elk之高性能集群搭建
一.先上图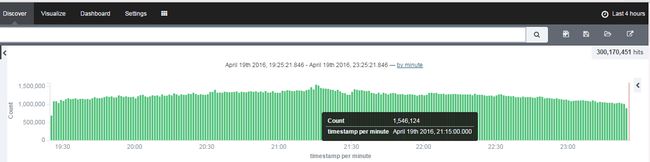
二.集群搭建的痛点
1.elasticsearch集群组建
(a) 首先es的配置类型分为三种,Master、Data、Client,官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
(b) 通常我们需要Master(调度)、Data(存储)、Client(查询),其中Master和Client都不作存储用(如果条件允许)
(c) Data节点又分为hot节点和cold节点,为什么要分,因为SSD磁盘的写入性能优于SATA盘,但是SSD的成本高,所以用SSD来作为热数据,也就是刚产生的数据接入点,使用SATA盘来存储历史数据
2.elasticsearch热数据和冷数据
(a) 假设有一个简单集群,1台SSD,1台SATA,logstash数据只配置了SSD的IP,实时数据确实是写入了SSD机器,但是实际上es会进行调度,也就是把数据从SSD偷偷搬到SATA机器上,这并不是我们想要的,我们希望数据只写入SSD机器,何时将数据从SSD搬到SATA机器,应该由我们主动控制
(b) 如果要实现冷热数据分离,首先需要如下配置es集群,就能保证数据只写入hot节点,官网:https://www.elastic.co/blog/hot-warm-architecture
#SSD机器的elasticsearch.yml关键配置
node.box_type: hot
#SATA机器的elasticsearch.yml关键配置
node.box_type: cold
#ES需要执行的命令,t1是自定义模板名
curl -XPUT "http://127.0.0.1:9200/_template/t1" -d'{"template" : "*", "settings": {"index.refresh_interval": "30s","index.routing.allocation.require.box_type": "hot"}}'
3.elasticsearch冷热数据管理
(a) 上面已经说明如何将数据写入到hot节点,还要关注如果定时将数据从hot节点搬到cold节点
(b) 直接上命令,根据需求微调即可,官网:https://www.elastic.co/blog/hot-warm-architecture
curl -XPUT "http://127.0.0.1:9200/*-$(date -d "3 day ago" "+%Y.%m.%d")*/_settings" -d'{"index.routing.allocation.require.box_type" : "cold"}'
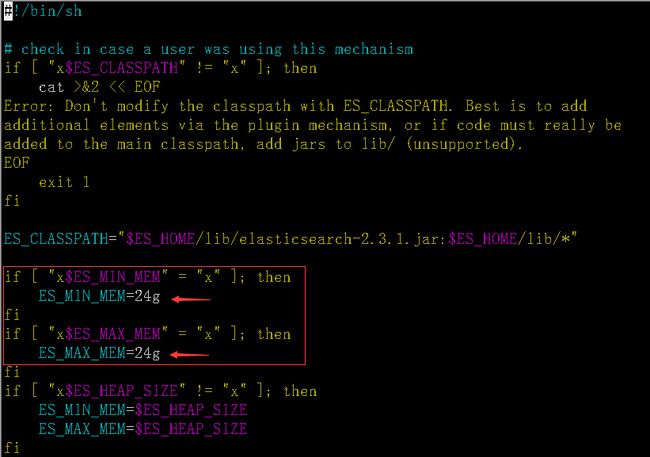
4.elasticsearch的JVM调优
(a) 默认的JVM内存上限是1GB,官网说明:https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html
(b) 可通过修改bin目录中的elasticsearch.in.sh来达到直接修改限制的目的
(c) 还是图:
5.elasticsearch的数据过期删除
(a) 官网提供了curator作为数据管理:https://www.elastic.co/guide/en/elasticsearch/client/curator/current/index.html
(b) 简单的数据过期删除例子,删除10天前的"udnginx-"开头的数据
curator --master-only delete indices --time-unit days --older-than 10 --timestring '%Y.%m.%d' --prefix 'udnginx-'
如果不许指定index,则不需要配置"--prefix"
curator --master-only delete indices --time-unit days --older-than 10 --timestring '%Y.%m.%d'
(c) "master-only"表示只会在master节点执行这个命令,不会出现冲突的情况,具体的参数说明可参考官网,比较简单
(d) 新版的curator同样可以实现hot数据迁移至cold节点
小结:
坑比较多,需要多踩踩
End;