第2课:通过案例对SparkStreaming透彻理解三板斧之二:解密SparkStreaming运行机制和架构
本期内容:
1 解密Spark Streaming运行机制
2 解密Spark Streaming架构
一、Spark Streaming工作原理:Spark Sreaming接收实时输入数据流并将它们按批次划分,然后交给Spark引擎处理生成按照批次划分的结果流。

二、DStream是逻辑级别的,而RDD是物理级别的。DStream是随着时间的流动内部将集合封装RDD。对DStream的操作,转过来对其内部的RDD操作。
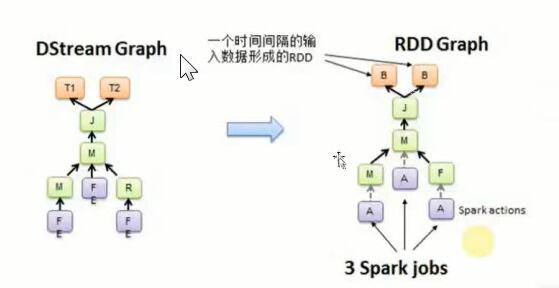
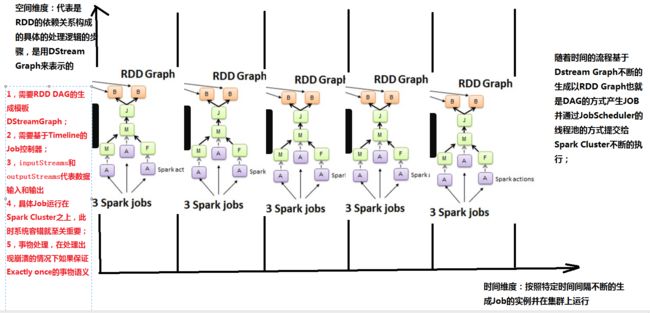
空间维度:代表是RDD的依赖关系构成的具体的处理逻辑步骤,是用DStreaming Graph来表示的;
时间维度:按照特定时间间隔不断地生成Job的实例并在集群上运行;
随着时间的流程基于DStreamGraph不断地生成以RDD Graph也就是DAG的方式产生JOB,
并通过JobScheduler的线程池的方式提交给Spark Cluster不断地执行;
(1)需要RDD DAG的生成模板 DStreamGraph;
(2)需要基于Timeline的Job控制器;
(3)inputStreams 和 outputStreams代表 数据输入和输出;
(4)具体Job运行在Spark Cluster 之上,此时系统容错就至关重要;
(5)事务处理,在处理出现崩溃的情况下 如何保证Exactly Once的事务语义
![]()