赫夫曼编码---Huffman code(贪心算法)
算法描述:
赫夫曼编码是一种无损数据压缩算法。在计算机数据处理中,赫夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用赫夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
构建赫夫曼编码主要包括两个部分:
1)根据输入的字符串构建赫夫曼树。
2)遍历霍夫曼树并给每个字符分配编码。
赫夫曼树(Huffman Tree),又叫最优二叉树,指的是对于一组具有确定权值的叶子结点的具有最小带权路径长度的二叉树。
构建赫夫曼树的步骤:
算法:输入是没有相同元素的字符数组(长度n)以及字符出现的频率,输出是赫夫曼树。
即假设有n个字符,则构造出的赫夫曼树有n个叶子结点。n个字符的权值(频率)分别设为w1,w2,…,wn,则哈夫曼树的构造规则为:
(1)将w1,w2,…,wn看成是有n棵树的森林(每棵树仅有一个结点);
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的赫夫曼树。
算法实例:
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45第1步:将每个元素构造成一个节点,即只有一个元素的树。并构建一个最小堆,包含所有的节点,该算法用了最小堆来作为优先队列。
第2步:选取两个权值最小的节点,并添加一个权值为5+9=14的节点,作为他们的父节点。并更新最小堆,现在最小堆包含5个节点,其中4个树还是原来的节点,权值为5和9的节点合并为一个。
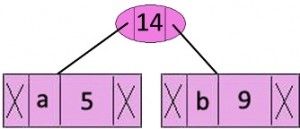
character Frequency
c 12
d 13
内部 节点 14
e 16
f 45重复上面的步骤,直到最小堆只有一个节点。
character Frequency
内部节点 100
算法实现:
#include <iostream>
#include<stdlib.h>
using namespace std;
#define MAX_TREE_HT 100
// 一个霍夫曼树节点
struct MinHeapNode
{
char data;// 输入的字符数组中的一个字符
int freq;// 字符出现的次数
struct MinHeapNode *left, *right;// Left and right child of this node
};
// 最小堆: 作为优先队列使用
struct MinHeap
{
int size;// 最小堆元素的个数
int capacity;//最大容量
struct MinHeapNode **array;//最小堆节点指针数组
};
//利用所给字母及其频率,分配一个新的最小堆节点
struct MinHeapNode* newNode(char data, int freq)
{
struct MinHeapNode* temp=(struct MinHeapNode*) malloc(sizeof(struct MinHeapNode));
temp->left = temp->right = NULL;
temp->data = data;
temp->freq = freq;
return temp;
};
// 创建一个容量为capacity 的最小堆
struct MinHeap* createMinHeap(int capacity)
{
struct MinHeap* minHeap=(struct MinHeap*) malloc(sizeof(struct MinHeap));
minHeap->size = 0;// current size is 0
minHeap->capacity = capacity;
minHeap->array = (struct MinHeapNode**)malloc(minHeap->capacity * sizeof(struct MinHeapNode*));
return minHeap;
};
// swap 两个堆节点
void swapMinHeapNode(struct MinHeapNode** a, struct MinHeapNode** b)
{
struct MinHeapNode* t = *a;
*a = *b;
*b = t;
}
// 更新最小堆.
void minHeapify(struct MinHeap* minHeap, int idx)
{
int smallest = idx;//根节点
int left = 2 * idx + 1;//左孩子节点
int right = 2 * idx + 2;//右孩子节点
//left < minHeap->size表示有左孩子!!!
if(left < minHeap->size && minHeap->array[left]->freq < minHeap->array[smallest]->freq)
{
smallest=left;
}
//right < minHeap->size表示有右孩子!!!
if(right < minHeap->size && minHeap->array[right]->freq < minHeap->array[smallest]->freq)
{
smallest=right;
}
if(smallest != idx)
{//不断将最小的往上移
swapMinHeapNode(&minHeap->array[smallest], &minHeap->array[idx]);
minHeapify(minHeap, smallest);//递归
}
}
//检测堆的大小是否为1
int isSizeOne(struct MinHeap* MinHeap)
{
return (MinHeap->size == 1);
}
//取得堆中最小的节点
struct MinHeapNode* extractMin(struct MinHeap* minHeap)
{
struct MinHeapNode* temp=minHeap->array[0];
minHeap->array[0]=minHeap->array[minHeap->size - 1];
--minHeap->size;
minHeapify(minHeap, 0);
return temp;
}
// 向最小堆中插入一个节点
void insertMinHeap(struct MinHeap* minHeap, struct MinHeapNode* minHeapNode)
{
++minHeap->size;
int i=minHeap->size - 1;
while(i && minHeapNode->freq < minHeap->array[(i-1)/2]->freq)
{
minHeap->array[i]=minHeap->array[(i-1)/2];
i=(i-1)/2;
}
minHeap->array[i]=minHeapNode;
}
//构建一个最小堆
void buildMinHeap(struct MinHeap* minHeap)
{
int n = minHeap->size - 1;
for(int i=(n-1)/2;i>=0;--i)
{
minHeapify(minHeap, i);
}
}
//打印数组
void printArr(int arr[], int n)
{
for(int i=0;i<n;i++)
{
cout<<arr[i];
}
cout<<endl;
}
// 检测是否是叶子节点
int isLeaf(struct MinHeapNode* root)
{//左孩子和右孩子均为空则是叶子节点
return !(root->left) && !(root->right);
}
// 创建一个容量为 size的最小堆,并插入 data[] 中的元素到最小堆
struct MinHeap* createAndBuildMinHeap(char data[], int freq[], int size)
{
struct MinHeap* minHeap=createMinHeap(size);
for(int i=0;i<size;i++)
{
minHeap->array[i]=newNode(data[i], freq[i]);
}
minHeap->size=size;
buildMinHeap(minHeap);
return minHeap;
}
// 构建霍夫曼树
struct MinHeapNode* buildHuffmanTree(char data[], int freq[], int size)
{
struct MinHeapNode *left, *right, *top;
// 第1步 : 创建最小堆.
struct MinHeap* minHeap=createAndBuildMinHeap(data, freq, size);
//迭代直到最小堆只有一个元素
while(!isSizeOne(minHeap))
{
// 第2步: 取到最小的两个元素
left = extractMin(minHeap);
right = extractMin(minHeap);
/*第3步: 根据两个最小的节点,来创建一个新的内部节点 '$' 只是对内部节点的一个特殊标记,没有使用*/
top=newNode('$', left->freq + right->freq);
top->left=left;
top->right=right;
insertMinHeap(minHeap, top);
}
// 第4步: 最后剩下的一个节点即为根节点
return extractMin(minHeap);
}
/*从霍夫曼树的根节点开始打印霍夫曼编码,利用arr[]来储存编码*/
void printCodes(struct MinHeapNode* root, int arr[], int top)
{
// Assign 0 to left edge and recur
if(root->left)
{
arr[top]=0;
printCodes(root->left, arr, top+1);
}
// Assign 1 to right edge and recur
if (root->right)
{
arr[top] = 1;
printCodes(root->right, arr, top + 1);
}
// 如果是叶子节点就打印
if (isLeaf(root))
{
cout<<root->data<<": ";
printArr(arr, top);
}
}
// 构建霍夫曼树,并通过遍历霍夫曼树打印霍夫曼编码
void HuffmanCodes(char data[], int freq[], int size)
{
// 构建霍夫曼树
struct MinHeapNode* root=buildHuffmanTree(data, freq, size);
// 打印霍夫曼编码利用构建好的霍夫曼树
int arr[MAX_TREE_HT], top=0;
printCodes(root, arr, top);
}
int main()
{
char arr[] = {'a', 'b', 'c', 'd', 'e', 'f'};
int freq[] = {5, 9, 12, 13, 16, 45};
int size = sizeof(arr)/sizeof(arr[0]);
HuffmanCodes(arr, freq, size);
return 0;
}执行结果:
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111时间复杂度
O(nlogn), 其中n是字符的数量。extractMin() 调用了 2*(n-1)次,extractMin()为log(n)的复杂度。
参考:http://www.geeksforgeeks.org/greedy-algorithms-set-3-huffman-coding/