mysql-proxy学习(四)——性能测试
1. 硬件配置
hwconfig
Summary: Intel S5500WBV, 2 x Xeon E5620 2.40GHz,23.5GB / 24GB 1067MHz
System: Intel S5500WBV
Processors: 2 x Xeon E5620 2.40GHz 133MHz FSB (HTenabled, 8 cores, 16 threads)
Memory: 23.5GB / 24GB 1067MHz == 6 x 4GB, 2 xempty
千兆网卡
2. 测试case
长连接每个连接发送100,000 select 1的请求报文(即请求报文大小为13,响应报文大小为56)。建议在测试server前先用netperf测试一下网络环境,正常的局域网网络应该发送上面的报文应该可以达到300,000 PPS;并发60直接连接mysql-server qps可以达到90000。CMD:bin/mysql-proxy --daemon --pid-file=log/proxy.pid--proxy-address=:4040 --log-level=debug --log-file=log/proxy.log--proxy-backend-addresses=10.232.64.76:17907 --event-threads=16,即下面的测试不走lua脚本,也没有连接池 c-cons:b-cons = 1:1。
3. 实验数据
| Event-threads | Concurrent-cons | QPS | CPU | CS |
| 1 | 1 | 3800 | 30% | |
| 1 | 10 | 30000 | 96% | |
| 1 | 30 | 33000 | 100% | 400 |
| 4 | 1 | 4200 | 48% | |
| 4 | 10 | 37400 | 300% | |
| 4 | 30 | 53000 | 360% | 120000 |
| 4 | 50 | 69131 | 350% | 150000 |
| 4 | 80 | 67000 | 350% | 150000 |
| 12 | 1 | 3797 | 50% | 110000 |
| 12 | 5 | 20000 | 300% | 500000 |
| 12 | 12 | 37233 | 600% | 600000 |
| 12 | 30 | 51890 | 800% | 480000 |
| 12 | 50 | 53255 | 900% | 400000 |
| 12 | 80 | 53426 | 950% | 350000 |
| 16 | 10 | 29308 | 850% | 832000 |
| 16 | 30 | 48390 | 1110% | 580000 |
| 16 | 50 | 48056 | 1200% | 400000 |
| 16 | 80 | 47000 | 1350% | 300000 |
在测试的过程中通过mpstat -I SUM -u -P ALL 1,发现所有的网卡中断都只跑在0 CPU上,之前的网卡SMP是设置好的,然后使用perf导致机器挂了几次,重启后之前的SMP设置就无效了。所有上面的所有数据都是没有开通网卡SMP的数据(网卡SMP见http://jasonwu.me/category/Linux)。后面又试着把网卡的SMP开启,发现数据还不如上面的,不过差别不大低2000左右,本来以为开启了可以将intr及soft分摊到各个CPU上,以此来提高性能,最后摊是摊开了,但qps并没有上去。看来性能并不在内核网络处理上,集中式的单CPU处理已经可以达到上面我们的QPS甚至更高的要求,而开通SMP对于这种压力不够的影响可能是负的,至于原因超出了我现在的知识范围(可能是代码的亲缘性上去了,欢迎大牛指点);当然我们这里并不是说开通网卡的SMP会比不开好,只是我们现在的瓶颈还不在网卡的处理上,当我们上层的处理能力超过单CPU的网卡接收能力的话,那么此时开通网卡SMP,应该就可以达到更高的性能。
4. Mysql-proxy的网络模型
之前的文章里说过mysql-proxy是通过libevent的事件驱动的模型,但缺少介绍多线程在之个模型中的作用及关系:在mysql-proxy上线程是event-thread,即处理event的线程。Mysql-proxy主要有三类event fd:listen fd、socketpair[2]、net-read(write)。第一个很明显就是mysql的监听端口默认4040,这个事件只注册在main-thread线程上;第二个是一个socket对,即两个socket fd,其中socketpair[0]用于读(所有的线程都会关心这个event readable,回调函数chassis_event_handle),socketpair[1]用于写,当要add一个event(这个event就是第三类的event)的时候(chassis_event_add),会将该event放到一个全局的队列里,然后往socketpair[1]写一个”.”,然后所有线程都会被唤醒一次,唤醒后它们从全局队列里取得刚才保存的event,然后将这个event注册到自己的event-base上,那么当该event被触发的话,将由新的这个取得的线程来处理,另外,被唤醒的线程将尽量多取点event,只要它能够获得取队列的锁;第三类就是用于实际报文传送的read/write socket(它们的回调函数都是network_mysqld_con_handle),这一类与第二类的关系是:当我们要去recv或send socket的时候出现EAGAIN 错误,那么我们就应该去重新注册一下该事件(所有的第三类事件都是非EV_PERSIST),此时就会调用chassis_event_add函数,这就将触发新的event可能被别的线程获得处理。
扩展一下当多个event-threads的时候将会出现什么情况:①多个线程竞争一个event-queue;②当一个第三类socket出现EAGAIN,那么将唤醒所有的线程(惊群);③一个连接的client/severe socket不是固定在一个线程上执行,即任何的第三类event将随机的在任意线程上运行,在每次交互过程中都会发生变化迁移。简而言之就是event-thread不关心event是属于哪个连接的,它只关心这个event可用与否,当出现不可用时,它就该这个event push到全局的event-queue,然后唤醒所有的线程去竞争它。
上面是mysql-proxy的网络模型下面我们再来看一下核心处理流程。这个处理流程主要包括下面4个部分:报文接收发送event处理(network_mysqld_con_handle),该函数完成报文的读写、状态的判断转移;然后调用plugin_call,该函数根据状态获得相应状态下的hook function;再接下来执行状态的回调函数(proxy_read_auth_result,proxy_send_query_result,proxy_connect_server…);最后就是回调函数再去调用lua script里的相应函数,完成定制的任务(如读写分离,输出select报文,结果集等一系列的操作)。注:前面三个都是由代码编译后写死了,但第4个过程我们可以定制,修改,这也是mysql-proxy留着一个扩展的地方。另外即使我们上面没有指定lua script,但是前面三个过程都是要走的,只是第4个不会被调用。
5. 数据分析
了解了网络模型后,我们再来看一下上面的数据:首先对于1个event-thread的30个连接的时候CPU已经吃满了,显然再多个并发连接数也无益了。所以我们可以看到当event-thread增加到4的时候,同样的并发连接数QPS都上去了,另一个显著的变化是CS也上去了,这个就是因为上面我们说的惊群现象,它把所有的线程都唤醒一次,而且醒来后还得去竞争event-queue,这就无形中增加了多个上下文切换的时机。所以同样可以解释当并发越多的时候,CS就越大(在并发连接数相同的情况下),另外一个比较好解释的现象是在event-thread相同的情况下并发连接数越多,CS上升,然而奇怪的是当并发连接数再大的话CS反而下降,这个可能的原因是因为chassis_event_handle在取event的时候是尽可能多的取,当并发连接数多的时候,它可能一次会获得多个event,减少了event的扩散。
当然最令我不解的是为什么event-thread增加了QPS却下降了,我们以4个thread为参考值,那么我们系统16CPU,即使不能线性,那么折半应该不过分吧,那么多少也得69131 * 2 ~= 100000这个级别。当然有一种可能的解释是CS太多了,但以我个人的经验一般CS是果并不是因,也就是有其它真正的原因导致CS高,然后间接影响QPS,或者并不是CS的原因(因为当解决了这个瓶颈之后CS可能也会跟着下降下去),另外在16个event-threads的时候每个CPU上有user:sys:soft:idle大概=12%:65%:8%:15%;上面的现象MS现在通过代码不能那么容易的解释(个人实力未达),所以只能借助各种工具。
6. 工具分析
为了防止某个逻辑CPU单独执行某一种操作,影响测试结果,所以我们在进行性能排查的时候,我们又把网卡SMP设置为多个CPU。我们这里使用的检测工具是perf。通过perf record -g -p PID的方式,获得详细性能数据:
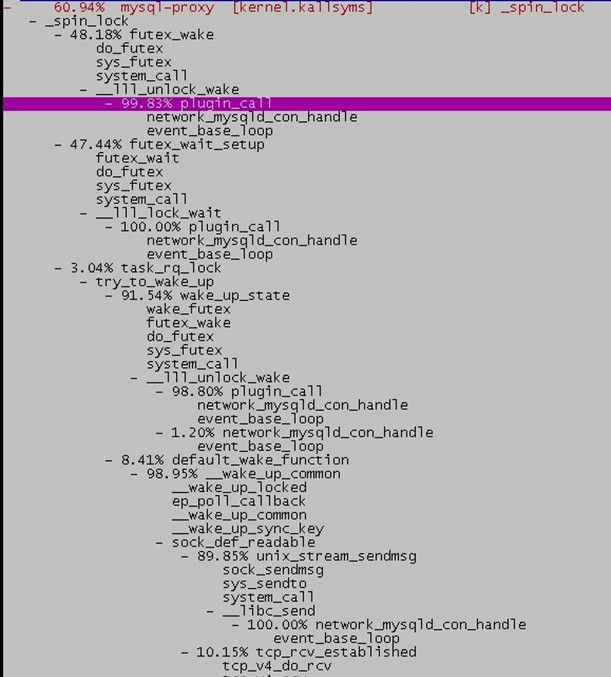
可以看到两个大头分别是调用futex_wake、futex_wait(http://hi.baidu.com/luxiaoyi/blog/item/3db9a302ba9a0f074bfb51e3.html);上面我们说到核心处理流程有4个过程,通过上面的perf report可以看到出现了前面两个过程(network_mysqld_con_handle,plugin_call),我们再回代码里:
| Plugin_call(…) {… LOCK_LUA(srv->priv->sc); <===> g_mutex_lock(sc->mutex); ret = (*func)(srv, con); UNLOCK_LUA(srv->priv->sc); } |
Perf果然是神器,之前一直在看网络模型,怀疑的重点也在惊群上,完全没注意到这个地方。至于原因也非常的简单,虽然说在第二个过程plugin_call还没开始调用lua相关函数,但是在第三个过程里就要使用到,所有的线程共享相同的一些全局luatable,可见这个锁粒度还是挺大的。
7. 验证
这里只是先说一下理论:一、防止惊群,将由一对socketpair改为多对即每个线程一对;二、现在的所有event是随机的由任何一个线程来处理,是否可以将一对event(client与backend server)固定为一个线程来处理,减少线程数据迁移?三、减少LOCK_LUA(srv->priv->sc)的锁粒度,或者去掉lua部分。
欢迎大牛指正。