算法——动态规划(分治递归)
前言
本文翻译自TopCoder上的一篇文章: Dynamic Programming: From novice to advanced ,并非严格逐字逐句翻译,其中加入了自己的一些理解。水平有限,还望指摘。
我们遇到的问题中,有很大一部分可以用动态规划(简称DP)来解。 解决这类问题可以很大地提升你的能力与技巧,我会试着帮助你理解如何使用DP来解题。 这篇文章是基于实例展开来讲的,因为干巴巴的理论实在不好理解。
简介
什么是动态规划,我们要如何描述它?
动态规划算法通常基于一个递推公式及一个或多个初始状态。 当前子问题的解将由上一次子问题的解推出。使用动态规划来解题只需要多项式时间复杂度, 因此它比回溯法、暴力法等要快许多。
现在让我们通过一个例子来了解一下DP的基本原理。
首先,我们要找到某个状态的最优解,然后在它的帮助下,找到下一个状态的最优解。
“状态”代表什么及如何找到它?
“状态”用来描述该问题的子问题的解。原文中有两段作者阐述得不太清楚,跳过直接上例子。
入门 最少硬币数
如果我们有面值为1元、3元和5元的硬币若干枚,如何用最少的硬币凑够11元?
(表面上这道题可以用贪心算法,但贪心算法无法保证可以求出解,比如1元换成2元的时候)
首先我们思考一个问题,如何用最少的硬币凑够i元(i<11)?为什么要这么问呢? 两个原因:1.当我们遇到一个大问题时,总是习惯把问题的规模变小,这样便于分析讨论。 2.这个规模变小后的问题和原来的问题是同质的,除了规模变小,其它的都是一样的, 本质上它还是同一个问题(规模变小后的问题其实是原问题的子问题)。
好了,让我们从最小的i开始吧。
当i=0,即我们需要多少个硬币来凑够0元。 由于1,3,5都大于0,即没有比0小的币值,因此凑够0元我们最少需要0个硬币。 (这个分析很傻是不是?别着急,这个思路有利于我们理清动态规划究竟在做些什么。) 这时候我们发现用一个标记来表示这句“凑够0元我们最少需要0个硬币。”会比较方便, 如果一直用纯文字来表述,不出一会儿你就会觉得很绕了。那么, 我们用d(i)=j来表示凑够i元最少需要j个硬币。于是我们已经得到了d(0)=0, 表示凑够0元最小需要0个硬币。
当i=1时,只有面值为1元的硬币可用, 因此我们拿起一个面值为1的硬币,接下来只需要凑够0元即可,而这个是已经知道答案的, 即d(0)=0。所以,d(1)=d(1-1)+1=d(0)+1=0+1=1。
当i=2时, 仍然只有面值为1的硬币可用,于是我拿起一个面值为1的硬币, 接下来我只需要再凑够2-1=1元即可(记得要用最小的硬币数量),而这个答案也已经知道了。 所以d(2)=d(2-1)+1=d(1)+1=1+1=2。一直到这里,你都可能会觉得,好无聊, 感觉像做小学生的题目似的。因为我们一直都只能操作面值为1的硬币!耐心点, 让我们看看i=3时的情况。
当i=3时,我们能用的硬币就有两种了:1元的和3元的( 5元的仍然没用,因为你需要凑的数目是3元!5元太多了亲)。 既然能用的硬币有两种,我就有两种方案。如果我拿了一个1元的硬币,我的目标就变为了: 凑够3-1=2元需要的最少硬币数量。即d(3)=d(3-1)+1=d(2)+1=2+1=3。 这个方案说的是,我拿3个1元的硬币;第二种方案是我拿起一个3元的硬币, 我的目标就变成:凑够3-3=0元需要的最少硬币数量。即d(3)=d(3-3)+1=d(0)+1=0+1=1. 这个方案说的是,我拿1个3元的硬币。好了,这两种方案哪种更优呢? 记得我们可是要用最少的硬币数量来凑够3元的。所以, 选择d(3)=1,怎么来的呢?具体是这样得到的:d(3)=min{d(3-1)+1, d(3-3)+1}。
OK,码了这么多字讲具体的东西,让我们来点抽象的。从以上的文字中, 我们要抽出动态规划里非常重要的两个概念:状态和状态转移方程。
上文中d(i)表示凑够i元需要的最少硬币数量,我们将它定义为该问题的”状态”, 这个状态是怎么找出来的呢?我在另一篇文章 动态规划之背包问题(一)中写过: 根据子问题定义状态。你找到子问题,状态也就浮出水面了。 最终我们要求解的问题,可以用这个状态来表示:d(11),即凑够11元最少需要多少个硬币。 那状态转移方程是什么呢?既然我们用d(i)表示状态,那么状态转移方程自然包含d(i), 上文中包含状态d(i)的方程是:d(3)=min{d(3-1)+1, d(3-3)+1}。没错, 它就是状态转移方程,描述状态之间是如何转移的。当然,我们要对它抽象一下,
d(i)=min{ d(i-vj)+1 },其中i-vj >=0,vj表示第j个硬币的面值;
有了状态和状态转移方程,这个问题基本上也就解决了。当然了,Talk is cheap,show me the code!
伪代码如下:
下图是当i从0到11时的解:

从上图可以得出,要凑够11元至少需要3枚硬币。
此外,通过追踪我们是如何从前一个状态值得到当前状态值的, 可以找到每一次我们用的是什么面值的硬币。比如,从上面的图我们可以看出, 最终结果d(11)=d(10)+1(面值为1),而d(10)=d(5)+1(面值为5),最后d(5)=d(0)+1 (面值为5)。所以我们凑够11元最少需要的3枚硬币是:1元、5元、5元。
int min2(int a, int b)
{
return a>b ? b:a;
}
int min3(int a, int b, int c)
{
int tmp;
return (tmp = a>b ? b:a) > c ? c:tmp;
}
int d(int i) //凑够i元最少需要多少个硬币
{
if(i == 0)
return 0;
else if(i>=1 && i<3) //只能选择1元的硬币
{
return 1+d(i-1);
}
else if(i>=3 && i<5) //可以选择1元的或3元的硬币
{
return min2(1+d(i-1),1+d(i-3));
}
else if(i>=5) // 1 3 5都可以选择
{
return min3(1+d(i-1), 1+d(i-3), 1+d(i-5));
}
}初级 最长非降子序列的长度
上面讨论了一个非常简单的例子。现在让我们来看看对于更复杂的问题, 如何找到状态之间的转移方式(即找到状态转移方程)。 为此我们要引入一个新词叫递推关系来将状态联系起来(说的还是状态转移方程)
OK,上例子,看看它是如何工作的。
一个序列有N个数:A[1],A[2],…,A[N],求出最长非降子序列的长度。 (讲DP基本都会讲到的一个问题LIS:longest increasing subsequence)
正如上面我们讲的,面对这样一个问题,我们首先要定义一个“状态”来代表它的子问题, 并且找到它的解。注意,大部分情况下,某个状态只与它前面出现的状态有关, 而独立于后面的状态。
让我们沿用“入门”一节里那道简单题的思路来一步步找到“状态”和“状态转移方程”。 假如我们考虑求A[1],A[2],…,A[i]的最长非降子序列的长度,其中i
#include <iostream>
using namespace std;
int lis(int A[], int n)
{
int *d = new int[n];
int len = 1;
for(int i=0; i<n; ++i)
{
d[i] = 1;
for(int j=0; j<i; ++j)
if(A[j]<=A[i] && d[j]+1>d[i])
d[i] = d[j] + 1;
if(d[i]>len) len = d[i];
}
delete[] d;
return len;
}
int main()
{
int A[] = {
5, 3, 4, 8, 6, 7
};
cout<<lis(A, 6)<<endl;
return 0;
}该算法的时间复杂度是O(n2 ),并不是最优的解法。 还有一种很巧妙的算法可以将时间复杂度降到O(nlogn),网上已经有各种文章介绍它, 这里就不再赘述。传送门: LIS的O(nlogn)解法。 此题还可以用“排序+LCS”来解,感兴趣的话可自行Google。
练习题
无向图G有N个结点(1<N<=1000)及一些边,每一条边上带有正的权重值。 找到结点1到结点N的最短路径,或者输出不存在这样的路径。
提示:在每一步中,对于那些没有计算过的结点, 及那些已经计算出从结点1到它的最短路径的结点,如果它们间有边, 则计算从结点1到未计算结点的最短路径。
中级 二维DP问题 走格子问题
接下来,让我们来看看如何解决二维的DP问题。
例:平面上有N*M个格子,每个格子中放着一定数量的苹果。你从左上角的格子开始, 每一步只能向下走或是向右走,每次走到一个格子上就把格子里的苹果收集起来, 这样下去,你最多能收集到多少个苹果。
解这个问题与解其它的DP问题几乎没有什么两样。第一步找到问题的“状态”, 第二步找到“状态转移方程”,然后基本上问题就解决了。
首先,我们要找到这个问题中的“状态”是什么?我们必须注意到的一点是, 到达一个格子的方式最多只有两种:从左边来的(除了第一列)和从上边来的(除了第一行)。 因此为了求出到达当前格子后最多能收集到多少个苹果, 我们就要先去考察那些能到达当前这个格子的格子,到达它们最多能收集到多少个苹果。 (是不是有点绕,但这句话的本质其实是DP的关键:欲求问题的解,先要去求子问题的解)
经过上面的分析,很容易可以得出问题的状态和状态转移方程。 状态****S[i][j]表示我们走到(i, j)这个格子时,最多能收集到多少个苹果。那么, 状态转移方程如下:
S[i][j]=A[i][j] + max(S[i-1][j], if i>0 ; S[i][j-1], if j>0)其中i代表行,j代表列,下标均从0开始;A[i][j]代表格子(i, j)处的苹果数量。
S[i][j]有两种计算方式:1.对于每一行,从左向右计算,然后从上到下逐行处理;2. 对于每一列,从上到下计算,然后从左向右逐列处理。 这样做的目的是为了在计算S[i][j]时,S[i-1][j]和S[i][j-1]都已经计算出来了。
伪代码如下:
中高级 最短路径
这一节要讨论的是带有额外条件的DP问题。
以下的这个问题是个很好的例子。
无向图G有N个结点,它的边上带有正的权重值。你从结点1开始走,并且一开始的时候你身上带有M元钱。如果你经过结点i, 那么你就要花掉S[i]元(可以把这想象为收过路费)。如果你没有足够的钱, 就不能从那个结点经过。在这样的限制条件下,找到从结点1到结点N的最短路径。 或者输出该路径不存在。如果存在多条最短路径,那么输出花钱数量最少的那条。 限制:1<N<=100 ; 0<=M<=100 ; 对于每个i,0<=S[i]<=100;
正如我们所看到的, 如果没有额外的限制条件(在结点处要收费,费用不足还不给过),那么, 这个问题就和经典的迪杰斯特拉问题一样了(找到两结点间的最短路径)。 在经典的迪杰斯特拉问题中, 我们使用一个一维数组来保存从开始结点到每个结点的最短路径的长度, 即M[i]表示从开始结点到结点i的最短路径的长度。然而在这个问题中, 我们还要保存我们身上剩余多少钱这个信息。因此,很自然的, 我们将一维数组扩展为二维数组。M[i][j]表示从开始结点到结点i的最短路径长度, 且剩余j元。通过这种方式,我们将这个问题规约到原始的路径寻找问题。
在每一步中,对于已经找到的最短路径,我们找到它所能到达的下一个未标记状态(i,j), 将它标记为已访问(之后不再访问这个结点),并且在能到达这个结点的各个最短路径中, 找到加上当前边权重值后最小值对应的路径,即为该结点的最短路径。 (写起来真是绕,建议画个图就会明了很多)。不断重复上面的步骤, 直到所有的结点都访问到为止(这里的访问并不是要求我们要经过它, 比如有个结点收费很高,你没有足够的钱去经过它,但你已经访问过它) 最后Min[N-1][j]中的最小值即是问题的答案(如果有多个最小值, 即有多条最短路径,那么选择j最大的那条路径,即,使你剩余钱数最多的最短路径)。
伪代码:
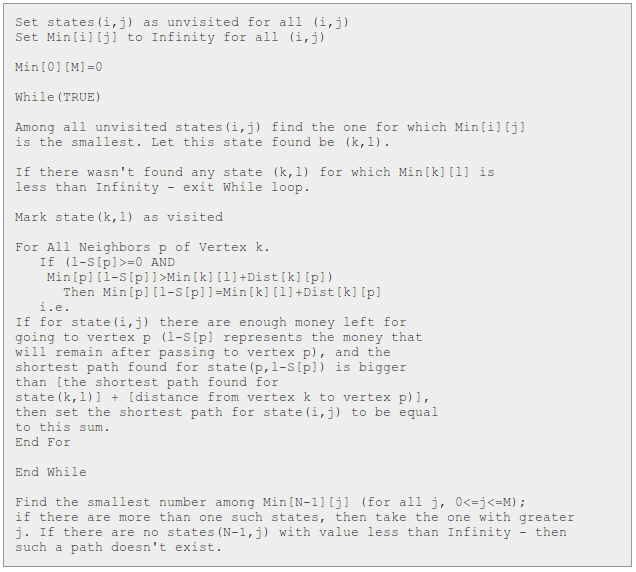
高级
以下问题需要仔细的揣摩才能将其规约为可用DP解的问题。
问题:StarAdventure - SRM 208 Div 1:
给定一个M行N列的矩阵(M*N个格子),每个格子中放着一定数量的苹果。 你从左上角的格子开始,只能向下或向右走,目的地是右下角的格子。 你每走过一个格子,就把格子上的苹果都收集起来。然后你从右下角走回左上角的格子, 每次只能向左或是向上走,同样的,走过一个格子就把里面的苹果都收集起来。 最后,你再一次从左上角走到右下角,每过一个格子同样要收集起里面的苹果 (如果格子里的苹果数为0,就不用收集)。求你最多能收集到多少苹果。注意:当你经过一个格子时,你要一次性把格子里的苹果都拿走。限制条件:1 < N, M <= 50;每个格子里的苹果数量是0到1000(包含0和1000)。
如果我们只需要从左上角的格子走到右下角的格子一次,并且收集最大数量的苹果, 那么问题就退化为“中级”一节里的那个问题。将这里的问题规约为“中级”里的简单题, 这样一来会比较好解。让我们来分析一下这个问题,要如何规约或是修改才能用上DP。
首先,对于第二次从右下角走到左上角得出的这条路径, 我们可以将它视为从左上角走到右下角得出的路径,没有任何的差别。 (即从B走到A的最优路径和从A走到B的最优路径是一样的)通过这种方式, 我们得到了三条从顶走到底的路径。对于这一点的理解可以稍微减小问题的难度。 于是,我们可以将这3条路径记为左,中,右路径。对于两条相交路径(如下图):
这里写链接内容
在不影响结果的情况下,我们可以将它们视为两条不相交的路径:
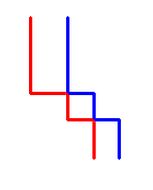
这样一来,我们将得到左,中,右3条路径。此外,如果我们要得到最优解, 路径之间不能相交(除了左上角和右下角必然会相交的格子)。因此对于每一行y( 除了第一行和最后一行),三条路径对应的x坐标要满足:x1[y] < x2[y] < x3[y]。 经过这一步的分析,问题的DP解法就进一步地清晰了。让我们考虑行y, 对于每一个x1[y-1],x2[y-1]和x3[y-1],我们已经找到了能收集到最多苹果数量的路径。 根据它们,我们能求出行y的最优解。现在我们要做的就是找到从一行移动到下一行的方式。 令Max[i][j][k]表示到第y-1行为止收集到苹果的最大数量, 其中3条路径分别止于第i,j,k列。对于下一行y,对每个Max[i][j][k] 都加上格子(y,i),(y,j)和(y,k)内的苹果数量。因此,每一步我们都向下移动。 我们做了这一步移动之后,还要考虑到,一条路径是有可能向右移动的。 (对于每一个格子,我们有可能是从它上面向下移动到它, 也可能是从它左边向右移动到它)。为了保证3条路径互不相交, 我们首先要考虑左边的路径向右移动的情况,然后是中间,最后是右边的路径。 为了更好的理解,让我们来考虑左边的路径向右移动的情况,对于每一个可能的j,k对(j
其它
当阅读一个题目并且开始尝试解决它时,首先看一下它的限制。 如果要求在多项式时间内解决,那么该问题就很可能要用DP来解。遇到这种情况, 最重要的就是找到问题的“状态”和“状态转移方程”。(状态不是随便定义的, 一般定义完状态,你要找到当前状态是如何从前面的状态得到的, 即找到状态转移方程)如果看起来是个DP问题,但你却无法定义出状态, 那么试着将问题规约到一个已知的DP问题(正如“高级”一节中的例子一样)。
March 26, 2013
作者:Hawstein
出处:http://hawstein.com/posts/dp-novice-to-advanced.html
声明:本文采用以下协议进行授权: 自由转载-非商用-非衍生-保持署名|Creative Commons BY-NC-ND 3.0 ,转载请注明作者及出处。
动态规划之背包问题
1、简易背包问题(无物件价值)
有一个背包,能盛放的物品总重量为S,设有N件物品,其重量分别为w1,w2,…,wn,希望从N件物品中选择若干物品,所选物品的重量之和恰能放进该背包,即所选物品的重量之和即是S。递归和非递归解法都能求得“背包题目”的一组解。
递归解法:
/* * 首先尝试将最后一件物品放入背包,则物品减少一件,背包可用体积相应减少,然后对当前状态进行递归…… * 若有解则递归结束;若无解则抛弃最后一件物品,然后对当前状态进行递归 */
//s背包体积n物品数量w物品重量
int knap(int s, int n, int w[])
{
if ( s<0 || s>0 && n<1 ) //排除不符合要求的参数
return(0);
else if ( s == 0 ) //递归结束标志,s体积为0
return (1);
else if ( knap(s - w[n-1], n - 1, w) == 1 )
{
printf("result: n=%d ,w[%d]=%d \n", n, n-1, w[n-1]);
return (1);
}
else
return ( knap(s, n - 1, w) );
}2、复杂背包问题
话说有一哥们去森林里玩发现了一堆宝石,他数了数,一共有n个。 但他身上能装宝石的就只有一个背包,背包的容量为C。这哥们把n个宝石排成一排并编上号: 0,1,2,…,n-1。第i个宝石对应的体积和价值分别为V[i]和W[i] 。排好后这哥们开始思考: 背包总共也就只能装下体积为C的东西,那我要装下哪些宝石才能让我获得最大的利益呢?
OK,如果是你,你会怎么做?你斩钉截铁的说:动态规划啊!恭喜你,答对了。 那么让我们来看看,动态规划中最最最重要的两个概念: 状态和状态转移方程在这个问题中分别是什么。
我们要怎样去定义状态呢?这个状态总不能是凭空想象或是从天上掉下来的吧。 为了方便说明,让我们先实例化上面的问题。
实例化问题:
一般遇到n,你就果断地给n赋予一个很小的数, 比如n=3。然后设背包容量C=10,三个宝石的体积为5,4,3,对应的价值为20,10,12。 对于这个例子,我想智商大于0的人都知道正解应该是把体积为5和3的宝石装到背包里, 此时对应的价值是20+12=32。接下来,我们把第三个宝石拿走, 同时背包容量减去第三个宝石的体积(因为它是装入背包的宝石之一), 于是问题的各参数变为:n=2,C=7,体积{5,4},价值{20,10}。好了, 现在这个问题的解是什么?我想智商等于0的也解得出了:把体积为5的宝石放入背包 (然后剩下体积2,装不下第二个宝石,只能眼睁睁看着它溜走),此时价值为20。 这样一来,我们发现,n=3时,放入背包的是0号和2号宝石;当n=2时, 我们放入的是0号宝石。这并不是一个偶然,没错, 这就是传说中的“全局最优解包含局部最优解”(n=2是n=3情况的一个局部子问题)。 绕了那么大的圈子,你可能要问,这都哪跟哪啊?说好的状态呢?说好的状态转移方程呢? 别急,它们已经呼之欲出了。
我们再把上面的例子理一下。
当n=2时,我们要求的是前2个宝石, 装到体积为7的背包里能达到的最大价值;
当n=3时,我们要求的是前3个宝石, 装到体积为10的背包里能达到的最大价值。
有没有发现它们其实是一个句式!OK, 让我们形式化地表示一下它们, 定义d(i,j)为前i个宝石装到剩余体积为j的背包里能达到的最大价值。 那么上面两句话即为:d(2, 7)和d(3, 10)。这样看着真是爽多了, 而这两个看着很爽的符号就是我们要找的状态了。 即状态d(i,j)表示前i个宝石装到剩余体积为j的背包里能达到的最大价值。 上面那么多的文字,用一句话概括就是:根据子问题定义状态!你找到子问题, 状态也就浮出水面了。而我们最终要求解的最大价值即为d(n, C):前n个宝石 (0,1,2…,n-1)装入剩余容量为C的背包中的最大价值。状态好不容易找到了, 状态转移方程呢?顾名思义,状态转移方程就是描述状态是怎么转移的方程(好废话!)。 那么回到例子,d(2, 7)和d(3, 10)是怎么转移的?来,我们来说说2号宝石 (记住宝石编号是从0开始的)。
从d(2, 7)到d(3, 10)就隔了这个2号宝石。 它有两种情况,装或者不装入背包。
如果装入,在面对前2个宝石时, 背包就只剩下体积7来装它们,而相应的要加上2号宝石的价值12, d(3, 10)=d(2, 10-3)+12=d(2, 7)+12;
如果不装入,体积仍为10,价值自然不变了, d(3, 10)=d(2, 10)。
记住,d(3, 10)表示的是前3个宝石装入到剩余体积为10 的背包里能达到的最大价值,既然是最大价值,就有
d(3, 10) = max{ d(2, 10), d(2, 7)+12 }。
好了,这条方程描述了状态d(i, j)的一些关系, 没错,它就是状态转移方程了。把它形式化一下:
d(i, j) = max{ d(i-1, j), d(i-1,j-V[i-1]) + W[i-1] }。
注意讨论前i个宝石装入背包的时候, 其实是在考查第i-1个宝石装不装入背包(因为宝石是从0开始编号的)。至此, 状态和状态转移方程都已经有了。接下来,直接上代码。
//i表示宝石的编号,j表示背包剩余的体积
for(int i=0; i<=n; ++i)
{
for(int j=0; j<=C; ++j)
{
d[i][j] = i==0 ? 0 : d[i-1][j];
if(i>0 && j>=V[i-1])
d[i][j] >?= d[i-1][j-V[i-1]]+W[i-1]; //取两者的较大值
//d[i][j] = d[i][j] > (d[i-1][j-V[i-1]] + W[i-1]) ? d[i][j] : d[i-1][j-V[i-1]] + W[i-1];
}
}i=0时,d(i, j)为什么为0呢?因为前0个宝石装入背包就是没东西装入,所以最大价值为0。 if语句里,j>=V[i-1]说明只有当背包剩余体积j大于等于i-1号宝石的体积时, 我才考虑把它装进来的情况,不然d[i][j]就直接等于d[i-1][j]。i>0不用说了吧, 前0个宝石装入背包的情况是边界,直接等于0,只有i>0才有必要讨论, 我是装呢还是不装呢。简单吧,核心算法就这么一丁点,接下来上完整代码knapsack.cpp。
/**0-1 knapsack d(i, j)表示前i个物品装到剩余容量为j的背包中的最大重量**/
#include<cstdio>
using namespace std;
#define MAXN 1000
#define MAXC 100000
int V[MAXN], W[MAXN];
int d[MAXN][MAXC];
int main()
{
freopen("data.in", "r", stdin);//重定向输入流
freopen("data.out", "w", stdout);//重定向输出流
int n, C;
while(scanf("%d %d", &n, &C) != EOF)
{
for(int i=0; i<n; ++i)
scanf("%d %d", &V[i], &W[i]);
for(int i=0; i<=n; ++i)
{
for(int j=0; j<=C; ++j)
{
d[i][j] = i==0 ? 0 : d[i-1][j];
if(i>0 && j>=V[i-1]) d[i][j] >?= d[i-1][j-V[i-1]]+W[i-1];
}
}
printf("%d\n", d[n][C]);//最终求解的最大价值
}
fclose(stdin);
fclose(stdout);
return 0;
}其中freopen函数将标准输入流重定向到文件data.in, 这比运行程序时一点点手输要方便许多,将标准输出流重定向到data.out。 data.in中每组输入的第一行为宝石数量n及背包体积C,接下来会有n行的数据, 每行两个数对应的是宝石的体积及价值。本测试用例data.in如下:
5 10
4 9
3 6
5 1
2 4
5 1
4 9
4 20
3 6
4 20
2 4
5 10
2 6
2 3
6 5
5 4
4 6data.out为算法输出结果,对应该测试用例,输出结果如下:
19
40
152、背包里装入哪些宝石?
好,至此我们解决了背包问题中最基本的0/1背包问题。等等,这时你可能要问, 我现在只知道背包能装入宝石的最大价值,但我还不知道要往背包里装入哪些宝石啊。嗯, 好问题!让我们先定义一个数组x,对于其中的元素为1时表示对应编号的宝石放入背包, 为0则不放入。让我们回到上面的例子,对于体积为5,4,3,价值为20,10,12的3个宝石 ,如何求得其对应的数组x呢?(明显我们目测一下就知道x={1 0 1}, 但程序可目测不出来)OK,让我们还是从状态说起。
如果我们把2号宝石放入了背包, 那么是不是也就意味着,
前3个宝石放入背包的最大价值 要比
前2个宝石放入背包的价值 大,
即:d(3, 10) > d(2, 10)。
d(i,j)为前i个宝石装到剩余体积为j的背包里能达到的最大价值。
再用字母代替具体的数字 (不知不觉中我们就用了不完全归纳法哈),
当d(i, j) > d(i-1, j)时,x(i-1) = 1;OK, 上代码:
//输出打印方案
int j = C;
for(int i=n; i>0; --i)
{
if(d[i][j] > d[i-1][j])
{
x[i-1] = 1;
j = j - V[i-1];//装入第i-1个宝石后背包能装入的体积就只剩下j - V[i-1]
}
}
for(int i=0; i<n; ++i)
printf("%d ", x[i]);好了,加入这部分内容,knapsack.cpp变为如下:
/**0-1 knapsack d(i, j)表示前i个物品装到剩余容量为j的背包中的最大重量**/
#include<cstdio>
using namespace std;
#define MAXN 1000
#define MAXC 100000
int V[MAXN], W[MAXN], x[MAXN];
int d[MAXN][MAXC];
int main()
{
freopen("data.in", "r", stdin);
freopen("data.out", "w", stdout);
int n, C;
while(scanf("%d %d", &n, &C) != EOF)
{
for(int i=0; i<n; ++i)
scanf("%d %d", &V[i], &W[i]);
for(int i=0; i<n; ++i)
x[i] = 0; //初始化打印方案
for(int i=0; i<=n; ++i)
{
for(int j=0; j<=C; ++j)
{
d[i][j] = i==0 ? 0 : d[i-1][j];
if(i>0 && j>=V[i-1]) d[i][j] >?= d[i-1][j-V[i-1]]+W[i-1];
}
}
printf("%d\n", d[n][C]);
//输出打印方案
int j = C;
for(int i=n; i>0; --i)
{
if(d[i][j] > d[i-1][j])
{
x[i-1] = 1;
j = j - V[i-1];
}
}
for(int i=0; i<n; ++i)
printf("%d ", x[i]);
printf("\n");
}
fclose(stdin);
fclose(stdout);
return 0;
}至此,好像该解决的问题都解决了。当一个问题找到一个放心可靠的解决方案后, 我们往往就要考虑一下是不是有优化方案了。为了保持代码的简洁, 我们暂且把宝石装包方案的求解去掉。该算法的时间复杂度是O(nC), 即时间都花在两个for循环里了,这个应该是没办法再优化了。再看看空间复杂度, 数组d用来保存每个状态的值,空间复杂度为O(nC); 数组V和W用来保存每个宝石的体积和价值,空间复杂度为O(n)。程序总的空间复杂度为 O(nC),这个是可以进一步优化的。
首先,我们先把数组V和W去掉, 因为它们没有保存的必要,改为一边读入一边计算:
int V = 0, W = 0;
for(int i=0; i<=n; ++i)
{
if(i>0) scanf("%d %d", &V,&W);
for(int j=0; j<=C;++j)
{
d[i][j] = i==0 ? 0 : d[i-1][j];
if(j>=V && i>0) d[i][j] >?= d[i-1][j-V]+W;
}
}好了,接下来让我们继续压榨空间复杂度。保存状态值我们开了一个二维数组d, 在看过把一维数组V和W变为一个变量后,我们是不是要思考一下, 有没有办法将这个二维数组也压榨一下呢?换言之, 这个二维数组中的每个状态值我们真的有必要都保存么? 让我们先来看一下以下的一张示意图(参照《算法竞赛入门经典》P169的图画的)
由上面那一小段优化过后的代码可知,状态转移方程为:
d(i, j)=max{ d(i-1, j), d(i-1, j-V)+W },
也就是在计算d(i, j)时我们用到了d(i-1,j)和d(i-1, j-V)的值。 如果我们只用一个一维数组d(0)~d(C)来保存状态值可以么?将i方向的维数去掉, 我们可以将原来二维数组表示为一维数据:d(i-1, j-V)变为d(j-V), d(i-1, j)变为d(j)。当我们要计算d(i, j)时,只需要比较d(j)和d(j-V)+W的大小, 用较大的数更新d(j)即可。等等,如果我要计算d(i, j+1),而它恰好要用到d(i-1, j)的值, 那么问题就出来了,因为你刚刚才把它更新为d(i, j)了。那么,怎么办呢? 按照j递减的顺序即可避免这种问题。比如,你计算完d(i, j), 接下来要计算的是d(i,j-1),而它的状态转移方程为d(i, j-1)=max{ d(i-1, j-1), d(i-1, j-1-V)+W },它不会再用到d(i-1,j)的值!所以, 即使该位置的值被更新了也无所谓。好,上代码:
memset(d, 0, sizeof(d));
for(int i=0; i<=n; ++i)
{
if(i>0) scanf("%d %d", &V,&W);
for(int j=C;j>=0; --j)
{
if(j>=V && i>0) d[j] >?= d[j-V]+W;
}
}优化后的完整代码如下,此时空间复杂度仅为O(C)。
/**0-1 knapsack d(i, j)表示前i个物品装到剩余容量为j的背包中的最大重量**/
#include<cstdio>
#include<cstdlib>
#include<cstring>
using namespace std;
int main()
{
freopen("data.in", "r", stdin);
freopen("data.out", "w", stdout);
int n, C, V = 0, W = 0;
while(scanf("%d %d", &n, &C) != EOF)
{
int* d = (int*)malloc((C+1)*sizeof(int));
memset(d, 0, (C+1)*sizeof(int));
for(int i=0; i<=n; ++i)
{
if(i>0)
scanf("%d %d", &V, &W);
for(int j=C; j>=0; --j)
{
if(j>=V && i>0)
d[j] >?= d[j-V]+W;
}
}
printf("%d\n", d[C]);
free(d);
}
fclose(stdin);
fclose(stdout);
return 0;
}