中,创建Kafka DirectDStream作为InputStream,它是root DStream,所以它的Parent为Nil。
例子中
messages.map(line => line + "111")的作用是创建MappedDStream,DStream.map定义如下:
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope {
new MappedDStream(this, context.sparkContext.clean(mapFunc))
}
可见创建的MappedDStream的parent DStream为messages
MappedDStream的定义为:
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
//这个方法在创建Spark-Streaming Job的时候会执行
override def compute(validTime: Time): Option[RDD[U]] = {
/*
* 根据时间创建RDD,然后调用RDD.map方法创建MapPartition,RDD的依赖关系在调用RDD.map的时候建立了
* */
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}
}MappedDStream.compute方法在产生Spark-Streaming Job的时候会执行,生成RDD,然后执行RDD.map[U](mapFunc)方法,创建MapPartitionsRDD,这个时候也就创建了RDD的依赖关系。
message2.foreachRDD(rdd =>
/*
* 这个方法将Streaming Job提交到Spark-core任务调度模块实际执行
* */
rdd.collect
)这段代码将DStream从DStreamGraph.InputStreams加入到DStreamGraph.outputStreams
Spark-Streaming Job的RDD逻辑执行图到现在为止已经描述完毕,之后执行如下语句:
ssc.start()//开始进入Spark-Streaming任务调度,产生Spark-Streaming Job进入Spark-Streaming任务调度模块,在上面例子中1s中产生一个Spark-Streaming Job
Spark-Streaming任务调度模块会定时产生Job,JobGenerator.generateJobs方法通过调用DStreamGraph.generateJobs产生Job, 通过调用JobScheduler.submitJobSet启动一个线程执行Job.run方法。
DStreamGraph.generateJobs源码如下:
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
/*
* 根据outputStreams产生Job,执行DStream.foreachRDD才会把一条inputstream拷贝一份到outputStream
* 在这里outputStream的类型是ForEachDStream
* */
outputStreams.flatMap(outputStream => outputStream.generateJob(time))
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
前面已经讲到,在spark1.5中,只有执行DStream.foreachRDD才会把一条inputstream加入到outputStreams,在执行DStream.foreachRDD先创建ForEachDStream,然后把ForEachDStream加入到outputStreams,所以这里产生Job是调用了ForEachDStream.generateJob。
ForEachDStream.generateJob计算出Job要处理的最终RDD, 这个RDD能够根据依赖关系找到它的所有祖宗RDD,以及不同祖宗级别上的RDD以及RDD和它的parent rdd之间的转化函数,parent.getOrCompute会调用parent.compute方法,由于DStream的所有子类都没有重写getOrCompute方法,但是重写了compute方法,所以parent.getOrCompute方法调用的是DStream.getOrCompute方法,DStream.getOrCompute方法会调用各个DStream子类(比如MappedDStream,见上述代码)的compute方法。
ForEachDStream.generateJob源码如下:
override def generateJob(time: Time): Option[Job] = {
/*
* 计算出Job要处理的最终RDD, 这个RDD能够根据依赖关系找到它的所有祖宗RDD,以及不同祖宗级别上的RDD已经RDD和它的parent rdd之间的转化函数
* parent.getOrCompute会调用parent.compute方法,由于DStream的所有子类都没有重写getOrCompute方法,但是重写了compute方法,
* 所以parent.getOrCompute方法调用的是DStream.getOrCompute方法,DStream.getOrCompute方法会调用各个DStream子类(比如MappedDStream)的compute方法
* parent.getOrCompute调用是一个调用链,调用链第一个执行的根RDD,通过执行调用链表,RDD与RDD间、DStream和DStream间的依赖关系就建立起来了
* 在这里foreachFunc并没有实际执行,而是定义了jobFunc方法,jobFunc方法里面会调用foreachFunc
* */
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time) {
ssc.sparkContext.setCallSite(creationSite)
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
总之,parent.getOrCompute调用是一个调用链,调用链第一个执行的根RDD的转换方法,通过执行调用链表,RDD与RDD间、DStream和DStream间的依赖关系就建立起来了,在这里foreachFunc并没有实际执行,而是定义了jobFunc方法,jobFunc方法里面会调用foreachFunc。
根据以上分析得出结论,Spark-Streaming Job包括2部分,第一部分是Job要处理的最终RDD,第二部分是对RDD进行处理的函数调用链
JobScheduler.submitJobSet方法启动一个线程,执行ForEachDStream.generateJob方法产生Job中的jobFunc方法,jobFunc方法对RDD进行处理,在本篇文章中是执行RDD.collect方法,这个方法的执行会触发Spark-core的任务调度,将Spark-Streaming分解成Task,为Spark-Streaming Job分配集群资源,最终各个Executor开始执行Task
JobScheduler.submitJobSet方法定义如下:
def submitJobSet(jobSet: JobSet) {
if (jobSet.jobs.isEmpty) {
logInfo("No jobs added for time " + jobSet.time)
} else {
listenerBus.post(StreamingListenerBatchSubmitted(jobSet.toBatchInfo))
jobSets.put(jobSet.time, jobSet)
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
logInfo("Added jobs for time " + jobSet.time)
}
}