Spark 1.2 Standalone Mode 单机安装
1:spark下载,解压
[jifeng@jifeng01 hadoop]$ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop1.tgz --2015-02-03 21:50:25-- http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop1.tgz 正在解析主机 d3kbcqa49mib13.cloudfront.net... 54.192.150.88, 54.230.149.156, 54.230.150.31, ... Connecting to d3kbcqa49mib13.cloudfront.net|54.192.150.88|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:203977086 (195M) [application/x-compressed] Saving to: `spark-1.2.0-bin-hadoop1.tgz' 100%[===========================================================================>] 203,977,086 410K/s in 7m 55s 2015-02-03 21:58:21 (419 KB/s) - `spark-1.2.0-bin-hadoop1.tgz' saved [203977086/203977086]
[jifeng@jifeng01 hadoop]$ tar zxf spark-1.2.0-bin-hadoop1.tgz
在jifeng04下载并复制到jifeng01
[jifeng@jifeng04 hadoop]$ wget http://downloads.typesafe.com/scala/2.11.4/scala-2.11.4.tgz?_ga=1.248348352.61371242.1418807768 --2015-02-03 21:55:35-- http://downloads.typesafe.com/scala/2.11.4/scala-2.11.4.tgz?_ga=1.248348352.61371242.1418807768 正在解析主机 downloads.typesafe.com... 54.230.151.79, 54.230.151.80, 54.230.151.162, ... Connecting to downloads.typesafe.com|54.230.151.79|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:26509669 (25M) [application/octet-stream] Saving to: `scala-2.11.4.tgz?_ga=1.248348352.61371242.1418807768' 100%[===========================================================================>] 26,509,669 320K/s in 71s 2015-02-03 21:56:48 (366 KB/s) - `scala-2.11.4.tgz?_ga=1.248348352.61371242.1418807768' saved [26509669/26509669] [jifeng@jifeng04 hadoop]$ ls hadoop-1.2.1 scala-2.11.4.tgz?_ga=1.248348352.61371242.1418807768 tmp [jifeng@jifeng04 hadoop]$ mv scala-2.11.4.tgz\?_ga\=1.248348352.61371242.1418807768 scala-2.11.4.tgz [jifeng@jifeng04 hadoop]$ tar zxf scala-2.11.4.tgz [jifeng@jifeng04 hadoop]$ ls hadoop-1.2.1 scala-2.11.4 scala-2.11.4.tgz tmp [jifeng@jifeng04 hadoop]$ scp ./scala-2.11.4.tgz [email protected]:/home/jifeng/hadoop scala-2.11.4.tgz 100% 25MB 25.3MB/s 00:01 [jifeng@jifeng04 hadoop]$
jifeng01 解压
[jifeng@jifeng01 hadoop]$ tar zxf scala-2.11.4.tgz
3:配置scala
配置scala环境变量
export SCALA_HOME=$HOME/hadoop/scala-2.11.4
export PATH=$PATH:$ANT_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$SCALA_HOME/bin
[jifeng@jifeng01 ~]$ vi ~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=$HOME/jdk1.7.0_45
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=$HOME/hadoop/hadoop-1.2.1
export HADOOP_CONF_DIR=$HOME/hadoop/hadoop-1.2.1/conf
export ANT_HOME=$HOME/apache-ant-1.9.4
export HBASE_HOME=$HOME/hbase-0.94.21
export SQOOP_HOME=$HOME/sqoop-1.99.3-bin-hadoop100
export CATALINA_HOME=$SQOOP_HOME/server
export LOGDIR=$SQOOP_HOME/logs
export MAHOUT_HOME=$HOME/hadoop/mahout-distribution-0.9
export MAHOUT_CONF_DIR=$HOME/hadoop/mahout-distribution-0.9/conf
export SCALA_HOME=$HOME/hadoop/scala-2.11.4
export PATH=$PATH:$ANT_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$SCALA_HOME/bin
~
~
".bash_profile" 28L, 889C 已写入
[jifeng@jifeng01 ~]$ source ~/.bash_profile
source ~/.bash_profile 配置文件马上生效
查看版本
[jifeng@jifeng01 hadoop]$ scala -version Scala code runner version 2.11.4 -- Copyright 2002-2013, LAMP/EPFL
[jifeng@jifeng01 hadoop]$ scala Welcome to Scala version 2.11.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45). Type in expressions to have them evaluated. Type :help for more information. scala>
4:配置spark环境变量
加入环境变量
export SPARK_HOME=$HOME/hadoop/spark-1.2.0-bin-hadoop1
export PATH=$PATH:$SPARK_HOME/bin
[jifeng@jifeng01 ~]$ vi ~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=$HOME/jdk1.7.0_45
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=$HOME/hadoop/hadoop-1.2.1
export HADOOP_CONF_DIR=$HOME/hadoop/hadoop-1.2.1/conf
export ANT_HOME=$HOME/apache-ant-1.9.4
export HBASE_HOME=$HOME/hbase-0.94.21
export SQOOP_HOME=$HOME/sqoop-1.99.3-bin-hadoop100
export CATALINA_HOME=$SQOOP_HOME/server
export LOGDIR=$SQOOP_HOME/logs
export MAHOUT_HOME=$HOME/hadoop/mahout-distribution-0.9
export MAHOUT_CONF_DIR=$HOME/hadoop/mahout-distribution-0.9/conf
export SCALA_HOME=$HOME/hadoop/scala-2.11.4
export SPARK_HOME=$HOME/hadoop/spark-1.2.0-bin-hadoop1
export PATH=$PATH:$ANT_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$SCALA_HOME/bin
export PATH=$PATH:$SPARK_HOME/bin
".bash_profile" 30L, 978C 已写入
[jifeng@jifeng01 ~]$ source ~/.bash_profile
5:配置spark
复制配置文件 cp spark-env.sh.template spark-env.sh
[jifeng@jifeng01 ~]$ cd hadoop [jifeng@jifeng01 hadoop]$ cd spark-1.2.0-bin-hadoop1 [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ ls bin conf data ec2 examples lib LICENSE NOTICE python README.md RELEASE sbin [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ cd conf [jifeng@jifeng01 conf]$ ls fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template log4j.properties.template slaves.template spark-env.sh.template [jifeng@jifeng01 conf]$ cp spark-env.sh.template spark-env.sh
在spark-env.sh最后添加下面
export SCALA_HOME=/home/jifeng/hadoop/scala-2.11.4
export SPARK_MASTER_IP=jifeng01.sohudo.com
export SPARK_WORKER_MEMORY=2G
export JAVA_HOME=/home/jifeng/jdk1.7.0_45
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
export SCALA_HOME=/home/jifeng/hadoop/scala-2.11.4
export SPARK_MASTER_IP=jifeng01.sohudo.com
export SPARK_WORKER_MEMORY=2G
export JAVA_HOME=/home/jifeng/jdk1.7.0_45
"spark-env.sh" 54L, 3378C 已写入
[jifeng@jifeng01 conf]$ cd ..
6:启动
[jifeng@jifeng01 sbin]$ cd .. [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.master.Master-1-jifeng01.sohudo.com.out
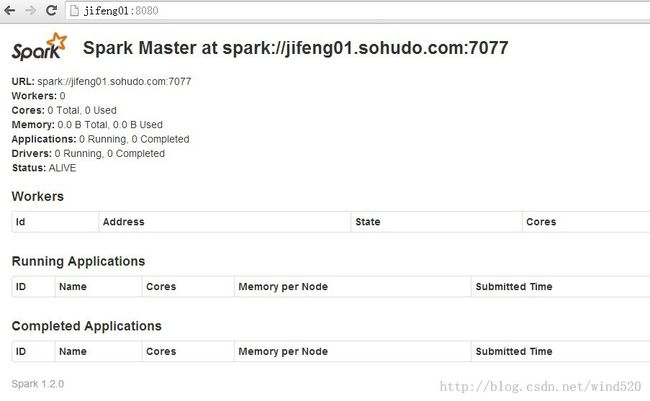
7:启动worker
sbin/start-slaves.sh park://jifeng01:7077
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-slaves.sh park://jifeng01:7077 localhost: Warning: Permanently added 'localhost' (RSA) to the list of known hosts. localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.worker.Worker-1-jifeng01.sohudo.com.out [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-slaves.sh park://jifeng01.sohudo.com:7077 localhost: org.apache.spark.deploy.worker.Worker running as process 10273. Stop it first. [jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$
看界面的变化
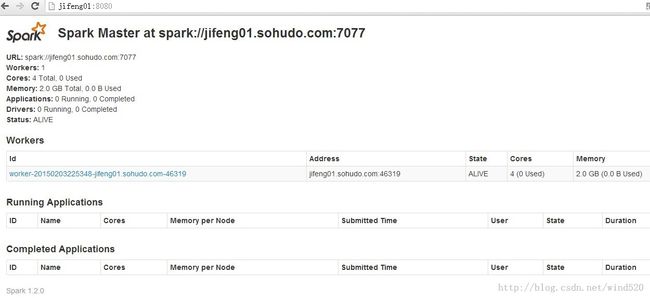
8:测试
进入交互模式
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ master=spark://jifeng01.sohudo.com:7077 ./bin/spark-shell Spark assembly has been built with Hive, including Datanucleus jars on classpath 15/02/03 23:05:32 INFO spark.SecurityManager: Changing view acls to: jifeng 15/02/03 23:05:32 INFO spark.SecurityManager: Changing modify acls to: jifeng 15/02/03 23:05:32 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng) 15/02/03 23:05:32 INFO spark.HttpServer: Starting HTTP Server 15/02/03 23:05:32 INFO server.Server: jetty-8.y.z-SNAPSHOT 15/02/03 23:05:32 INFO server.AbstractConnector: Started [email protected]:46617 15/02/03 23:05:32 INFO util.Utils: Successfully started service 'HTTP class server' on port 46617. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.2.0 /_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45) Type in expressions to have them evaluated. Type :help for more information. 15/02/03 23:05:36 INFO spark.SecurityManager: Changing view acls to: jifeng 15/02/03 23:05:36 INFO spark.SecurityManager: Changing modify acls to: jifeng 15/02/03 23:05:36 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng) 15/02/03 23:05:37 INFO slf4j.Slf4jLogger: Slf4jLogger started 15/02/03 23:05:37 INFO Remoting: Starting remoting 15/02/03 23:05:37 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:41533] 15/02/03 23:05:37 INFO util.Utils: Successfully started service 'sparkDriver' on port 41533. 15/02/03 23:05:37 INFO spark.SparkEnv: Registering MapOutputTracker 15/02/03 23:05:37 INFO spark.SparkEnv: Registering BlockManagerMaster 15/02/03 23:05:37 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20150203230537-f1cb 15/02/03 23:05:37 INFO storage.MemoryStore: MemoryStore started with capacity 265.4 MB 15/02/03 23:05:37 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-0e198e02-fea8-49df-a1ab-8dd08e988cab 15/02/03 23:05:37 INFO spark.HttpServer: Starting HTTP Server 15/02/03 23:05:37 INFO server.Server: jetty-8.y.z-SNAPSHOT 15/02/03 23:05:37 INFO server.AbstractConnector: Started [email protected]:52156 15/02/03 23:05:37 INFO util.Utils: Successfully started service 'HTTP file server' on port 52156. 15/02/03 23:05:38 INFO server.Server: jetty-8.y.z-SNAPSHOT 15/02/03 23:05:38 INFO server.AbstractConnector: Started [email protected]:4040 15/02/03 23:05:38 INFO util.Utils: Successfully started service 'SparkUI' on port 4040. 15/02/03 23:05:38 INFO ui.SparkUI: Started SparkUI at http://jifeng01.sohudo.com:4040 15/02/03 23:05:38 INFO executor.Executor: Using REPL class URI: http://10.5.4.54:46617 15/02/03 23:05:38 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://[email protected]:41533/user/HeartbeatReceiver 15/02/03 23:05:38 INFO netty.NettyBlockTransferService: Server created on 39115 15/02/03 23:05:38 INFO storage.BlockManagerMaster: Trying to register BlockManager 15/02/03 23:05:38 INFO storage.BlockManagerMasterActor: Registering block manager localhost:39115 with 265.4 MB RAM, BlockManagerId(<driver>, localhost, 39115) 15/02/03 23:05:38 INFO storage.BlockManagerMaster: Registered BlockManager 15/02/03 23:05:38 INFO repl.SparkILoop: Created spark context.. Spark context available as sc. scala>
测试
输入命令:
val file=sc.textFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt")
val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
count.collect()
scala> val file=sc.textFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt")
15/02/03 23:07:25 INFO storage.MemoryStore: ensureFreeSpace(32768) called with curMem=0, maxMem=278302556
15/02/03 23:07:25 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 32.0 KB, free 265.4 MB)
15/02/03 23:07:25 INFO storage.MemoryStore: ensureFreeSpace(5070) called with curMem=32768, maxMem=278302556
15/02/03 23:07:25 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 5.0 KB, free 265.4 MB)
15/02/03 23:07:25 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:39115 (size: 5.0 KB, free: 265.4 MB)
15/02/03 23:07:25 INFO storage.BlockManagerMaster: Updated info of block broadcast_0_piece0
15/02/03 23:07:25 INFO spark.SparkContext: Created broadcast 0 from textFile at <console>:12
file: org.apache.spark.rdd.RDD[String] = hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt MappedRDD[1] at textFile at <console>:12
scala> val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
15/02/03 23:07:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/02/03 23:07:38 WARN snappy.LoadSnappy: Snappy native library not loaded
15/02/03 23:07:38 INFO mapred.FileInputFormat: Total input paths to process : 1
count: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:14
scala> count.collect()
15/02/03 23:07:44 INFO spark.SparkContext: Starting job: collect at <console>:17
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Registering RDD 3 (map at <console>:14)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Got job 0 (collect at <console>:17) with 3 output partitions (allowLocal=false)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Final stage: Stage 1(collect at <console>:17)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Parents of final stage: List(Stage 0)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Missing parents: List(Stage 0)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Submitting Stage 0 (MappedRDD[3] at map at <console>:14), which has no missing parents
15/02/03 23:07:44 INFO storage.MemoryStore: ensureFreeSpace(3584) called with curMem=37838, maxMem=278302556
15/02/03 23:07:44 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.5 KB, free 265.4 MB)
15/02/03 23:07:44 INFO storage.MemoryStore: ensureFreeSpace(2543) called with curMem=41422, maxMem=278302556
15/02/03 23:07:44 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.5 KB, free 265.4 MB)
15/02/03 23:07:44 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:39115 (size: 2.5 KB, free: 265.4 MB)
15/02/03 23:07:44 INFO storage.BlockManagerMaster: Updated info of block broadcast_1_piece0
15/02/03 23:07:44 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:838
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Submitting 3 missing tasks from Stage 0 (MappedRDD[3] at map at <console>:14)
15/02/03 23:07:44 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 3 tasks
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 1310 bytes)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, ANY, 1310 bytes)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, ANY, 1310 bytes)
15/02/03 23:07:44 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
15/02/03 23:07:44 INFO executor.Executor: Running task 2.0 in stage 0.0 (TID 2)
15/02/03 23:07:44 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
15/02/03 23:07:44 INFO rdd.HadoopRDD: Input split: hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt:6+6
15/02/03 23:07:44 INFO rdd.HadoopRDD: Input split: hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt:0+6
15/02/03 23:07:44 INFO rdd.HadoopRDD: Input split: hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt:12+1
15/02/03 23:07:44 INFO executor.Executor: Finished task 2.0 in stage 0.0 (TID 2). 1897 bytes result sent to driver
15/02/03 23:07:44 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1897 bytes result sent to driver
15/02/03 23:07:44 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1897 bytes result sent to driver
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 164 ms on localhost (1/3)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 160 ms on localhost (2/3)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 160 ms on localhost (3/3)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Stage 0 (map at <console>:14) finished in 0.185 s
15/02/03 23:07:44 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/02/03 23:07:44 INFO scheduler.DAGScheduler: looking for newly runnable stages
15/02/03 23:07:44 INFO scheduler.DAGScheduler: running: Set()
15/02/03 23:07:44 INFO scheduler.DAGScheduler: waiting: Set(Stage 1)
15/02/03 23:07:44 INFO scheduler.DAGScheduler: failed: Set()
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Missing parents for Stage 1: List()
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Submitting Stage 1 (ShuffledRDD[4] at reduceByKey at <console>:14), which is now runnable
15/02/03 23:07:44 INFO storage.MemoryStore: ensureFreeSpace(2112) called with curMem=43965, maxMem=278302556
15/02/03 23:07:44 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.1 KB, free 265.4 MB)
15/02/03 23:07:44 INFO storage.MemoryStore: ensureFreeSpace(1546) called with curMem=46077, maxMem=278302556
15/02/03 23:07:44 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1546.0 B, free 265.4 MB)
15/02/03 23:07:44 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:39115 (size: 1546.0 B, free: 265.4 MB)
15/02/03 23:07:44 INFO storage.BlockManagerMaster: Updated info of block broadcast_2_piece0
15/02/03 23:07:44 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:838
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Submitting 3 missing tasks from Stage 1 (ShuffledRDD[4] at reduceByKey at <console>:14)
15/02/03 23:07:44 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 3 tasks
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 3, localhost, PROCESS_LOCAL, 1056 bytes)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 1.0 (TID 4, localhost, PROCESS_LOCAL, 1056 bytes)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 1.0 (TID 5, localhost, PROCESS_LOCAL, 1056 bytes)
15/02/03 23:07:44 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 3)
15/02/03 23:07:44 INFO executor.Executor: Running task 2.0 in stage 1.0 (TID 5)
15/02/03 23:07:44 INFO executor.Executor: Running task 1.0 in stage 1.0 (TID 4)
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Getting 0 non-empty blocks out of 3 blocks
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 3 blocks
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Getting 0 non-empty blocks out of 3 blocks
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 8 ms
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 7 ms
15/02/03 23:07:44 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 8 ms
15/02/03 23:07:44 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 3). 820 bytes result sent to driver
15/02/03 23:07:44 INFO executor.Executor: Finished task 2.0 in stage 1.0 (TID 5). 820 bytes result sent to driver
15/02/03 23:07:44 INFO executor.Executor: Finished task 1.0 in stage 1.0 (TID 4). 990 bytes result sent to driver
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 3) in 44 ms on localhost (1/3)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 1.0 (TID 5) in 44 ms on localhost (2/3)
15/02/03 23:07:44 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 1.0 (TID 4) in 45 ms on localhost (3/3)
15/02/03 23:07:44 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Stage 1 (collect at <console>:17) finished in 0.048 s
15/02/03 23:07:44 INFO scheduler.DAGScheduler: Job 0 finished: collect at <console>:17, took 0.366077 s
res0: Array[(String, Int)] = Array((hadoop,1), (hello,1))
scala>
看到控制台有如下结果:res0: Array[(String, Int)] = Array((hadoop,1), (hello,1))
同时也可以将结果保存到HDFS上
scala>count.saveAsTextFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/out/test1.txt")
9:停止
./sbin/stop-master.sh
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ ./sbin/stop-master.sh stopping org.apache.spark.deploy.master.Master