星环科技创始人兼CTO孙元浩:现代数据仓库的技术演变和关键特性
【CSDN现场报道】2015年12月10-12日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、北京中科天玑科技有限公司与CSDN共同协办,以“数据安全、深度分析、行业应用”为主题的 2015中国大数据技术大会 (Big Data Technology Conference 2015,BDTC 2015)在北京新云南皇冠假日酒店盛大开幕。
2015中国大数据 技术大会首日全体会议中,星环科技创始人兼CTO孙元浩带来了名为“现代数据仓库的技术演变和关键特性”的主题演讲。期间,星环科技创始人兼CTO孙元浩首先介绍了传统数据仓库面临的问题: 数据量增长过快,导致运算效率下降;数据抽取处理的代价过高,无法在统一的视图下处理;无法处理多种类型的数据;不具备进行搜索或关联分析以发现隐藏关系的能力;不具备数据挖掘等高级分析的能力。随后,他详细介绍了新时代逻辑数据仓库需要具备的特性:数据、计算均分布化;需要具备对多种关系数据库和Hadoop数据源进行交叉查询、聚合、以及关联操作等能力;混合负载和多租户SLA管理能力。在多租户资源管理用例中,孙元浩指出2014到2015资源调度框架之争,Mesos和Kubernetes逐渐占据优势,YARN被边缘化。
星环科技创始人兼CTO 孙元浩
以下为演讲实录
孙元浩:
首先,一句话介绍一下星环科技——一家专门做Hoddp发行和基础软件的公司。目前来讲,在Hadoop之上的数据引擎和流处理引擎在技术上远远领先于国外的同行。首先,看什么是数据仓库,这张图也在帮助企业客户建设数据仓库,有的是数据库,或者是一个数据库管理系统,也有企业是用一体机来建造数据仓库。按照这个是表现形态而言,是表象,实质不一定是数据库的形态,这里就像这张图一样,左边这张图大家可以看到,有的人看出来是一个酒杯,有的人看出来是两个人脸的侧面,如果只从表面看数据仓库就是一个数据库,数据仓库的本质可以看成是一个集中化的数据平台,把所有数据全部集中在一个平台上面进行数据的加工、处理和挖掘。这一块使得现在Gartner把数据仓库慢慢开始改了一个名称,2015年改成了数据仓库和数据管理的魔力象限,意味着在数据仓库当中引入一些的技术,尤其像Hadoop的技术作为数据仓库。为什么要引入这个,一个重要的原因是传统数据仓库已经碰到各种瓶颈。
传统数据库所遭遇的瓶颈
数据量增长过快,导致运算效率下降;数据抽取处理的代价过高,无法在统一的视图下处理;无法处理多种类型的数据;不具备进行搜索或关联分析以发现隐藏关系的能力;不具备数据挖掘等高级分析的能力。具体来看,在一个银行风险分析、客户精细化营销的案例中,各种类型数据库往往会有以下表现。
传统数据仓库——本使用案例涉及管理来自多种结构化数据源的历史数据。该数据主要通过批量载入。传统数据仓库使用案例可管理大量数据,主要用于标准报表和仪表盘。其次,该使用案例还用于自由模式查询和挖掘或操作型查询。考虑到用于查询的混合工作负载能力和使用者的技能差异,传统数据仓库使用案例需要系统高可用性以及强大的执行和管理能力。
操作型数据仓库——本使用案例管理连续载入的结构化数据,以支持应用、实时数据仓库和操作型数据存储内的嵌入式分析。本使用案例主要支持报表和自动化查询,以支持操作需求。本使用案例将需要高可用性与灾难性恢复能力,以满足操作需要。由于操作型数据仓库使用案例的主要目的是实现卓越的操作性能,所以管理不同类型使用者或即席查询(ad hoc querying)、挖掘等不同类型工作负载的重要性较低。
逻辑数据仓库——本使用案例需要针对结构化数据和其它内容数据类型,管理数据多样性和数据量。除来自交易应用的结构化数据外,本使用案例还包括机器数据、文本文档、图片和视频等其它内容数据类型。因为其它内容类型能够产生大量数据,所以管理大量数据成为重要标准。逻辑数据仓库还能够满足不同查询能力的需求,并支持不同的使用者技能。本使用案例支持数据仓库数据库管理系统及其它数据源的查询。
上下文独立式(context-independent)数据仓库 – 本使用案例体现出新的数据价值、数据形式变种(variants)和新的数据关系。它支持搜索、图表和其它高级功能,以发现新的信息模型。本使用案例主要用于自由模式的查询,以支持预测、预测性建模或其它挖掘形式,以及支持多种数据类型和数据源的查询。它没有操作性要求,可帮助数据科学家或商业分析师等高级用户实现未来多种数据类型的自由模式查询。
逻辑数据库需具备的四个特性
总结了一下在全新的数据仓库当中包括逻辑数据仓库当中需要四个特性,这四个特性也是构建罗列数据仓库来讲是至关重要的。
第一点我们认为必须要采用分布式计算,在数据库领域计算模式已经演变成了好几次,从最早单机版计算,再到计算引擎分布,到最后计算和存储全部被分布式,像Hadoop这种方式,是全分布式的计算方式,这种方式带来两个好处,一个好处是扩展性是非常好的,可以完全扩展,完全可以横向扩展,其次因为Hadoop更好一些这也是它扩展性更好的原因。现在基本上都是采用分布式的方式,同时可以看到右边一张图是最新的报告,这里为什么是100T,大型企业数据仓库通常在100左右,中型企业数据量通常在30T以下,小型企业数量不会超过10个T,我们从1T到100T都跑了一遍用了29台机器,这个性能从1个小时40个小时都有,这个数据也是证明了用Hoddp可以完全胜任数据仓库的任务,这是一个非常有技术挑战性的工作。在Hadoop搜索引擎以后完全能够跑完100T,在Hadoop技术的应用客户数量越来越大,在一些客户当中单一数量已经到20个GP。这个也就证明了分布式计算已经开始成熟到取代关联性的数据仓库来做复杂的大容量的统计分析。
第二个是刚才提到的我们需要一个数据联邦技术,需要能够通过SQL引擎访问多个数据库,这个是产品的架构图,这里数据不是简单的看成是一个数据源的抽象,会给每个数据源一个驱动,主要的目的是,首先我们做这一层把计算分布式化,本身计算引擎是分布式的,会把一些计算场景,本来数据源的特性,这些特性会放到数据源上做,可以减少数据传输量,这种方式可以使多种数据源进行交叉分析,能够把甲骨文的表和Hadoop格式的表能够进行交易,为什么有这种需求,一家企业数据源是非常多,几百个,通常有客户是两百多个数据库,很难把所有的数据实时到同一个仓库当中,需要实时的访问原来数据源。其实在这个领域有两个流派,传统的数据库厂商希望用连接器覆盖Hadoop,可以看到甲骨文,他们这种方法希望把Hadoop掩隐藏在他们的执行引擎上面, 他们只是把Hadoop作为一个存储。但是这种方式没有把计算完全分布出来。我们是完全反过来,我们希望用Hadoop原先的搜索引擎覆盖原来的数据库,使原来的数据库和Hoddp都作为同一种数据源进行完全分布式的计算。我们认为这种方式会更符合未来的技术趋势,因为我的计算可以被完全分布式化,我的扩展性比原来的好很多,混合架构在未来三年会小时掉。
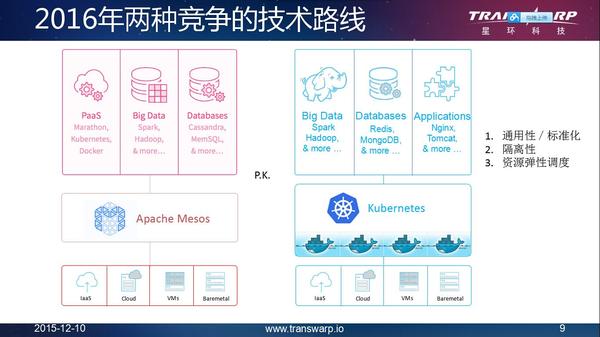
明年我们看到这种技术会成为一种PK状态,同时有了这个技术以后,其实对数据仓库的开发和运维,甚至对整个开发软件的模式发生一些重要的变化,这时我们看到基于Docker的方式出现,今天可以把整个应用系统、运营系统通常分为三个架构:前端、中间件和数据库层,这三层完全可以变成微服务,应用系统其实都是用微服务的模块组建的,只要描述依赖性就可以了,把这个依赖性告诉底下的系统,你的应用就像打包一个集装箱一样的所有的模块都可以组建,这种方式对现在的应用开发方式产生非常大的变化,对应用迁移带来非常巨大的便捷性。
我们在这边重新开发了一个调度器,而且调度的功能也超过了YARN的调动能力。这种调度器我们同时支持CPU网络内存的调度,上面可以一键式的启动平台层的服务,包括数据库、Hadoop,,未来数据库的方式可以通过这种方式。再往上你的应用层可以直接我们都可以一键式的上传上去进行部署,而且想把一个服务扩展的话,可以在很早的时间内扩展到上万个。有了这套系统以后可以轻易的建造一个有几万个容器应用系统,在上面可以跑几千个应用,扩展性可以在扩展到上千,也可以下线非常短的应用,在上面可以跑上千个应用。
第四个关键特性应该具备预测性分析的能力。预测非常难,今天很难有人预测08年经济危机,可能从来没有成功过预测过经济危机,这里面其实有很多的原因,包括现在的企业他们想做预测性的工作,特别是大数据当时讲很多的故事可以预测,但是这种寓言的准确度是至关重要的,其中的准确度从来没有高过,这里也有一些重要的原因,过去是因为没有大规模软件系统来存放大量的数据,也无法对数据进行分析。其次计算模型过于简单,过去的计算能力不能进行一种复杂的计算复习。
除此以外,我们认为做分析还要具备一些特征,首先是需要三个工具,第一个是通过一种方式在大量的数据中作出一个特征出来;第二个需要分布式的算法库,今天的分布式算法库数量仍然不够多和全,我们需要有更完整的算法列表;第三是需要应用工具帮我建造完整的(英语),让我能够方便的做数据分析,我们才能解决方案。今天我们初步探索这个领域,发现该领域成功的案例非常少,不管是国内还是国外,现在尝试的方法把R语言作为Hadoop的一等公民跟(英语)一样,我们会自动把R语言的算法自动化掉,所有的数据科学家不需要学习新的语言,用原生的R就可以了,我们会自动编译。同时我们也提供像HUE简易的工具做数据特征抽取,但是这些东西仍然只是尝试,仍然没有得到大规模的应用,这是大数据真正成功的一个关键特性,也是数据仓库在未来想用大数据做分析挖掘的必不可少的功能。
今天我介绍是数据仓库的四大特性,我们也看到数据仓库的技术演变速度非常快,但未来三年当中数据仓库技术会发生非常大的变化,与此同时,我们看到在未来三年当中,大部分企业级客户会把传统的数据仓库变成罗列数仓,Hadoop会扮演重要的角色,现在很多企业客户把Hoddp作为最基础的数据平台,而且完全可以不用管理数据库。
更多精彩内容,请关注直播专题 2015中国大数据技术大会(BDTC),新浪微博@CSDN云计算,订阅CSDN大数据微信号。