《前言 :一个真实应用场景的大数据平台架构》
先前声明:
1、这个文章的架构和思路其实是源于14年,由于spark的快速发展,目前方案已经有些陈旧,但仍是一般公司常用的架构。
2、有哪些地方有问题,欢迎指教:)
3、将是一系列个人总结感觉的开篇,后续会从各个层次和常用项目上展开。
作为开篇,我们先简单看一个大数据的实际应用案例,整体的项目不复杂,只有离线计算,不过对于一般的公司已经足够了,本项目也是笔者曾经就职的一家公司的实际应用场景。数据驱动、小步快跑是很多创业型互联网公司的信条。大数据也是在近几年异军突起,很多人都开始尝试自己搭建Hadoop集群来体验大数据处理的魅力。但是由于Hadoop生态圈的复杂,初学者经常有一个这个要不要学、企业中不会用的困境;也有人会觉得使用大数据的解决方案成本太大。关于第一个疑问其实没有绝对的答案,公司中解决问题才是第一位的,用什么不重要。关于第二个问题跟随本文将会介绍,由一个非常简单的数据平台架构开始,即使在大数据之上也能小步快跑。

图1-1 一个实际应用场景的大数据平台架构
首先,不要觉得这个平台很复杂,觉得这么麻烦,还怎么叫小步快跑?其实数据平台的搭建,前期是痛苦的,但是完成时是美好的,因为搭建完成后,基本只需要做统计部分,这就是小步快跑的时候。对于数据平台的解读,我们可以从4个层次进行,分别是数据收集、数据存储、数据统计和数据挖掘,下面将分别展开做详细介绍。
一、数据收集:
第一个问题,收集什么日志,日志从哪里来?
网站都需要部署在Web服务器上,常见的Web服务器有Apache、Tomcat、IIS、Nginx,用户访问一个网站时所有的请求都经过Web服务器,也自然留下了访问的日志,这部分日志是非常重要的,通常我们称为原始日志。APP日志稍复杂一些,除了这种服务器日志,还需要单独记录一种行为日志,因为用户的有些行为服务器是不会记录的,比如受到缓存的影响第二次访问一个页面的时候不会重新发送请求、某些button的点击不会产生日志等。
第二个问题,用什么工具收集?
日志收集的方案很多(主流的是flume,scribe,kafka,logstash等),上图的平台架构中我们使用了Scribe,Scribe是facebook开源的一套日志收集系统,难编译是出名的,截止到2015年已经有两三年没有更新了,所以现在选择要慎重。使用中Scribe的优点大概有几点:
1、中央系统(一般是HDFS)出故障,或者写入出问题是,会把数据写到本地系统,等待中央系统恢复再重新上传。
2、日志块的状态保存在Mysql中,字段值表示状态,容易处理,比如第一种情况某块日志丢失,update一下状态就会继续流转
3、支持插件,上传过程中可以自己定义脚本进行ETL处理
除了服务器日志,还有一种数据需要上传到HDFS,以便数据统计时使用,比如用户表、订单表等,这部分数据大部分存储在关系型数据库中,比如Mysql、Oracle等。Sqoop和DataX(阿里开源)2个项目主要负责这部分功能的实现,我们的架构中选用了Sqoop。
一个小网站的部分访问日志(自己搭的一个wordpress站点):
208.80.194.120 - - [23/Oct/2015:07:20:21 +0800] "GET /files.php?fdx=H8TM6+bTqJlStGCTTnseXMrDwIWdQIqtB5msWJeEDTU HTTP/1.0" 500 737 "-" "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0)"
69.164.111.198 - - [23/Oct/2015:07:36:52 +0800] "GET /?page_id=113 HTTP/1.1" 500 737 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MDDC)"
69.164.111.198 - - [23/Oct/2015:07:36:55 +0800] "GET /?page_id=101 HTTP/1.1" 500 737 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MDDC)"
69.164.111.198 - - [23/Oct/2015:07:36:55 +0800] "GET /?page_id=102 HTTP/1.1" 500 737 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MDDC)"
192.92.196.188 - - [23/Oct/2015:07:47:34 +0800] "GET /?page_id=95 HTTP/1.1" 500 741 "-" "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0; Trident/5.0)"
二、数据存储:
目前几乎所有的大数据系统,都是以HDFS作为最底层的存储,包括Hive、HBase等都是以HDFS为基础。所以数据存储的核心是搭建一套稳定的Hadoop集群,Hadoop主要有2部分组成,即HDFS和MapReduce,线上的环境一定也必须是全分布式,搭建的过程可以参考官方文档。
HDFS是一个Master/Slave结构,NameNode作为Master主要记录整个HDFS系统的元数据,DataNode作为Slave主要是做实际的数据存储。HDFS对外提供了很多接口,包括Java、Command Line等方式,支持cat、ls、merge、get等基础操作。详细的介绍在后续章节中展开。
三、数据仓库&统计:
首先说下MapReduce,这是Hadoop的另一个核心,先将数据分割成小数据块(默认64M),再将数据处理过程分成Map和Reduce2个部分,Map阶段主要做分组,经过shuffle,同一组的数据进入同一个reduce进行处理。
其次讲痛点,工作中对于文件的处理其实很多,尤其是结构化文件,几乎能占到80%以上。这些结构的文件如果放到Mysql等数据库中,使用起来非常简单。但是当放到hdfs上的时候,尤其是逻辑很复杂又必须要写MR,就并不是很简单的事情了。
比如,当你想知道某一个文件有多少行,会怎么写?可能是hadoop fs -ls cat /filepath/filename | wc -l . 如果我还想排除第二列不是某个值的怎么办?可能是多一层awk的处理。那好,我还想按照第3列做group,还想和另一个文件做Join,然后做排序只取Top10,并且我本身的数据量增大到了100G? 这样的情况下,就只能写MR了,可以先看看MR的wordCount Demo。虽然我们最终都实现了上述的问题,但是你的脚本/程序会越来越复杂,越来越难读,越来越不好维护。
那么该寻医问药了,有简单的办法么?有!Hive!Hive是基于Hadoop的一个数据仓库程序,可以将结构化的数据文件映射为一张表,并提供类SQL的查询。那么,前面所有的需求就都转化成了SQL,上述场景的SQL都会写的吧,很简单,这不是忽悠人的。Hive还提供了UDF、UDAF、Transform等高阶语法来完成更复杂的功能。
Hive如此之屌,岂不是要爆了?非也,Hive也有软肋。当业务足够复杂,一条sql不足以满足需求的时候,通常我们会使用几十条或者几百条sql来处理,这个时候就引入了新的问题,性能&资源浪费。比如你需要使用同一个日志来计算2个指标,又不能写成一个sql,所以写成了2个,那每条sql都会加载一次这个日志,所以sql多了自然会有性能的问题。此时又一个选择出现了,闪闪发光的Pig,没错就是小猪Pig(还有很多方案,比如impala等可选,但是impala也是内存计算,在当时的环境下并不允许)!Pig是一个过程式的编程语言,提供一种Pig-Latin的语法,底层也是MR,Pig的强大之处要结合Streaming来体现,可以从后续的示例中看到。
上述的几种计算方案,就是我们的数据统计的常见选择。统计的结果需要报表展示,一般就会讲结果写入到Mysql中(有些场景下需要保存到HBase,简单架构出发+业务需求不强硬,所以本案中未使用),然后编写报表系统,直接从Mysql中读取数据,再做数据可视化即可。
四、数据分析&挖掘:
关于数据分析,是一个不好启齿的话题。2个点,1是因为我工作中接触到的分析,一般只是在数据异常、案例研究、某些feature的前期调研中,没有更深入的去做分析相关的事情;2是因为目前大部分公司对于大数据的使用还是在count阶段,即主要还是用来计算数据,count一下PV/UV/DAU等,对于数据的分析可能远不及传统企业。
数据挖掘是一个很宽泛的概念,本身也接触不多,一般都是我们做好平台和数据仓库,然后数据挖掘团队直接使用,所以这里没有能力多描述。
以上就是这个简单的大数据平台架构。当然这也是一套比较老的方案,因为架构设计数据是2014年,当时spark还并为兴起。按目前技术社区的活跃,此架构图会有多种改变的可能。
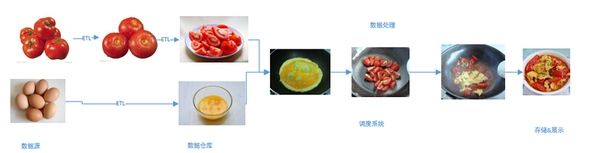
最后总结,先抛弃大数据是什么,怎么做这些疑问,回归到传统的数据处理过程上,然后把相应的方案替换成大数据生态中的方案,其实就很容易理解了。就像西红柿炒鸡蛋一样:
参考资料:
1、scribe官网:GitHub - facebookarchive/scribe: Scribe is a server for aggregating log data streamed in real time from a large number of servers.
2、scribe介绍:董的博客