Java集合
1.集合概述
集合类主要负责保存,盛装其他数据,因此集合类被称为容器类。所有集合类都位于java.util包下。集合类和数组不一样,数组元素可以是基本类型的值也可以是对象。而集合里面只可以是对象。
Iterator接口是所有集合的超级接口,它有两个主要的子接口Collection和Map,Java集合类主要从这两个接口派生而来。
2.Collection构成的集合体系
Collection接口是Set,Queue和List接口的父接口。
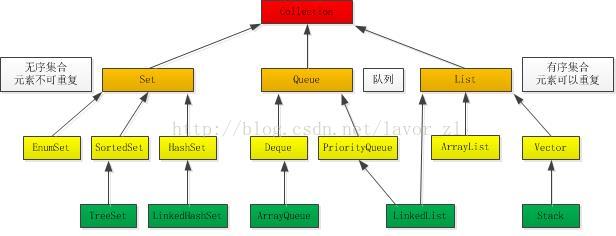
2.1Set接口体系
无序集合,元素不可重复,都是线程不安全的。2.1.1EnumSet类
与枚举类型一起使用的专用Set实现。枚举set中所有键都必须来自单个枚举类型,该枚举类型在创建set时显式或隐式地指定。枚举set在内部表示为位向量。此表示形式非常紧凑且高效。不允许使用null元素。
import java.util.Arrays;
import java.util.EnumSet;
public class EnumSetTest{
enum Color{
RED,GREEN,BLUE;
}
public static void main(String[] args) {
EnumSet<Color> enumSet1=EnumSet.noneOf(Color.class);//创建一个具有指定元素类型的空枚举set
enumSet1.add(Color.RED);//向枚举set里面添加元素,只能添加Color中的枚举实例
EnumSet<Color> enumSet2=EnumSet.allOf(Color.class);//创建一个包含指定元素类型的所有元素的枚举set
EnumSet<Color> enumSet3=EnumSet.of(Color.RED);//创建一个最初包含指定元素的枚举set,of方法里面的参数可以是多个
EnumSet<Color> enumSet4=EnumSet.range(Color.RED,Color.GREEN);//创建一个最初包含由两个指定端点所定义范围内的所有元素的枚举set
System.out.println(Arrays.toString(enumSet2.toArray()));//显示枚举set里的元素,输出结果是[RED, GREEN, BLUE]
}
}
2.1.2SortedSet接口
提供关于元素的总体排序的Set。这些元素使用其自然顺序进行排序,或者根据通常在创建有序set时提供的Comparator进行排序。该set的迭代器将按元素升序遍历set。插入有序set的所有元素都必须实现Comparable接口(或者被指定的比较器所接受)。另外,所有这些元素都必须是可互相比较的。2.1.2.1TreeSet类
TreeSet类是SortSet接口的唯一实现,TreeSet可以确保集合元素处于排序状态。import java.util.TreeSet;
public class TreeSetTest{
public static void main(String[] args) {
TreeSet<String> treeSet=new TreeSet<String>();
treeSet.add("RED");//向TreeSet中添加一个元素
treeSet.add("GREEN");//向TreeSet中添加一个元素
treeSet.add("BLUE");//向TreeSet中添加一个元素
System.out.println(treeSet);//输出:[BLUE, GREEN, RED],集合处于有序状态
System.out.println(treeSet.first());//输出集合第一个元素
System.out.println(treeSet.last());//输出集合最后一个元素
System.out.println(treeSet.headSet("lavor_zl"));//返回小于"lavor_zl"的子集
System.out.println(treeSet.tailSet("lavor_zl"));//返回大于等于"lavor_zl"的子集
System.out.println(treeSet.subSet("BLUE", "GREEN"));//返回大于等于"BLUE"且小于"GREEN"的子集
}
}
TreeSet不是根据元素插入顺序进行排序的,而是根据元素的值来排序的。TreeSet支持两种排序方法:自然排序和定制排序。
1、自然排序:TreeSet会调用集合元素的compareTo(Object obj)方法来计较元素之间大小关系,然后将集合元素按升序排列。如果试图把一个对象加进TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会出现ClassCastException异常。
2、定制排序:如果需要实现定制排序,则可以使用Comparator接口的帮助,该接口包含一个int compare(o1,o2)方法,该方法用于计较两个数的大小,如果返回正整数,则表明o1>o2;如果返回0,则表明o1=o2;如果返回负整数,则表明o1<02。
注意:不可以向TreeSet中添加类型不同的对象,否则会引起ClassCastException异常。
2.1.3HashSet类
HashSet类的几个特点1、不能保证元素的排列顺序,顺序有可能发生变化。
2、HashSet是异步的。
3、集合元素值可以是null。
4、当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值来确定该对象在HashSet中存储的位置。
import java.util.HashSet;
public class HashSetTest{
public static void main(String[] args) {
HashSet<String> hashSet = new HashSet<String>();
hashSet.add("RED");//向HashSet中添加一个元素
hashSet.add("GREEN");//向HashSet中添加一个元素
hashSet.add("BLUE");//向HashSet中添加一个元素
hashSet.contains("RED");//查看某个元素是否在HashSet中
hashSet.remove("RED");//删除HashSet中的一个元素
hashSet.clear();//清空HashSet中的所有元素
}
}
2.1.3.1LinkedHashSet类
HashSet还有一个子类LinkedHashSet,其集合也是根据元素hashCode值来决定元素的存储位置,但它同时用链表来维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说,当遍历LinkedHashSet集合元素时,它将会按元素的添加顺序来访问集合里的元素。所以LinkedHashSet的性能略低于HashSet,但在迭代访问全部元素时将有很好的性能,因为它以链表来维护内部顺序。2.2Queue接口体系
Queue用于模拟队列这种数据结构,队列具有“先进先出”(FIFO)的的特性。2.2.1PriorityQueue类
PriorityQueue是一个比较标准的队列实现。它会将加入队列中的元素按照指定排序大小进行排序,所以取出元素时,取出的不是最先进队的元素,而是队列中最小的元素。PriorityQueue的元素有两种排序方法:自然排序和定制排序。
1、自然排序:采用自然排序的PriorityQueue集合中的元素必须实现Comparable接口,而且应该是同一个类的多个实例,否则可能导致ClassCastException异常。
2、定制排序:创建PriorityQueue队列时,传入一个Comparator对象,该对象负责对队列中所有元素进行排序。采用定制排序不要求队列元素实现Comparable接口。
PriorityQueue队列对元素的要求与TreeSet的两种排序方法基本相同。
import java.util.PriorityQueue;
public class PriorityQueueTest{
public static void main(String[] args) {
PriorityQueue<Integer> pQueue=new PriorityQueue<Integer>();
pQueue.offer(2014);//向pQueue尾部加入一个元素,即让一个元素进队
pQueue.offer(11);
pQueue.offer(18);
System.out.println(pQueue);//输出队列,结果是[11, 2014, 18]
System.out.println(pQueue.peek());//获取队头元素,但是不删除该元素,输出值是11
System.out.println(pQueue.poll());//获取队头元素,并删除该元素,输出值是11
System.out.println(pQueue.poll());//获取队头元素,并删除该元素,输出值18
}
}
那么问题来了:
输出队列值的时候为什么是[11, 2014, 18]而不是[11,18,2014,],PriorityQueue队列中的元素怎么没有排好序啊?
但是输出队头元素的时候为什么11过后又输出18而不是2014。
PriorityQueue队列中的元素到底排了序没有啊?
仔细想想,我们会发现PriorityQueue队列中的元素总是会在对队列中元素操作时进行排序。
插入18时,对原来的元素进行排序,所以11会变到2014前面,插入18之后元素顺序为11,2014,18。
2.2.2Deque接口
Deque代表双端队列。Deque既可以当双端队列使用也可以当栈来使用。
2.2.2.1ArrayDeque类
ArrayDeque类是Deque接口的一个典型实现类。import java.util.ArrayDeque;
public class ArrayDequeTest{
//ArrayDeque当双端队列使用
public static void deque(){
ArrayDeque<String> deque=new ArrayDeque<String>();
deque.offerFirst("lavor");//双端队列开头加入一个元素
deque.offerLast("zl");//双端队列结尾加入一个元素
deque.peekFirst();//获取双端队列第一个元素,但不删除该元素
deque.peekLast();//获取双端队列最后一个元素,但不删除该元素
deque.pollFirst();//获取双端队列第一个元素,并删除该元素
deque.pollLast();//获取双端队列最后一个元素,并删除该元素
}
//ArrayDeque当栈使用
public static void stack(){
ArrayDeque<String> stack=new ArrayDeque<String>();
stack.push("lavor");//进栈
stack.push("zl");//进栈
stack.pop();//出栈
}
public static void main(String[] args) {
deque();
stack();
}
}
ArrayDeque的性能比Stack更好,当我们程序中需要使用”栈“这种数据结构时,推荐使用ArrayDeque或LinkedList,而不是Stack。
2.3List接口体系
2.3.1LinkedList类
LinkedList类是List接口的实现类,这意味着它是List的结合,可以根据索引来随机访问集合中的元素。除此之外,LinkedLink还实现了Deque接口,因此它可以当双端队列或栈使用。import java.util.Deque;
import java.util.LinkedList;
import java.util.List;
public class LinkedListTest{
//实现Deque所具有的功能
public static void deque(){
Deque<String> deque=new LinkedList<String>();
//当双端队列使用
deque.offerFirst("lavor");//双端队列开头加入一个元素
deque.offerLast("zl");//双端队列结尾加入一个元素
deque.peekFirst();//获取双端队列第一个元素,但不删除该元素
deque.peekLast();//获取双端队列最后一个元素,但不删除该元素
deque.pollFirst();//获取双端队列第一个元素,并删除该元素
deque.pollLast();//获取双端队列最后一个元素,并删除该元素<String> deque=new ArrayDeque<String>();
//当栈使用
deque.push("lavor_zl");//进栈
deque.pop();//出栈
}
//实现List所具有的功能
public static void list(){
List<String> list=new LinkedList<String>();
list.add("lavor_zl");//LinkedList加入一个元素
list.add("lavor");//LinkedList加入一个元素
list.set(0, "zl");//设置指定位置元素的值
list.get(1);//获取指定索引位置的元素,索引从0开始
}
public static void main(String[] args) {
list();
deque();
}
}
2.3.2ArrayList类
List就是一个线性表的接口,而ArrayList和LinkedList又是线性表的两种典型实现:基于数组的线性表和基于链的线性表。2.3.3Vector类
Vector 类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。但是Vector的大小可以根据需要增大或缩小,以适应创建Vector后进行添加或移除项的操作。2.3.4Stack类
Stack 类表示后进先出(LIFO)的对象堆栈。3.Map构成的集合体系
Map用于保存映射关系的数据。Map集合保存两组值,一组用于保存Map的Key,另一组用于保存Map的Value。将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射到一个值。

3.1EnumMap类
EnumMap类是线程不安全的。EnumMap类是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。
EnumMap不允许null作为key但可以作为value。
与创建一般的Map不同的是,创建EnumMap时必须指定一个枚举类,从而将EnumMap和指定枚举类关联起来。
import java.util.EnumMap;
enum Color{
RED,GREEN,BLUE
}
public class EnumMapTest{
public static void main(String[] args) {
EnumMap<Color, String> enumMap=new EnumMap<Color, String>(Color.class);
enumMap.put(Color.RED, "red");//向EnumMap加入一个key-value对
enumMap.put(Color.GREEN, "green");//向EnumMap加入一个key-value对
enumMap.get(Color.RED);//获取key值对应的value值
enumMap.keySet();//获取enumMap的所有key值的集合
}
}
3.2IdentityHashMap类
与HashMap基本相似,但是它在处理key时,要key严格相等(key1=key2),才认为两个key相等。对于HashMap来说只要key1和key2通过equals()方法比较返回true并且它们的hashCode值相等才相等。
3.3HashMap类
HashMap是Map接口的典型实现类,它是线程不安全的。HashMap允许null作为key或value。
import java.util.HashMap;
public class HashMapTest{
public static void main(String[] args) {
HashMap<String,String> hashMap=new HashMap<String,String>();
hashMap.put("lavor_zl", "HashMap");//向HashMap加入一组key-value对
hashMap.put("lavor", "Map");//向HashMap加入一组key-value对
hashMap.put("lavor", "Hash");//向HashMap加入一组key-value对
hashMap.get("lavor_zl");//获取对应key值的value
System.out.println(hashMap);//输出HashMap,输出结果是{lavor=Hash, lavor_zl=HashMap},说明HashMap是无序的,并且当加入一个已经存在的key值对应的key-value后会覆盖掉原来的key-value
hashMap.isEmpty();//判断HashMap是否为空
hashMap.containsKey("lavor_zl");//查看HashMap中是否包含某一个key值
hashMap.containsValue("Map");//查看HashMap中是否包含某一个value值
hashMap.keySet();//获取HashMap的key值集合
hashMap.values();//获取HashMap的value值集合
hashMap.size();//获取HashMap的大小即包含key-value对的个数
}
}
3.3.1LinkedHashMap类
HashMap有一个LinkedHashMap子类,它使用双向链表来维护key-value对的次序,该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。3.4HashTable类
HashTable是Map接口的典型实现类,它是线程安全的。HashMap不允许null作为key或value。
3.4.1Properties类
Properties是HashTable的子类。在处理属性文件时特别方便。Properties类可以把Map对象和属性文件关联起来,从而把Map对象中的key-value对写入属性文件中,也可以吧属性文件中的”属性名=属性值“加载到Map对象中。
由于属性文件中属性名和属性值只能是字符串类型,所以Properties里的key和value都是字符串类型。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
public class PropertiesTest{
public static void main(String[] args) {
Properties props=new Properties();
props.setProperty("lavor_zl", "PropertiesTest");//向Properties中加入一个key-value对
props.setProperty("lavor", "Properties");//向Properties中加入一个key-value对
props.getProperty("lavor_zl");//获取某一个key值对应的value值
props.getProperty("lavor_zl","default");//获取某一个key值对应的value值,若没有该key,则返回一个默认值
try {
//将props中的key-value对保存到store.txt中
props.store(new FileOutputStream("store.txt"), "properties");
Properties props2=new Properties();
//将store.txt中的key-value对追加到props2中
props2.load(new FileInputStream("store.txt"));
System.out.println(props2);//输出结果:{lavor=Properties, lavor_zl=PropertiesTest}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
store.txt中的内容为:
#properties
#Tue Nov 18 18:35:36 CST 2014
lavor=Properties
lavor_zl=PropertiesTest
3.5SortedMap接口
SortedMap接口提供关于键的总体排序的Map。
两种排序方法:
1、自然排序:采用自然排序的SortedMap的所有key必须实现Comparable接口,而且应该是同一个类的多个实例,否则可能导致ClassCastException异常。
2、定制排序:创建SortedMap时,传入一个Comparator对象,该对象负责对SortedMap中所有key进行排序。采用定制排序不要求key实现Comparable接口。
3.5.1TreeMap类
TreeMap是SortedMap接口的实现类。TreeMap就是一个红黑树的数据结构,每个key-value对作为红黑树的一个节点。
import java.util.TreeMap;
public class TreeMapTest{
public static void main(String[] args) {
TreeMap<String,String> treeMap=new TreeMap<String,String>();
treeMap.put("lavor_zl", "TreeMapTest");//向TreeMap中加入一个key-value对
treeMap.put("lavor", "TreeMap");//向TreeMap中加入一个key-value对
treeMap.get("lavor_zl");//获取某一key值对应的value值
System.out.println(treeMap);//输出TreeMap,输出结果:{lavor=TreeMap, lavor_zl=TreeMapTest},说明TreeMap已排序
}
}
3.6WeakHashMap类
WeakHashMap类与HashMap类的用法基本相似。与HashMap类的区别在于,HashMap的key保留了对实际对象的强引用,这意味着只要HashMap对象不销毁,该HashMap的所有key所引用的对象就不会被垃圾回收。
HashMap也不会自动删除这些key所对应的key-value对。
但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,
那这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key所对应的key-value对。
import java.util.WeakHashMap;
class WeakHashMapTest{
public static void main(String[] args) {
WeakHashMap<String,String> weak=new WeakHashMap<String,String>();
weak.put("lavor_zl", "WeakHashMapTest");//向WeakHashMap中加入一个key-value对
weak.put(new String("lavor"), "WeakHashMap");//向WeakHashMap中加入一个key-value对,此时的key值是匿名字符串对象,没有引用
weak.get("lavor_zl");//获取某一key值对应的value值
System.out.println(weak);//输出结果:{lavor=WeakHashMap, lavor_zl=WeakHashMapTest}
System.gc();//通知系统进行垃圾回收
System.out.println(weak);//输出结果:{lavor_zl=WeakHashMapTest}
}
}
我们可以看到第2次的输出结果比第一次的输出结果少一个key-value对,这是因为lavor=WeakHashMap这个key-value对的key是弱引用。
系统进行垃圾回收时可能会回收这个key所引用的对象,WeakHashMap也可能自动删除这个key所对应的key-value对。
此时这种删除发生了,所以第2次的输出结果少一个key-value对。