Spark Streaming 第一课:案例动手实战并在电光石火间理解其工作原理
Spark Streaming 第一课:案例动手实战并在电光石火间理解其工作原理
http://spark.apache.org/docs/latest/streaming-programming-guide.html
第一个观点:一切都应该是流处理。无处不在。
一定要做流式处理
Flink生不逢时
你选择Storm唯一的理由就是能够做到毫秒级的响应
2016年DT 大数据梦工厂制定版要把spark streaming 的延迟速度控制在100ms以内. 结果就是流处理Spark Streaming一统天下。
因为:
1.他提供的storm API非常容易实现业务的逻辑
2.数据流尽量可以直接调Spark SQL 或使用图计算以及Spark core.
现在Spark Streaming最大的问题是延迟速度
下一个目标就是控制在50ms以内
下面我们动手实战:
先启动下Spark集群:
我们从集群里面打开下官方网站:
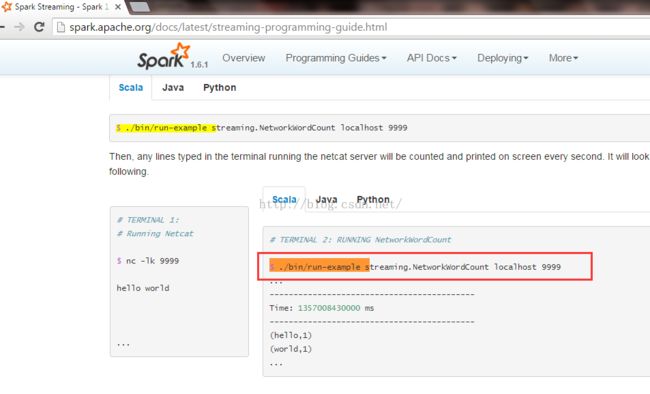
这边就是运行一个streaming的程序:统计这个时间段内流进来的单词出现的次数. 它计算的是:他规定的时间段内每个单词出现了多少次
cd /usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin
$ ./run-example streaming.NetworkWordCount localhost 9999
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
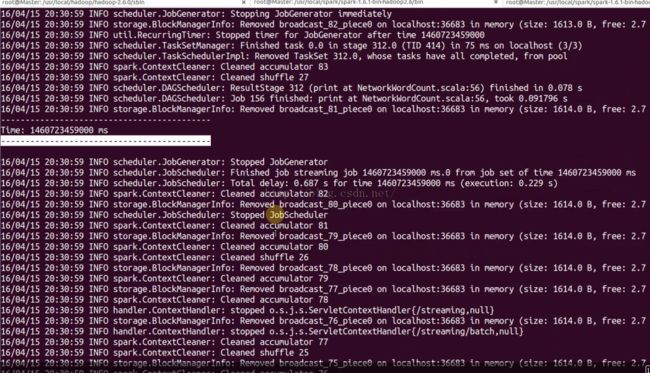
接受这个数据进行加工,就是流处理的过程,刚才那个WordCount就是以1s做一个单位。
刚才运行的时候,为什么没有结果呢?因为需要数据源,
下面我们去获取数据源:

新开一个命令终端,然后输入:
$ nc -lk 9999

现在我们拷贝数据源进入运行:
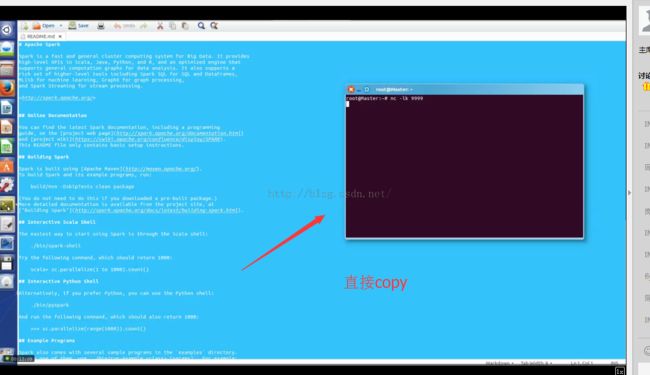
然后按回车运行
他计算的过程和我们讲课的过程是一样的,是一句句去理解的。
Storm天生是一条一条是计算的(基于record内容)
而spark Streaming 处理了大量的多句话构成的数据(基于时间的,和内容无关)
计算的时间是一秒钟
使用storm唯一的理由是为了获得延迟
Spark Streaming也可以一条条处理
Spark Streaming一般和kafka配合
数据可能来自于各种终端,再推给Kafka
流程图:
没有输入数据事打印的是空结果

但是实际上,这个Job是框架帮我们产生的,框架是每隔一秒钟就会产生Job.
这个Spark Streaming 要拿到我们写的WordCount的代码就必须产生?
内心没想:我现在写业务逻辑的数据是想那一秒钟的还是想两天的数据?一定是想当时的一秒钟的数据。
编程的时候想的是RDD的模型,而实际上是每一秒中都产生一个实际的作业Job。Job之所以有实例是因为有RDD实例的产生,也就是说你说的代码是作业的模板。这个模板在特定的时空中就会产生一个实例。这是类和Object的关系。

RDD的模板是DStream,RDD 之间有依赖关系,那DStream也有依赖关系。就构成了DStream 有向无环图。
这个DAG图,是模板,每隔1秒钟产生Job.
Spark Streaming只不过是破了RDD上面一层薄薄的封装而已。
你写的代码不能产生Job,只有框架才能产生Job.
没算完就只能调优了.
