反编译技术探究
摘要:编译原理简介,反编译原理简介,反编译的主要步骤,反编译的意义。
关键字:反编译,编译,中间代码,逆过程。
内容:
反编译,又称为逆向编译技术,是指将可执行文件变成高级语言源程序的过程。反编译技术依赖于编译技术,是编译过程的逆过程。欲理解反编译技术的原理所在,我们需要先系统的了解一下编译技术。
编译技术就是把高级语言变成可执行文件的过程。它的主要过程如下所示:
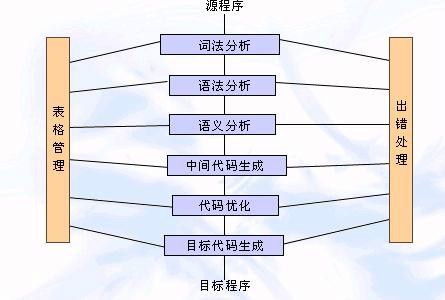
编译程序把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。词法分析的任务是对由字符组成的单词进行处理,从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串的中间程序。语法分析以单词符号作为输入,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等,最后看是否构成一个符合要求的程序。语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。中间代码是源程序的一种内部表示,或称中间语言。中间代码的作用是可使编译程序的结构在逻辑上更为简单明确,特别是可使目标代码的优化比较容易实现。代码优化是指对程序进行多种等价变换,使得从变换后的程序出发,能生成更有效的目标代码。目标代码生成是编译的最后一个阶段。目标代码生成器把语法分析后或优化后的中间代码变换成目标代码。表格管理和出错处理不在本篇文章的研究范围,故不再赘述。
对于反编译技术,我们上文提到,它是编译的逆过程。那是不是把上述的六个步骤倒置,就变成了反编译的过程了呢?显然是不对的。对于反编译过程,我们可以这么去理解:我们的源程序现在是二进制可执行文件或者汇编指令,我们的目标程序是某种特定的高级语言。那么现在这个过程该如何转化呢?这其中的中间代码的生成是否和编译过程中的一样呢?
基于上述原理及其疑问,我们很容易便采用这种思想:将特定的机器代码,即我们的“源程序”,先翻译为低级的中间代码,然后再根据特定的高级语言将中间代码翻译为高级程序。没错,反编译的主要思想确实就是那样:反编译器也有前端和后端。前端是一个机器依赖的模块,句法分析二进制程序、分析其指令的语义、并且生成该程序的低级中间表示法和每一子程序的控制流向图。通用的反编译机器是一个与语言和机器无关的模块,分析低级中间代码,将它转换成对任何高级语言都可接受的高级表示法,并且分析控制流向图的结构、把它们转换成用高级控制结构表现的图。最后,后端是一个目标语言依赖的模块,生成目标语言代码。反编译的过程中要使用一些工具:把二进制程序装入内存,对这一程序做句法分析或反汇编,以及反编译或者分析该程序来生成高级语言程序。这个过程借助编译器和库的签名来识别特定的编译器和库子程序。只要在二进制程序中识别出编译器签名,就不去反编译这些编译器启动代码(start-up)和库子程序:对于前者,从最后的目标程序去掉启动代码的那些例程,反编译器从主(main)程序入口点开始分析;对于后者,那些子程序用其库函数名代替。所以我们可以采用下图来表示反编译的过程:
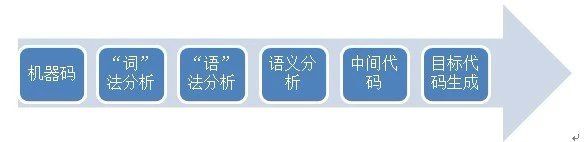
上图是我们对于反编译过程的初级构想(按照我们的理解),而实际的更为详细的过程则如下所示:

我们再对上述各个过程做一下更为详细的介绍:
1语法分析:语法分析程序或语法分析器把源程序的字节组织成源机器语言的语法短语(或语句)。这些短语用一个语法分析树表示。语法分析器的主要问题是确定哪些是数据和哪些是指令。
2语义分析:语义分析阶段检查源程序一组指令的语义含义,收集类型信息并且向整个子程序传递这个类型。对于任何一个编译器生成的二进制程序,只要程序能运行,其机器语言的语义一定是正确的。没见过哪一个二进制程序是因为编译器生成代码的错误而不能运行。因此,除非语法分析器对某一条指令做了不正确的分析或者把指令当作数据分析,否则,在源程序中是不会有语义错误的。
3中间代码生成:反编译器分析程序需要一个中间表示法来明晰地表现源程序。它必须容易从源程序中生成,而且还必须适合用来表示目标语言。
4控制流图生成:源程序中每一个子程序的控制流图也是为反编译器分析程序所必需的。这个表示法适合用来确定在程序中的高级控制结构。它也被用来清除掉由于机器语言的条件跳转有偏移量限制因而被编译器产生的中间跳转。
5数据流分析:数据流分析阶段试图改善中间代码,以便能够得到高级语言表达式。在这个分析期间,临时寄存器的使用和条件标志被清除掉,因为在高级语言里面没有这些概念。
6控制流分析器阶段试图将程序每一个子程序的控制流图组织成一个高级语言构造的类集(通有的)。这个类集必须包含大多数语言都有的控制指令。
7代码生成:反编译器的最后阶段是在控制流图和每一个子程序中间代码的基础上生成目标高级语言代码。为所有的局部栈、参数和寄存器变量标识符选择变量名称。也为在程序中出现的各个例程指定各自的子程序名称。
把二进制程序从各种各样的机器语言反编译为多种多样的高级语言,都要用到基本的反编译器技术。反编译器的结构是以编译器的结构为基础,采用与之相似的原理和技术来进行程序分析。第一代反编译器诞生于20世纪60年代早期,比它们的姐姐——编译器小十岁。对于第一代编译器,反编译大量地被用来翻译科学程序。在编写一个反编译器的时候,反编译器作者必须面对一些理论上和实际的问题。有些问题能够通过使用试探方法(启发式)解决,而另一些则不能被完全确定。由于这些限制,反编译器对某些源程序能够进行全自动的程序翻译,而对其它一些源程序则需要进行半自动的程序翻译。这与编译器对所有源程序都进行全自动程序翻译是不同的。正如李莉老师课堂中提到的关于常量的反编译,这些都体现了反编译的种种限制。
http://blog.csdn.net/yelbosh/article/details/7484031