菜鸟入门_Python_机器学习(3)_回归
@sprt
*写在开头:博主在开始学习机器学习和Python之前从未有过任何编程经验,这个系列写在学习这个领域一个月之后,完全从一个入门级菜鸟的角度记录我的学习历程,代码未经优化,仅供参考。有错误之处欢迎大家指正。
系统:win7-CPU;
编程环境:Anaconda2-Python2.7,IDE:pycharm5;
参考书籍:
《Neural Networks and Learning Machines(Third Edition)》- Simon Haykin;
《Machine Learning in Action》- Peter Harrington;
《Building Machine Learning Systems with Python》- Wili Richert;
C站里都有资源,也有中文译本。
我很庆幸能跟随老师从最基础的东西学起,进入机器学习的世界。*
这节课开始接触‘回归’的概念,主要目的是对连续性的数据作出预测。回归可以做很多事情, C站上很多大牛的博客都有详述,这里不再赘述。我要做的就是从最基础的角度来学习怎样实现它,几个链接供参考:
http://www.sohu.comblog.csdn.net/dark_scope/article/details/8558244
http://blog.csdn.net/dark_scope/article/details/8558244
http://blog.csdn.net/zouxy09/article/details/17589329(大牛专栏,其中可学的太多)
先来看我们这节课的任务:
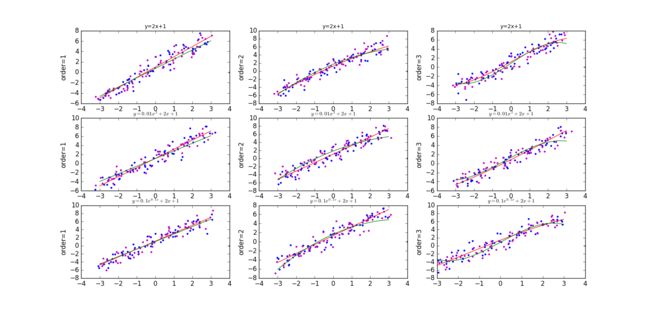
•玩转最小二乘法:针对以下3种真实模型(高斯白噪音(0,1),x在[-3,3]均匀取N=100个值,),采用3种最小二乘法模型(1次、2次和3次),分别拟合,画出散点和拟合曲线(共9张图)

•对X添加噪音(0,0.2),重复以上,观察结果变化。
•添加(0,3)作为观察样本,重复以上,观察结果变化。
•添加(4,0)作为观察样本,重复以上,观察结果变化。
•Prove: Bayesian or MAP estimation for linear regression is equivalent to regularization of MSE
•We will give you a dataset RegData2D, use whatever you have learnt to find the best relationship between x and y. Write a report, and specifically pay attention to underfittingand overfitting and how you come up with your best solutions.
之前每次的任务只是写好代码跑一跑看看结果,这次课起老师让我们学会写报告。原话是“有的人东西做不出来,但是一份好的报告依然会令人刮目相看”。
最小二乘法进行多项式拟合是回归当中很常用的方法,基本思想就是使拟合曲线的偏差平方和最小(凭什么使均方误差最小我们就认为达到所谓‘好’的标准了呢?好吧……老师这么问了,不敢随便回答),网上很多介绍,这里也给一个定义和求导过程:


代码如下,其实Python中有直接的最小二乘法的函数可以直接调用,但是为了理解清楚还是手敲了一下:
import matplotlib.pyplot as plt
import numpy as np
import math
#Each point on the generating curve
x = np.arange(-3,3,0.1)
def least_square_color1(y,order,error_x,error_y):
#The offset of each point on the generated curve
i=0
xa=[]
ya=[]
for xx in x:
yy=y[i]
d_x=np.random.normal(0,error_x)
d_y=np.random.normal(0,error_y)
i+=1
xa.append(xx+d_x)
ya.append(yy+d_y)
plt.plot(xa,ya,color='m',linestyle='',marker='.')
#Curve fitting
matA=[]
for i in range(0,order+1+1):
matA1=[]
for j in range(0,order+1+1):
tx=0.0
for k in range(0,len(xa)):
dx=1.0
for l in range(0,j+i):
dx=dx*xa[k]
tx+=dx
matA1.append(tx)
matA.append(matA1)
matA=np.array(matA)
matB=[]
for i in range(0,order+1+1):
ty=0.0
for k in range(0,len(xa)):
dy=1.0
for l in range(0,i):
dy=dy*xa[k]
ty+=ya[k]*dy
matB.append(ty)
matB=np.array(matB)
matAA=np.linalg.solve(matA,matB)
#Draw the curve fitting
xxa= np.arange(-3,3,0.01)
yya=[]
for i in range(0,len(xxa)):
yy=0.0
for j in range(0,order+1+1):
dy=1.0
for k in range(0,j):
dy*=xxa[i]
dy*=matAA[j]
yy+=dy
yya.append(yy)
plt.plot(xxa,yya,color='r',linestyle='-',marker='')
def least_square_color2(y,order,error_x,error_y):
#The offset of each point on the generated curve
i=0
xa=[]
ya=[]
for xx in x:
yy=y[i]
d_x=np.random.normal(0,error_x)
d_y=np.random.normal(0,error_y)
i+=1
xa.append(xx+d_x)
ya.append(yy+d_y)
plt.plot(xa,ya,color='b',linestyle='',marker='.')
#Curve fitting
matA=[]
for i in range(0,order+1+1):
matA1=[]
for j in range(0,order+1+1):
tx=0.0
for k in range(0,len(xa)):
dx=1.0
for l in range(0,j+i):
dx=dx*xa[k]
tx+=dx
matA1.append(tx)
matA.append(matA1)
matA=np.array(matA)
matB=[]
for i in range(0,order+1+1):
ty=0.0
for k in range(0,len(xa)):
dy=1.0
for l in range(0,i):
dy=dy*xa[k]
ty+=ya[k]*dy
matB.append(ty)
matB=np.array(matB)
matAA=np.linalg.solve(matA,matB)
#Draw the curve fitting
xxa= np.arange(-3,3,0.01)
yya=[]
for i in range(0,len(xxa)):
yy=0.0
for j in range(0,order+1+1):
dy=1.0
for k in range(0,j):
dy*=xxa[i]
dy*=matAA[j]
yy+=dy
yya.append(yy)
plt.plot(xxa,yya,color='g',linestyle='-',marker='')
order=[1,2,3]
error_y=1
error_x_mat=[0.1,0.2]
''' x with noise 0~0.1: pink dots, red lines x with noise 0~0.2: blue dots, green lines '''
for order in range(len(order)):
for error_x in error_x_mat:
plt.subplot(330+order+1)
plt.ylabel('order={}'.format(order+1))
plt.title('y=2x+1',fontsize=10)
y = [2*a+1 for a in x]
if error_x==0.1:
least_square_color1(y,order,error_x,error_y)
else:
least_square_color2(y,order,error_x,error_y)
plt.subplot(333+order+1)
plt.ylabel('order={}'.format(order+1))
plt.title('$y=0.01x^{2}+2x+1$',fontsize=10)
y = [0.01*a*a+2*a+1 for a in x]
if error_x==0.1:
least_square_color1(y,order,error_x,error_y)
else:
least_square_color2(y,order,error_x,error_y)
plt.subplot(336+order+1)
plt.ylabel('order={}'.format(order+1))
plt.title('$y=0.1e^{0.1x}+2x+1$',fontsize=10)
y = [0.1*(math.e**(0.1*a))+2*a+1 for a in x]
if error_x==0.1:
least_square_color1(y,order,error_x,error_y)
else:
least_square_color2(y,order,error_x,error_y)
plt.legend()
plt.show()
结果如下:

按照任务要求,将九附图画在一张大图中,不同点和线的颜色代表对X施加不同的噪音,y轴噪音不变。不同阶数拟合曲线的差异还是很大的,当阶数过大时,过拟合现象会很明显,接下来我们详细讨论。
在原有的基础上加入奇异值:
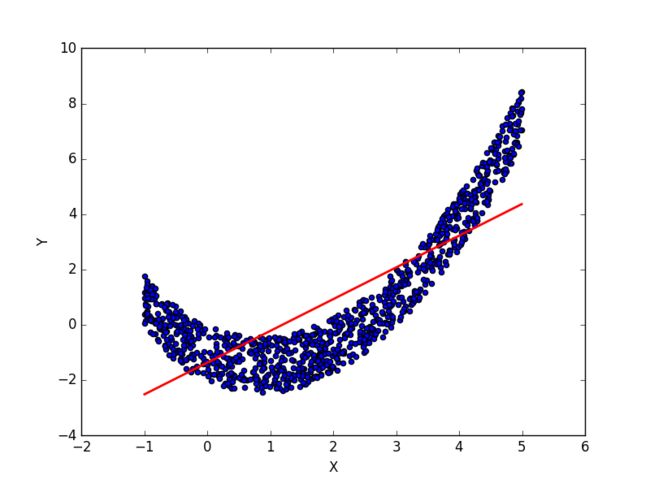
接下来的任务中要拟合所谓的‘RegData2D’数据集,其实画出来就是下面这个样子,主观感觉二阶多项式足以(就是红色那条):

但还是按照要求一步一步来……贝叶斯最大后验概率和最大似然估计的思想在我的上一篇博文中都经过仔细的推导,这里直接上代码:
首先是最大似然估计,仿照《Building Machine Learning Systems with Python》- Wili Richert这本书中最开始的例子,发现用自带库确实比之前自己写要高效的多得多:
# -*- coding:gb2312 -*-
from numpy import *
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
#txt中所有字符串读入data
a = []
with open('RegData2D.txt', 'r') as f:
data = f.readlines()
for line in data:
odom = line.split()
numbers_float = map(float, odom)
a.append(numbers_float)
a = np.array(a)
x_train = []
y_train = []
x_train.append(a[0:500, 0])
y_train.append(a[0:500:, 1])
x_train = np.array(x_train[0])
y_train = np.array(y_train[0])
x_text = []
y_text = []
x_text.append(a[501:, 0])
y_text.append(a[501:, 1])
x_text = np.array(x_text[0])
y_text = np.array(y_text[0])
# draw data
plt.figure(1)
plt.scatter(x_train, y_train, s=5)
#
def error(f, x, y):
return sp.sum((f(x) - y) ** 2)
# 多项式拟合
# 1次
fp1, res1, rank1, sv1, rcond1 = sp.polyfit(x_train, y_train, 1, full=True)
f1 = sp.poly1d(fp1)
# print f1
# 2次
fp2, res2, rank2, sv2, rcond2 = sp.polyfit(x_train, y_train, 2, full=True)
f2 = sp.poly1d(fp2)
# print f2
# 3次
fp3, res3, rank3, sv3, rcond3 = sp.polyfit(x_train, y_train, 3, full=True)
f3 = sp.poly1d(fp3)
# print f3
# 10次
fp10, res10, rank10, sv10, rcond10 = sp.polyfit(x_train, y_train, 10, full=True)
f10 = sp.poly1d(fp10)
# print f10
# 100次
fp100, res100, rank100, sv100, rcond100 = sp.polyfit(x_train, y_train, 100, full=True)
f100 = sp.poly1d(fp100)
# print f100
fx = sp.linspace(-1, 5, 1000)
plt.plot(fx, f1(fx), linewidth=1)
#plt.legend("%d" % f1.order, loc="upper left")
plt.plot(fx, f2(fx), linewidth=1)
#plt.legend("d= %d" % f2.order, loc="upper left")
plt.plot(fx, f3(fx), linewidth=1)
#plt.legend("d= %d" % f3.order, loc="upper left")
plt.plot(fx, f10(fx), linewidth=1)
#plt.legend("d= %d" % f10.order, loc="upper left")
plt.plot(fx, f100(fx), linewidth=1)
#plt.legend("d= %d" % f100.order, loc="upper left")
# 画出error曲线
plt.figure(2)
error_train = []
error_text = []
order = []
for i in range(3):
order.append(i + 1)
for j in order:
fp, res, rank, sv, rcond = sp.polyfit(x_train, y_train, j, full=True)
f = sp.poly1d(fp)
#print("Train Error of the model:", {j}, error(f, x_train, y_train))
print("Text Error of the model:", {j}, error(f, x_text, y_text))
error_numtrain = error(f, x_train, y_train)
error_numtext = error(f, x_text, y_text)
error_train.append(error_numtrain)
error_text.append(error_numtext)
plt.plot(order, error_train, 'r--')
plt.plot(order, error_text, 'g-')
plt.title("Red for train error. Green for text error")
plt.show()
我也是懒得可以,建个列表写循环都觉得麻烦……真是丑陋啊。结果分析如下:
[1]. Underfitting的情况,当多项式阶数取1时:
Correctfitting的情况,多项式阶数取2时:

Overfitting的情况,多项式阶数取100时:

由于RegData2D数据集的规律性,只有当order = 1时回归曲线Underfitting的情况十分明显,之后阶数增加,回归曲线的变化并不明显,当order > 100时Overfitting变得比较明显,下图中可以明显看出,order = 2,3,10的回归曲线几乎是重合在一起的:

[2]. 取RegData2D数据集中前500个样本做train_data,后500做text_data,多项式阶数从1取至100,分别画出误差变化曲线:

可以明显看出,仅在order = 1时,均方误差很大,之后变化不明显,测试误差大于训练误差。当阶数取值更高时,可以看出从order = 2起训练误差逐渐降低,测试误差逐渐升高:
结论:order = 2时得到最优回归曲线:y = 0.5581 x^2 - 1.056 x - 0.9284
接下来在最大似然估计的基础上加入后验信息:w = (X^T * X + a*I)^(-1) * X^T * y,发现只要在我们一开始的最小二乘法上加一点东西就好,对a取任意值,找到使训练误差最小的a值:
# -*- coding:gb2312 -*-
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
class regression(object):
def __init__(self, data_x, data_y, data_z, order, x_left_limit, x_right_limit, a):
self.data_x = data_x
self.data_y = data_y
self.data_z = data_z
self.order = order
self.x_left_limit = x_left_limit
self.x_right_limit = x_right_limit
self.a = a
# 岭回归
def least_square(self):
matA = []
for i in range(0, self.order + 1):
matA1 = []
for j in range(0, self.order + 1):
tx = 0.0
for k in range(0, len(self.data_x)):
dx = 1.0
for l in range(0, j + i):
dx = dx * self.data_x[k]
tx += dx
matA1.append(tx)
matA.append(matA1)
matA = np.array(matA)
# print matA.shape
matB = []
for i in range(0, self.order + 1):
ty = 0.0
for k in range(0, len(self.data_x)):
dy = 1.0
for l in range(0, i):
dy = dy * self.data_x[k]
ty += self.data_y[k] * dy
matB.append(ty)
matB = np.array(matB)
I = np.identity(self.order + 1)
matAA = np.linalg.solve(matA + self.a * I, matB)
# print matAA
def error(f, x, y):
return sp.sum((f(x) - y) ** 2)
matAAlist = list(matAA)
matAAlist.reverse()
matAAuse = np.array(matAAlist)
f = sp.poly1d(matAAuse)
print("Train Error of the model:", {self.a}, error(f, self.data_x, self.data_y))
# Draw the curve fitting
xxa = np.arange(self.x_left_limit, self.x_right_limit, 0.01)
yya = []
for i in range(0, len(xxa)):
yy = 0.0
for j in range(0, self.order + 1):
dy = 1.0
for k in range(0, j):
dy *= xxa[i]
dy *= matAA[j]
yy += dy
yya.append(yy)
# plt.plot(xxa, yya, 'r-', linewidth = 2.0)
return matAA, xxa, yya, error(f, self.data_x, self.data_y)
# -*- coding:gb2312 -*-
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from class_regression import *
# 打印出RegData2D数据集中的随机样本
def print_RegData2D():
data = sp.genfromtxt("RegData2D.txt")
RegData2D_x = data[:, 0]
RegData2D_y = data[:, 1]
plt.scatter(RegData2D_x, RegData2D_y)
plt.xlabel("X")
plt.ylabel("Y")
x_min = min(RegData2D_x)
x_max = max(RegData2D_x)
return RegData2D_x, RegData2D_y, x_min, x_max
# 最小二乘法
x, y, x_min, x_max = print_RegData2D()
a = []
for i in range(1):
a.append(i)
error_a = []
for j in range(len(a)):
RegData2D = regression(x, y, [], 1, x_min, x_max, a[j])
pra, fx, fy, error = RegData2D.least_square()
error_a.append(error)
plt.plot(fx, fy, 'r-', linewidth = 2)
plt.figure(2)
plt.plot(a, error_a, 'r-')
''' if order[i] == 2: plt.plot(fx, fy, 'k-', linewidth = 1.0) for i in range(len(order)): RegData2D = regression(x, y, [], order[i], x_min, x_max, 100) pra, fx, fy = RegData2D.least_square() if order[i] == 1: plt.plot(fx, fy, 'r-', linewidth = 1.0) elif order[i] == 2: plt.plot(fx, fy, 'r-', linewidth = 1.0) elif order[i] == 3: plt.plot(fx, fy, 'g-', linewidth = 2.0) elif order[i] == 5: plt.plot(fx, fy, 'y-', linewidth = 2.0) elif order[i] == 10: plt.plot(fx, fy, 'k-', linewidth = 2.0) elif order[i] == 100: plt.plot(fx, fy, 'w-', linewidth = 2.0) '''
plt.show()
取RegData2D数据集全部作为训练集,取order = 2,a = [0, 100],可以看出a的取值对回归曲线的影响不大:

回归曲线几乎重合在一起,训练集的误差曲线见下图,a = 0时即最大似然估计:
结论:对于RegData2D数据集,order = 2,a = 0时得到最优的回归曲线。
单纯从多项式拟合的角度去处理数据集,得到的多项式与老师所给的式子差距甚远,还需要很多方法来进一步缩小误差和细化函数,我们之后讨论。