数据库在磁盘上的存储布局HeapFile
----《大规模分布式存储系统:原理解析与架构实战》读书笔记
这篇依然是学习《大规模分布式存储系统:原理解析与架构实战》一书之外的一个话题。通过学习本书,知道了分布式键值系统,通常使用SSTable(一个无序的键值对集合容器)作为其磁盘上的布局。这不禁让人产生联想,传统数据库使用的是什么存储布局来存储数据呢?这就是今天要探讨的主题----HeapFile.
HeapFile是什么?
HeapFile是一种保存Page数据的数据结构,类似于链表,HeapFile也是一种无序容器。
HeapFile和SSTable其实都是具有特殊结构的文件。既然都是保存数据,为什么不直接使用文件呢?因为系统文件并不区分文件的内容。处理起来粒度大。而HeapFile和SSTable都能够提供记录级别的管理,从这一点上来说,二者的功能都是相同的,都是为系统提供更细粒度的存储管理。
基本上,Oracle,MySql,PostgreSql,SQLServer等传统数据库都使用HeapFile作为其存储布局管理。如同SSTable一样,HeapFile的结构实际很简单,但是你需要时刻知道,数据库中存储使用的是HeapFile。
我们都知道,数据库通常使用B+树作为索引,但是国内很少有人提到数据库使用的是HeapFile来管理记录的存储。国外的一些大学在“数据库系统实现”这门课上通常会让学生实现一个简单的数据库,因此有不少HeapFile的资料。
基于Page的HeapFile
采用链表形式的是HeapFile如下:
Heap file和链表结构类似的地方:
- 支持增加(append)功能
- 支持大规模顺序扫描
- 不支持随机访问
这种方式的HeapFile在寻找具有合适空间的半空Page时需要遍历多个页,I/O开销大。因此一般常用的是采用基于索引的HeaFile.在HeapFile中使用一部分空间来存储Page作为索引,并记录对应Page的剩余量。如下:
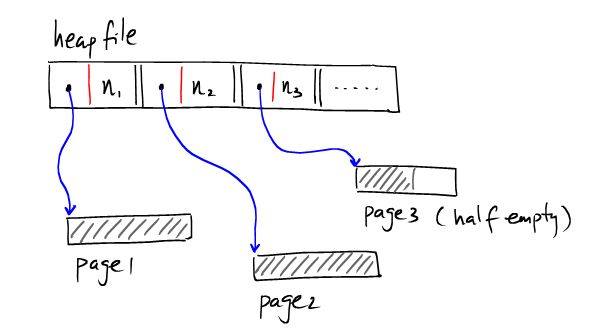
像上图那样,索引单独存在一个page上。数据记录存在其他page上,如果有多个索引的page,则可以表示为:
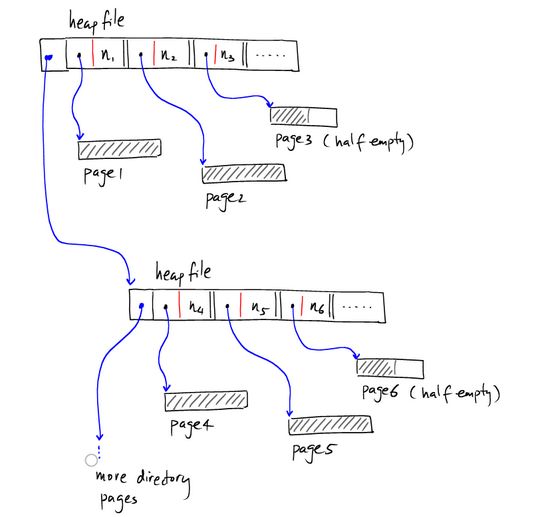
下面是Heap file自有的一些特性:
-
数据保存在二级存储体(disk)中:Heapfile主要被设计用来高效存储大数据量,数据量的大小只受存储体容量限制;
-
Heapfile可以跨越多个磁盘空间或机器:heapfile可以用大地址结构去标识多个磁盘,甚至于多个网络;
-
数据被组织成页;
-
页可以部分为空(并不要求每个page必须装满);
页面可以被分割在某个存储体的不同的物理区域,也可以分布在不同的存储体上,甚至是不同的网络节点中。我们可以简单假设每一个page都有一个唯一的地址标识符PageAddress,并且操作系统可以根据PageAddress为我们定位该Page。
一般情况下,使用page在其所在文件中的偏移量就可以表示了。
一种简单的布局实现方案
File的布局
在实现数据在文件中的布局的时候,为了实现更简单,我先做了一个简单的约定:一个文件表示一个关系。
这意味着一个关系的记录的条数受到文件系统的限制,如果是FAT32位系统,一个文件最大只能是4G,如果是普通的etx3,单个文件则是2TB。
同样为了实现简单,采用了数组的方式来组织页。
HeapFile的组织如下:

其中N和P为文件的最开始的16(或32)个字节。即N和P实际保存的是两个long型的值。N表示文件中页的数目,P表示每页的大小。则:
- 文件的总大小
FileSize = N * P + 2 * sizoeof(long). - 任意一页的页首地址
Page(k) = P * ( k - 1 ) +2 * sizeof(long) (k = 1,2,...,N)
Page的布局
页中可以包含多条记录。如果每天记录的长度都相同,则称为定长记录,如果每条记录的长度有不相同,则称为变长记录。定长记录可以采用数组的方式记录,但是变长记录不行。因此采用偏移量的方式来记录。page的布局如下:
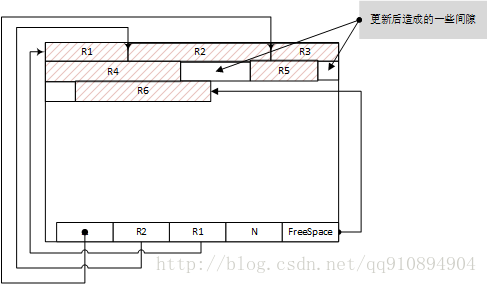
从页首开始一条条记录。页尾用一个int整形记录剩余空间的偏移量,再用一个Int整形该页已存储的记录数,每一条记录在页中的偏移量和是否被删除的标记。
其中,
- FreeSpace表示该页空间剩余量的首地址,也是最后一条记录的尾地址+1;
- N表示该页中已经存在的记录的条数,包括哪些被标记为删除的记录;
- 尾部的R1,R2,..表示其对应记录在页内的偏移地址,同时还会分出1个bit位标记这条记录是否被删除。如果要支持记录跨页存储的话,还需要再分出2bit来标记其是否是跨页的记录。
尾部的R1,R2等可以定义为如下结构体:
IndexRecord总共为32bit,其中29bit表示记录的页内偏移地址 ; 1bit表示记录是否被删除 ; 2bit表示是否跨页存储,0x00表示不跨页,0x01表示跨页,记录为开始的部分,0x10表示跨页,记录为中间部分,中间部分可以有多条,0x11表示跨页,记录为结尾的部分。struct IndexRecord { unsigned int pos:29; //记录在页内的偏移地址 unsigned int isdelete:1; //是否删除的标记 unsigned int spanned:2; //是否跨页存储 };
则: - 任意一条记录的IndexRecord首地址为
R(k) = P-(2+k)*sizeof(int); (k=1,2,..,N) - 计算一个页还能容纳的长度为
FreeLength = P-(2+N)*sizeof(int) - 判断一个页是否装满的条件为
FreeLength > 0
一个Page通常的大小为2K,4K,8K,16K等。
这里还要再提下空隙的问题,同时删除记录时直接采用标记法,但是当更新记录的时候,由于是变长记录。存在以下3种情况:
- 新记录和原记录一样长:原处更新记录即可
- 新纪录比原记录长:原记录标记删除,并新增一条记录,如果有索引,更新索引文件。
- 新纪录变原记录短:原处更新记录,无需更新索引文件,但是出现了记录的空隙。
当空间紧张时,可以尝试压缩页,剔除其中的空隙。
记录的布局
定长记录的布局可以比较简单,此处不提。本节主要讨论变长记录的布局,也叫记录的序列化。
一个常见的例子为给定表Person的定义,使name可以是不超过1024个字符。Schema如下:
CREATE TABLE Person ( name VARCHAR(1024) NOT NULL, age INTEGER NOT NULL, birthdate DATETIME )
上面表的记录是变长的原因为:
- name字段是一个变长的字符串;
- birthdate可以为NULL;
变长record的序列化的关键是字段边界的界定。一种比较流行的方法是在record的首部保存字段边界的offset。
Person的record的编排方式如下:
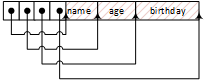
Note:我们在首部设置4个整型去存储三个字段的四个边界offset。
上面的编排方式很自然的提供一种NULL字段的编排方式--可以标识该字段的值为NULL,如下图:
第三个offset和第四个offset指向同一个位置,那么就表明第三个字段的大小是零,即是一个NULL值。
可以看到,使用偏移量无论是Page的布局,还是记录的序列化,都是非常方便的。
根据以上介绍, 可以有以下推断:
- 记录的总长度
RecordLength = R[k] k为字段数 - 每个字段的长度为
ColnumLength(k) = R[k] - R[k-1] , (k=1,2,3,...) - 判断一个字段是否为NULL
ColnumLength[k] = 0 ,(k=1,2,3,...)
最后我们在来看一遍关系Person的HeapFile文件的整体布局图

参考
这里有一篇关于HeapFile的翻译 关系型数据在磁盘上的存储布局
原文来自http://dblab.cs.toronto.edu/courses/443/tas/
欢迎光临我的网站----蝴蝶忽然的博客园----人既无名的专栏。
如果阅读本文过程中有任何问题,请联系作者,转载请注明出处!