论文阅读:End-To-End Memory Networks
作者:
Sainbayar Sukhbaatar
Arthur Szlam Jason Weston Rob Fergus
New York University
Facebook AI Research
New York
Follow 的论文:MEMORY NETWORKS, Jason Weston, Sumit Chopra & Antoine Bordes
Facebook AI Research
一、论文所解决的问题
(1)算法层面:
让记忆网络(memory network)End to End地进行训练(究竟怎么end to end的?)
也就是在原始的网络上面加了个softmax,而原始的记忆网络是用的max操作
(2)应用方面:问题回答(比原始记忆网络要好)、语言建模(和RNNs和LSTMs差不多)
二、论文的解决方案
(0)整体架构一览
a图,展示的是具体结构:
输入词向量,one of k coding schema
嵌入矩阵A、B、C
A:d X V 输入的嵌入矩阵
B:d X V 查询的嵌入矩阵
C:d X V 输出的嵌入矩阵
含义:嵌入矩阵是为了映射到同一个空间
------------------------------------------------------------------------------
输入的嵌入向量,用于计算概率
m_i=Ax_i p_i = softmax(u^T m_i)
含义:用查询与输入的嵌入向量的softmax是为了得到每个输入向量的权重,对应的输出与权重相乘得到最终的输出o
输出的嵌入向量
c_i = C out_i
最终输出嵌入向量
o = \sum_{i} p_i c_i
-------------------------------------------------------------------------------
查询的嵌入向量
u=Bq
--------------------------------------------------------------------------------
预测结果
a^{\tilde}=softmax(W(o+u))
带权的求和得到的o与查询的q转换之后的u相加再乘以权重,得到分类
-------------------------------------------------------------------------------
b图,展示的是如何堆叠
如何堆起来
(1)Adjacent
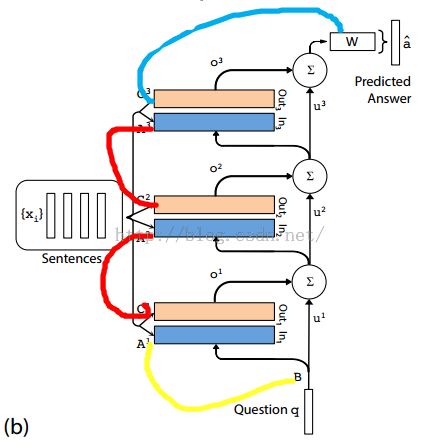
(2)RNN-like
H是一个线性映射矩阵
(1)实现细节:
1)网络的层数
our model makes several hops on the memory before making an output; we will
see below that this is important for good performance
K=3 表示hops的个数,也就是图中的层数
2)句子的表示
①Bow
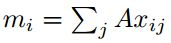
![]()
②Bow with postion
![]()
![]()
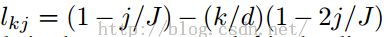
3)时间编码
4)Learning time invariance by injecting random noise: we have found it helpful to add “dummy”
memories to regularize TA. That is, at training time we can randomly add 10% of empty memories
to the stories. We refer to this approach as random noise (RN).
三、论文中的方案解决该问题,解决到了什么程度?
用于NLP的,解决的是序列中的长依赖的学习
四、其他未能考虑的问题
本质上还是一种RNN的变种,只不过是固定长度地递归
五、有什么收获
六、实验
(1)几个数据集可以用
Babi数据集,具体可以看代码
(2)代码
https://github.com/facebook/MemNN