算法:动态规划
1.首先来看看维基百科怎么定义的动态规划
引自wiki:Dynamic programming
In mathematics, management science, economics, computer science, and bioinformatics, dynamic programming (also known as dynamic optimization) is a method for solving a complex problem by breaking it down into a collection of simpler subproblems, solving each of those subproblems just once, and storing their solutions - ideally, using a memory-based data structure. The next time the same subproblem occurs, instead of recomputing its solution, one simply looks up the previously computed solution, thereby saving computation time at the expense of a (hopefully) modest expenditure in storage space. (Each of the subproblem solutions is indexed in some way, typically based on the values of its input parameters, so as to facilitate its lookup.) The technique of storing solutions to subproblems instead of recomputing them is called "memoization".
Dynamic programming algorithms are often used for optimization. A dynamic programming algorithm will examine the previously solved subproblems and will combine their solutions to give the best solution for the given problem. In comparison, a greedy algorithm treats the solution as some sequence of steps and picks the locally optimal choice at each step. Using a greedy algorithm does not guarantee an optimal solution, because picking locally optimal choices may result in a bad global solution, but it is often faster to calculate. Fortunately, some greedy algorithms (such as Kruskal's or Prim's for minimum spanning trees) are proven to lead to the optimal solution.
For example, in the coin change problem of finding the minimum number of coins of given denominations needed to make a given amount, a dynamic programming algorithm would find an optimal solution for each amount by first finding an optimal solution for each smaller amount and then using these solutions to construct an optimal solution for the larger amount. In contrast, a greedy algorithm might treat the solution as a sequence of coins, starting from the given amount and at each step subtracting the largest possible coin denomination that is less than the current remaining amount. If the coin denominations are 1,4,5,15,20 and the given amount is 23, this greedy algorithm gives a non-optimal solution of 20+1+1+1, while the optimal solution is 15+4+4.
In addition to finding optimal solutions to some problem, dynamic programming can also be used for counting the number of solutions, for example counting the number of ways a certain amount of change can be made from a given collection of coins, or counting the number of optimal solutions to the coin change problem described above.
Sometimes, applying memoization to the naive recursive algorithm (namely the one obtained by a direct translation of the problem into recursive form) already results in a dynamic programming algorithm with asymptotically optimal time complexity, but for optimization problems in general the optimal algorithm might require more sophisticated algorithms. Some of these may be recursive (and hence can be memoized) but parametrized differently from the naive algorithm. For other problems the optimal algorithm may not even be a memoized recursive algorithm in any reasonably natural sense. An example of such a problem is the Egg Dropping puzzle described below.
在文章的 第二段和第三段加黄背景的文字,第二段说明了与贪婪算法的不同并通过第三段的举例,同一个问题贪婪算法可能会得不到全局最优解,23=20+1+1+1,而动态规划是23=15+4+4得到全局最优解
还有在wiki Greedy algorithm 中有张图片:来说明贪婪算法有可能得不到全局最优解,但是幸运的是 Kruskal's or Prim's for minimum spanning trees 达到了全局最优解
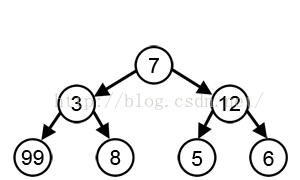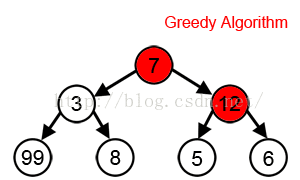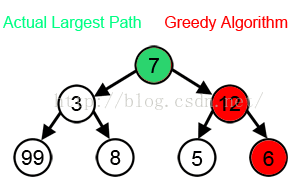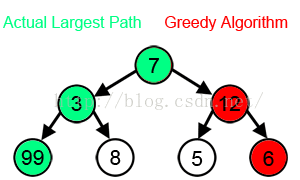
2.然后我看 清华大学研究生公共课教材---数学系列---最优化理论与算法(第二版)陈宝林 编著
在最后第16章,以最短路线问题例介绍了动态规划,并定义了动态规划中的几个常用的术语。
1.阶段
2.状态
3.决策
4.策略
5.状态转移方程
6.指标函数
7.最优策略和最优轨线
在第二节提出了 R.Bellman的最优性原理:一个最优策略的子策略总是最优的
3. 算法导论中的动态规划
提到在动态规划方法的最优化问题中的两个要素:最优子结构和重叠子问题。
详细请看 算法导论P202
4.然后看知乎大神的解答:
链接:https://www.zhihu.com/question/23995189/answer/35324479
我曾经作为省队成员参加过NOI,保送之后也给学校参加NOIP的同学多次讲过动态规划,我试着讲一下我理解的 动态规划,争取深入浅出。希望你看了我的答案,能够喜欢上动态规划。
0. 动态规划的本质,是对问题 状态的定义和 状态转移方程的定义。
引自维基百科
dynamic programming is a method for solving a complex problem by breaking it down into a collection of simpler subproblems.动态规划是通过 拆分问题,定义问题状态和状态之间的关系,使得问题能够以递推(或者说分治)的方式去解决。
本题下的其他答案,大多都是在说递推的求解方法,但 如何拆分问题,才是动态规划的核心。
而 拆分问题,靠的就是 状态的定义和 状态转移方程的定义。
1. 什么是 状态的定义?
首先想说大家千万不要被下面的数学式吓到,这里只涉及到了函数相关的知识。
我们先来看一个动态规划的教学必备题:
给定一个数列,长度为N,要解决这个问题,我们首先要 定义这个问题和这个问题的子问题。
求这个数列的最长上升(递增)子数列(LIS)的长度.
以
1 7 2 8 3 4
为例。
这个数列的最长递增子数列是 1 2 3 4,长度为4;
次长的长度为3, 包括 1 7 8; 1 2 3 等.
有人可能会问了,题目都已经在这了,我们还需定义这个问题吗?需要,原因就是这个问题在字面上看,找不出子问题,而没有子问题,这个题目就没办法解决。
所以我们来重新定义这个问题:
给定一个数列,长度为N,显然,这个新问题与原问题等价。
设为:以数列中第k项结尾的最长递增子序列的长度.
求中的最大值.
而对于
上述的新问题
之所以把
对状态的定义只有一种吗? 当然不是。
我们甚至可以二维的,以完全不同的视角定义这个问题:
给定一个数列,长度为N,这个新定义与原问题的等价性也不难证明,请读者体会一下。
设为:
在前i项中的,长度为k的最长递增子序列中,最后一位的最小值..
若在前i项中,不存在长度为k的最长递增子序列,则为正无穷.
求最大的x,使得不为正无穷。
上述的
2. 什么是 状态转移方程?
上述状态定义好之后,状态和状态之间的关系式,就叫做 状态转移方程。
比如,对于LIS问题,我们的第一种定义:
设设A为题中数列,状态转移方程为:为:以数列中第k项结尾的最长递增子序列的长度.
用文字解释一下是:(根据状态定义导出边界情况)
![F_{k}=max(F_{i}+1 | A_{k}>A_{i}, i\in (1..k-1))]()
![(k>1)]()
以第k项结尾的LIS的长度是:保证第i项比第k项小的情况下,以第i项结尾的LIS长度加一的最大值,取遍i的所有值(i小于k)。
第二种定义:
设设A为题中数列,状态转移方程为:为:在数列前i项中,长度为k的递增子序列中,最后一位的最小值
若(边界情况需要分类讨论较多,在此不列出,需要根据状态定义导出边界情况。)则
![F_{i,k}=min(A_{i},F_{i-1,k})]()
否则:![F_{i,k}=F_{i-1,k}]()
大家套着定义读一下公式就可以了,应该不难理解,就是有点绕。
这里可以看出,这里的状态转移方程,就是定义了问题和子问题之间的关系。
可以看出,状态转移方程就是带有条件的递推式。
3. 动态规划迷思
本题下其他用户的回答跟动态规划都有或多或少的联系,我也讲一下与本答案的联系。
a. “缓存”,“重叠子问题”,“记忆化”:
这三个名词,都是在阐述递推式求解的技巧。以Fibonacci数列为例,计算第100项的时候,需要计算 第99项和98项;在计算第101项的时候,需要第100项和 第99项,这时候你还需要重新计算第99项吗?不需要,你只需要在第一次计算的时候把它记下来就可以了。
上述的需要再次计算的“第99项”,就叫“重叠子问题”。如果没有计算过,就按照递推式计算,如果计算过,直接使用,就像“缓存”一样,这种方法,叫做“记忆化”,这是递推式求解的技巧。这种技巧,通俗的说叫“花费空间来节省时间”。 都不是动态规划的本质,不是动态规划的核心。
b. “递归”:
递归是递推式求解的方法,连技巧都算不上。
c. "无后效性",“最优子结构”:
上述的状态转移方程中,等式右边不会用到下标大于左边i或者k的值,这是"无后效性"的通俗上的数学定义,符合这种定义的状态定义,我们可以说它具有“最优子结构”的性质,在动态规划中我们要做的,就是找到这种“最优子结构”。
在对状态和状态转移方程的定义过程中,满足“最优子结构”是一个隐含的条件(否则根本定义不出来)。对状态和“最优子结构”的关系的进一步解释,什么是动态规划?动态规划的意义是什么? - 王勐的回答 写的很好,大家可以去读一下。
需要注意的是,一个问题可能有多种不同的状态定义和状态转移方程定义,存在一个有后效性的定义, 不代表该问题不适用动态规划。这也是其他几个答案中出现的逻辑误区:
动态规划方法要寻找符合“最优子结构“的状态和状态转移方程的定义 ,在找到之后,这个问题就可以以“记忆化地求解递推式”的方法来解决。而寻找到的定义,才是动态规划的本质。
有位答主说:
分治在求解每个子问题的时候,都要进行一遍计算这就像说多加辣椒的菜就叫川菜,多加酱油的菜就叫鲁菜一样,是存在误解的。
动态规划则存储了子问题的结果,查表时间为常数
文艺的说,动态规划是寻找一种对问题的观察角度,让问题能够以递推(或者说分治)的方式去解决。寻找看问题的角度,才是动态规划中最耀眼的宝石!(大雾)
理解动态规划并不需要数学公式介入,只是完全解释清楚需要点篇幅…首先需要明白哪些问题不是动态规划可以解决的,才能明白为神马需要动态规划。不过好处时顺便也就搞明白了递推贪心搜索和动规之间有什么关系,以及帮助那些总是把动规当成搜索解的同学建立动规的思路。当然熟悉了之后可以直接根据问题的描述得到思路,如果有需要的话再补充吧。
动态规划是对于 某一类问题 的解决方法!!重点在于如何鉴定“某一类问题”是动态规划可解的而不是纠结解决方法是递归还是递推!
怎么鉴定dp可解的一类问题需要从计算机是怎么工作的说起…计算机的本质是一个状态机,内存里存储的所有数据构成了当前的状态,CPU只能利用当前的状态计算出下一个状态(不要纠结硬盘之类的外部存储,就算考虑他们也只是扩大了状态的存储容量而已,并不能改变下一个状态只能从当前状态计算出来这一条铁律)
当你企图使用计算机解决一个问题是,其实就是在思考如何将这个问题表达成状态(用哪些变量存储哪些数据)以及如何在状态中转移(怎样根据一些变量计算出另一些变量)。所以所谓的空间复杂度就是为了支持你的计算所必需存储的状态最多有多少,所谓时间复杂度就是从初始状态到达最终状态中间需要多少步!
太抽象了还是举个例子吧:
比如说我想计算第100个非波那契数,每一个非波那契数就是这个问题的一个状态,每求一个新数字只需要之前的两个状态。所以同一个时刻,最多只需要保存两个状态,空间复杂度就是常数;每计算一个新状态所需要的时间也是常数且状态是线性递增的,所以时间复杂度也是线性的。
上面这种状态计算很直接,只需要依照固定的模式从旧状态计算出新状态就行(a[i]=a[i-1]+a[i-2]),不需要考虑是不是需要更多的状态,也不需要选择哪些旧状态来计算新状态。对于这样的解法,我们叫递推。
非波那契那个例子过于简单,以至于让人忽视了阶段的概念,所谓阶段是指随着问题的解决,在同一个时刻可能会得到的不同状态的集合。非波那契数列中,每一步会计算得到一个新数字,所以每个阶段只有一个状态。想象另外一个问题情景,假如把你放在一个围棋棋盘上的某一点,你每一步只能走一格,因为你可以东南西北随便走,所以你当你同样走四步可能会处于很多个不同的位置。从头开始走了几步就是第几个阶段,走了n步可能处于的位置称为一个状态,走了这n步所有可能到达的位置的集合就是这个阶段下所有可能的状态。
现在问题来了,有了阶段之后,计算新状态可能会遇到各种奇葩的情况,针对不同的情况,就需要不同的算法,下面就分情况来说明一下:
假如问题有n个阶段,每个阶段都有多个状态,不同阶段的状态数不必相同,一个阶段的一个状态可以得到下个阶段的所有状态中的几个。那我们要计算出最终阶段的状态数自然要经历之前每个阶段的某些状态。
好消息是,有时候我们并不需要真的计算所有状态,比如这样一个弱智的棋盘问题:从棋盘的左上角到达右下角最短需要几步。答案很显然,用这样一个弱智的问题是为了帮助我们理解阶段和状态。某个阶段确实可以有多个状态,正如这个问题中走n步可以走到很多位置一样。但是同样n步中,有哪些位置可以让我们在第n+1步中走的最远呢?没错,正是第n步中走的最远的位置。换成一句熟悉话叫做“下一步最优是从当前最优得到的”。所以为了计算最终的最优值,只需要存储每一步的最优值即可,解决符合这种性质的问题的算法就叫贪心。如果只看最优状态之间的计算过程是不是和非波那契数列的计算很像?所以计算的方法是递推。
既然问题都是可以划分成阶段和状态的。这样一来我们一下子解决了一大类问题:一个阶段的最优可以由前一个阶段的最优得到。
如果一个阶段的最优无法用前一个阶段的最优得到呢?
什么你说只需要之前两个阶段就可以得到当前最优?那跟只用之前一个阶段并没有本质区别。最麻烦的情况在于你需要之前所有的情况才行。
再来一个迷宫的例子。在计算从起点到终点的最短路线时,你不能只保存当前阶段的状态,因为题目要求你最短,所以你必须知道之前走过的所有位置。因为即便你当前再的位置不变,之前的路线不同会影响你的之后走的路线。这时你需要保存的是之前每个阶段所经历的那个状态,根据这些信息才能计算出下一个状态!
每个阶段的状态或许不多,但是每个状态都可以转移到下一阶段的多个状态,所以解的复杂度就是指数的,因此时间复杂度也是指数的。哦哦,刚刚提到的之前的路线会影响到下一步的选择,这个令人不开心的情况就叫做有后效性。
刚刚的情况实在太普遍,解决方法实在太暴力,有没有哪些情况可以避免如此的暴力呢?
契机就在于后效性。
有一类问题,看似需要之前所有的状态,其实不用。不妨也是拿最长上升子序列的例子来说明为什么他不必需要暴力搜索,进而引出动态规划的思路。
假装我们年幼无知想用搜索去寻找最长上升子序列。怎么搜索呢?需要从头到尾依次枚举是否选择当前的数字,每选定一个数字就要去看看是不是满足“上升”的性质,这里第i个阶段就是去思考是否要选择第i个数,第i个阶段有两个状态,分别是选和不选。哈哈,依稀出现了刚刚迷宫找路的影子!咦慢着,每次当我决定要选择当前数字的时候,只需要和之前选定的一个数字比较就行了!这是和之前迷宫问题的本质不同!这就可以纵容我们不需要记录之前所有的状态啊!既然我们的选择已经不受之前状态的组合的影响了,那时间复杂度自然也不是指数的了啊!虽然我们不在乎某序列之前都是什么元素,但我们还是需要这个序列的长度的。所以我们只需要记录以某个元素结尾的LIS长度就好!因此第i个阶段的最优解只是由前i-1个阶段的最优解得到的,然后就得到了DP方程(感谢 @韩曦 指正)
所以一个问题是该用递推、贪心、搜索还是动态规划,完全是由这个问题本身阶段间状态的转移方式决定的!
每个阶段只有一个状态->递推;
每个阶段的最优状态都是由上一个阶段的最优状态得到的->贪心;
每个阶段的最优状态是由之前所有阶段的状态的组合得到的->搜索;
每个阶段的最优状态可以从之前某个阶段的某个或某些状态直接得到而不管之前这个状态是如何得到的->动态规划。
每个阶段的最优状态可以从之前某个阶段的某个或某些状态直接得到这个性质叫做最优子结构;
而不管之前这个状态是如何得到的这个性质叫做无后效性。
另:其实动态规划中的最优状态的说法容易产生误导,以为只需要计算最优状态就好,LIS问题确实如此,转移时只用到了每个阶段“选”的状态。但实际上有的问题往往需要对每个阶段的所有状态都算出一个最优值,然后根据这些最优值再来找最优状态。比如背包问题就需要对前i个包(阶段)容量为j时(状态)计算出最大价值。然后在最后一个阶段中的所有状态种找到最优值。