空间金字塔方法表示图像
注:本学习笔记是自己的理解,如有错误的地方,请大家指正,共同学习进步。
本文学习自CVPR论文《Discriminative Spatial Pyramid》、《Discriminative Spatial Saliency for Image Classification》及《Beyond Bags of Features: Spatial Pyramid Matching
for Recognizing Natural Scene Categories》,在此感谢论文作者。
空间金字塔方法表示图像是传统BOF(Bag Of Features)方法的改进,传统BOF方法提取图像特征时,首先提取每张图像的SIFT特征描述,之后将所有图像的兴趣点的特征描述进行聚类形成BOW视觉词袋,最后对每张图像统计所有视觉关键词出现的频次。因此BOF是在整张图像中计算特征点的分布特征,进而生成全局直方图,所以会丢失图像的空间分布信息,无法对图像进行精确地识别。为了克服BOF的这一缺点,提出了空间金字塔方法,它是在不同分辨率上统计图像特征点分布,从而获取图像的空间信息。 图像被划分为金字塔各水平上的逐渐精细的网格序列,从每个网格中导出特征并组合为一个很大的特征向量。
1、图像尺度空间
SIFT中的图像尺度空间可以理解为用高斯对图像做了卷积,图像的分辨率还是那么大,像素还是那么多,只是细节被平均(平滑)掉了,原因就是高斯了,用周围的信号比较弱的像素和中间那个信号比较强的点做平均,平均值当然比最强信号值小了,这就起到了平滑的作用。如下图所示:
尺度可变高斯函数:
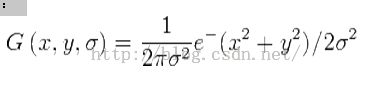
2、图像金字塔
金字塔是图像多尺度表示的主要形式,图像金字塔是以多分辨率来解释图像的一种有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低的图像集合。如下图所示。

图像金字塔化一般包括二个步骤:1、利用低通滤波器平滑图像;2、对平滑图像进行抽样,从而得到一系列尺寸缩小的图像。
3、空间金字塔表示图像
《Discriminative Spatial Pyramid》
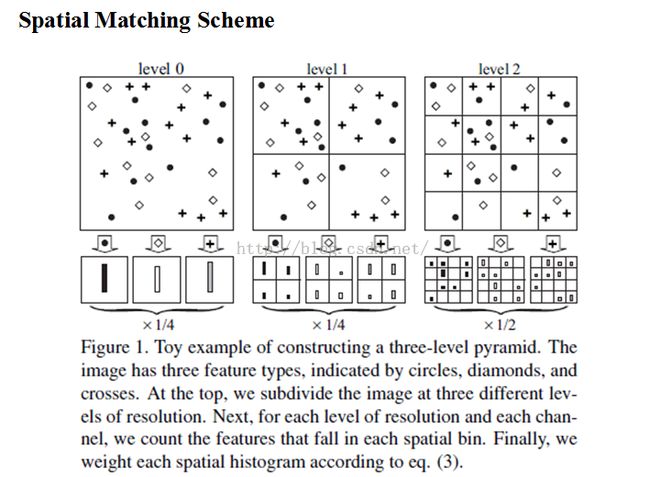
原始方法是首先提取原图像的全局特征,然后在每个金字塔水平把图像划分为细网格序列,从每个金字塔水平的每个网格中提取出特征,并把它们连接成一个大特征向量。但由于图像中每个局部区域反映的信息量不同,由此提出加权空间金字塔方法,及给每层每网格分配一个权重,按权重把每层每网格特征加权串联在一起。如下图:

左边图像是原始方法,右边是加权方法。
fkl表示第l层第k网格的特征向量,特征用d维向量表示,c(l)表示l层金字塔的网格数。原始方法中,一幅图像的空间金字塔特征向量表示为fs,如下:

加权方法表示为fw,如下:

4、空间金字塔匹配SPM
《Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories》
空间金字塔匹配Spatial Pyramid Matching(SPM),是一种利用空间金字塔进行图像匹配、识别、分类的算法。
如下图所示,将level(i)的图像划分为pow(4,i)个cell(bins),然后再每一cell上统计直方图特征,最后将所有level的直方图特征连接起来组成一个vector,作为图形的feature。
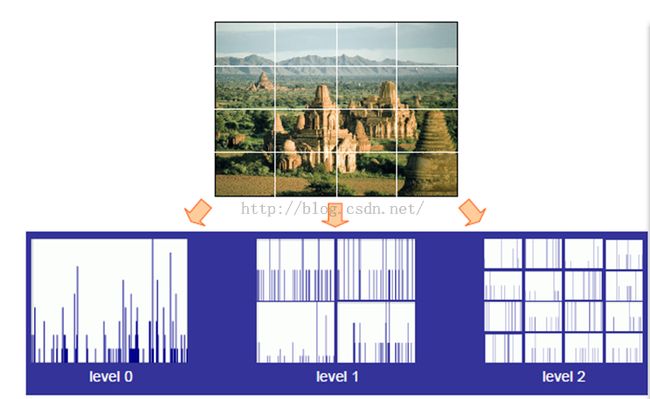
上面的黑圆点、方块、十字星代表一副图像上某个pitch属于k-means后词典中的某个词;
1)将图像划分为固定大小的块,如从左到右:1*1,2*2,4*4, 然后统计每个方块中词中的不同word的个数;
2)从从左到右,统计不同level中各个块内的直方图;
3)最后个将每个level中获得的直方图都串联起来,并且给每个level赋给相应的权重,从左到右权重依次增大;
4)将SPM放入SVM中进行训练和预测;
论文中的实验过程如下:
1)用 strong feature detector即SIFT进行特征检测,patch size=16*16,patch每次移动的步长spacing grid=8*8。
2)按照BOF相同的方法(即KMeans)构建包含M个words的dictionary。
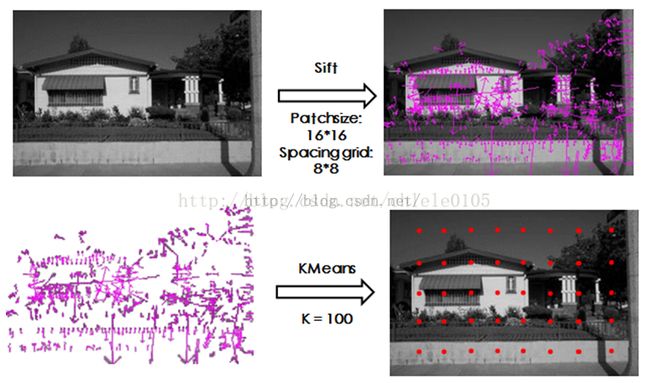
3)利用图像金字塔把图像划分为多个scales的bins(空间金字塔分层分网格),然后计算落入每个bins中属于不同类别的word的个数,则图像X、Y最终的匹配度为(M为关键词个数):(个人对此匹配度核函数的理解是:这个核函数可当作SVM中的核函数,来匹配两幅图像是否为一类)
