支持向量机 - 1 - 准备知识和介绍
声明:
1,本篇为个人对《2012.李航.统计学习方法.pdf》的学习总结,不得用作商用,欢迎转载,但请注明出处(即:本帖地址)。
2,由于本人在学习初始时有很多数学知识都已忘记,所以为了弄懂其中的内容查阅了很多资料,所以里面应该会有引用其他帖子的小部分内容,如果原作者看到可以私信我,我会将您的帖子的地址付到下面。
3,如果有内容错误或不准确欢迎大家指正。
4,如果能帮到你,那真是太好了。
准备
在看支持向量积之前,我们先简单的了解如下几个东西:
以下内容均摘自百度百科。
1,先验知识和后验知识
先验知识:不依赖与经验的知识。
如:乔治至少在位4天,那么他在位的时间多于3天。这个靠推论就可以得出,不以赖与经验。
后验知识:依赖于经验或经验性证据的知识。
如:乔治在位的时间是1910年到1936年,这是一种经验事实,它不能单独通过推论得出。
2,核方法
概括地说
所谓的核方法就是一类模式识别的算法,它的目的是找出并学习一组数据中的相互关系。用途较广的核方法有支持向量机、高斯过程等。
核心思想
核方法主要用来解决非线性模式分析问题,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
核心思想解释
核方法的核心思想是基于这样一个假设:在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很可能变为线性可分的。
用几何图形说明的话是这样:
对于下面这张图:
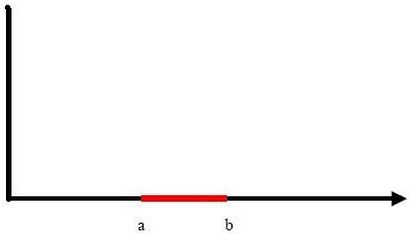
我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
但我们可以找到一条曲线来划分它,如下图所示:
然后第一张图中我们无法用一个线性函数(一维)来区分的类,用曲线(二维)中就可以区分了。
用代数说明的话就是:
例如有两类数据:一类x<a U x>b;另一类 a<x<b。想要在一维空间上线性分开是不可能的(你画个长方形把a<x<b这一类给框起来倒是可以,但这还是一维的吗)。然而我们可以通过F(x) = (x-a)(x-b) 把一维空间上的点转化到二维空间上,这样就可以划分两类数据F(x) > 0,F(x) < 0;从而实现线性分割。
概括来说就是一句话:给“低维上无法线性分类的数据”提升维度使其在“高维上可以线性分割”。
优势
同样是解决非线性问题,那核方法的优势是什么?
首先,通用非线性学习器不便反应具体应用问题的特性,而核方法的非线性映射由于面向具体应用问题设计而便于集成问题相关的先验知识。
再者,线性学习器相对于非线性学习器有更好的过拟合控制从而可以更好地保证泛化性能。
还有,很重要的一点是核方法还是实现高效计算的途径,它能利用核函数将非线性映射隐含在线性学习器中进行同步计算,使得计算复杂度与高维特征空间的维数无关。
核函数
然后什么样的函数是核函数?即核函数的存在性判断和如何构造?或者说怎么才能判断一个函数是否是核函数呢?
答案是:任何半正定的函数都可以作为核函数。不过这个只是个充分条件,还有些不满足上面的条件但也是核函数的函数。
当然了,在实际应用中往往根据经验来选择现有的核函数。
遇到的问题
核方法是直接把低维度的数据转化到高维度的空间中,然后再寻找线性分割平面。
不过这会遇到两个大问题,一是由于是在高维度空间中计算,导致维度祸根(curse of dimension)问题;二是非常的麻烦,每一个点都必须先转换到高维度空间,然后求取分割平面的参数等等;怎么解决这些问题?答案是通过核戏法(kernel trick)。
| 维度祸根也叫维度之咒,是一个最早由Richard Bellman提出来的术语,用来描述当(数学)空间维度增加时,体积指数增加的难题。 举例来说,100个平均分布的点能把一个单位区间以每个点距离不超过0.01采样;而当维度增加到10后,如果以相邻点距离不超过0.01小方格采样一单位超正方体,则需要10^20个采样点:所以,这个10维的超正方体也可以说是比单位区间大10^18倍。(这个是Richard Bellman所举的例子) |
核戏法
定义一个核函数K(x1,x2)= <φ(x1),φ(x2)>, 其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),φ(xi)是低维度空间的点xi转化为高维度空间中的点的表示,< , > 表示向量的内积。这里核函数K(x1,x2)的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式。
这种核函数巧妙地解决了上述的问题,在高维度中向量的内积通过低维度的点的核函数就可以计算了。这种技巧被称为Kernel trick。
核方法不是万能的
首先这里有一个问题:“为什么我们要关心向量的内积?”,一般地,我们可以把分类(或者回归)的问题分为两类:参数学习的形式和基于实例的学习形式。参数学习的形式就是通过一堆训练数据,把相应模型的参数给学习出来,然后训练数据就没有用了,对于新的数据,用学习出来的参数即可以得到相应的结论;而基于实例的学习(又叫基于内存的学习)则是在预测的时候也会使用训练数据,如KNN算法。而基于实例的学习一般就需要判定两个点之间的相似程度,一般就通过向量的内积来表达。从这里可以看出,核方法不是万能的,它一般只针对基于实例的学习。
3,二次规划
二次规划的一般形式可以表示如下图:
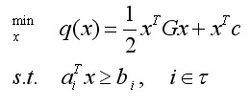
其中G是Hessian矩阵,τ是有限指标集,c,x和{ai},都是R中的向量。如果Hessian矩阵是半正定的,则我们说上式是一个凸二次规划,在这种情况下该问题的困难程度类似于线性规划(如果=0,二次规划问题就变成线性规划问题了)。如果有至少一个向量满足约束并且在可行域有下界,则凸二次规划问题就有一个全局最小值。如果是正定的,则这类二次规划为严格的凸二次规划,那么全局最小值就是唯一的。如果是一个不定矩阵,则为非凸二次规划,这类二次规划更有挑战性,因为它们有多个平稳点和局部极小值点。
| 正定矩阵和半正定矩阵: 设M是n阶方阵,如果对任何非零向量z,都有zTMz> 0,其中zT 表示z的转置,就称M正定矩阵。如果zTMz≥0,就称M是半正定矩阵。 |
4,不适定问题
在经典的数学物理中,人们只研究适定问题。适定问题是指满足下列三个要求的问题:①解是存在的(存在性);②解是惟一的(唯一性);③解连续依赖于初边值条件(稳定性)。这三个要求中,只要有一个不满足,则称之为不适定问题。特别,如果条件③不满足,那么就称为阿达马意义下的不适定问题。一般地说不适定问题,常常是指阿达马意义下的不适定问题。
5,正则化
正则化就是对最小化经验误差函数上加约束,这样的约束可以解释为先验知识(正则化参数等价于对参数引入先验分布)。
正则化的目的:避免出现过拟合(over-fitting)
经验风险最小化 + 正则化项 = 结构风险最小化
经验风险最小化(ERM),是为了让拟合的误差足够小,即:对训练数据的预测误差很小。
但是,我们学习得到的模型,当然是希望对未知数据有很好的预测能力(泛化能力),这样才更有意义。
当拟合的误差足够小的时候,可能是模型参数较多,模型比较复杂,此时模型的泛化能力一般。于是,我们增加一个正则化项,它是一个正的常数乘以模型复杂度的函数,aJ(f),a>=0 用于调整ERM与模型复杂度的关系。
结构风险最小化(SRM),相当于是要求拟合的误差足够小,同时模型不要太复杂(正则化项的极小化),这样得到的模型具有较强的泛化能力。
6,欧式空间:
设V是实数域R上一线性空间,在V上定义了一个二元实函数,称为内积,记作(@,#), 它具有以下性质:
1)(@,#)=(#,@);
2)(k@,#)=k(@,#);
3)(@+#,$)=(@,$)+(#,$);
4)(@,@)>=0,当且仅当@=0时(@,@)=0.
这里@,#,$是V中任意的向量,k是任意实数,这样的线性空间V称为欧几里得空间.
7,希尔伯特空间:
作者:qang pan
链接:http://www.zhihu.com/question/19967778/answer/28403912
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么是赋范线性空间、内积空间,度量空间,希尔伯特空间?
现代数学的一个特点就是以集合为研究对象,这样的好处就是可以将很多不同问题的本质抽象出来,变成同一个问题,当然这样的坏处就是描述起来比较抽象,很多人就难以理解了。
既然是研究集合,每个人感兴趣的角度不同,研究的方向也就不同。为了能有效地研究集合,必须给集合赋予一些“结构”(从一些具体问题抽象出来的结构)。
从数学的本质来看,最基本的集合有两类:线性空间(有线性结构的集合)、度量空间(有度量结构的集合)。
对线性空间而言,主要研究集合的描述,直观地说就是如何清楚地告诉地别人这个集合是什么样子。为了描述清楚,就引入了基(相当于三维空间中的坐标系)的概念,所以对于一个线性空间来说,只要知道其基即可,集合中的元素只要知道其在给定基下的坐标即可。
但线性空间中的元素没有“长度”(相当于三维空间中线段的长度),为了量化线性空间中的元素,所以又在线性空间引入特殊的“长度”,即范数。赋予了范数的线性空间即称为赋范线性空间。
但赋范线性空间中两个元素之间没有角度的概念,为了解决该问题,所以在线性空间中又引入了内积的概念,从而形成了内积空间。
因为有度量,所以可以在度量空间、赋范线性空间以及内积空间中引入极限,但抽象空间中的极限与实数上的极限有一个很大的不同就是,极限点可能不在原来给定的集合中,所以又引入了完备的概念,完备的内积空间就称为Hilbert空间。
这几个空间之间的关系是:
线性空间与度量空间是两个不同的概念,没有交集。
赋范线性空间就是赋予了范数的线性空间,也是度量空间(具有线性结构的度量空间)
内积空间是赋范线性空间
希尔伯特空间就是完备的内积空间。
为什么这个叫支持向量机
为了弄清楚这个,我们的先看看什么是支持向量。
支持向量
在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量。(注意是线性可分的情况下,对于非线性可分的情况还需要进一步讨论,不过这里只是为了理解何为支持向量机,所以只讨论线性可分的情况就足够了)
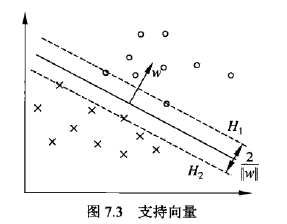
如上图,H1和H2上的点就是支持向量。
而对于支持向量机来说,因为它以“距离样本点的间隔最大”为宗旨来选择分离超平面。所以如果经过各个支持向量(分离超平面的两侧都会有支持向量)画平行于分离超平面的线(也就是上图的H1和H2)的话,那H1和H2之间一定没有任何实例点存在。
这说明什么?
这说明,如果移动支持向量的话将改变分离超平面,但是移动其他的实例点,甚至去掉这些点,都不会对分离超平面有任何影响。
换句话说,在决定分离超平面时只有支持向量起作用,而其他实例点都不起作用。
所以将这种模型称为支持向量机。
而看了上面这些话,就应该能够理解这句话了:支持向量机由很少的“重要的”训练样本确定。
间隔边界
里面的H1和H2就是间隔边界。
介绍
支持向量机(SVM)是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,而这个间隔最大就使得它有别于感知机。
支持向量机实质上是非线性分类器,他的学习策略就是间隔最大化。
支持向量机的学习策略是求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
支持向量机的学习方法包含下面三种模型:
线性可分支持向量机、线性支持向量机 和 非线性支持向量机。
线性可分支持向量机:当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机。
线性支持向量机:当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,这就是线性支持向量机,又称为软间隔支持向量机。
非线性支持向量机:当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
然后这里考虑一个二分类问题:对于一个输入空间和特征空间,向量机是如何将输入空间中的元素映射到特征空间?
答案是:对于线性可分支持向量机和线性支持向量机,它们会假设这两个空间的元素一一对应,然后将输入空间中的输入映射为特征空间中的特征向量。而对于非线性支持向量机,则利用一个从输入空间到特征空间的非线性映射,将输入映射为特征向量。
所以,输入都由输入空间转换到特征空间,而支持向量机的学习就是在特征空间上进行的。