ORB
众所周知,图像匹配中最关键的步骤是特征点的提取,因为特征点对的好坏直接影响着匹配的结果;熟悉CV的人也应该都知道特征点检测的算子有很多,本篇博客来学习下其中的一个,‘ORB算子’。
ORB,是基于oFAST和rBRIEF(rotated BRIEF)的一种算子,所以叫做Oriented FAST and Rotated BRIEF,简称ORB。ORB在很多时候可以替代SIFT和SURF,在你不想用后两者的时候,可以选择使用ORB。一般的,对于室外场景,ORB可能会优于SIFT和SURF,SIFT更适合于一些乱涂鸦的场景。
前面的文章中已经学习了FAST,并讨论了如何计算有方向的FAST,这篇文章我们来学习rBRIEF,在弄明白了这两者之后,ORB就自然浮出水面了。
1.rBRIEF
由于BRIEF中一般使用高斯平滑核进行模糊,所以最后生成的描述子跟均值和方差都有一定关系,可以通过下图来理解他们之间的关系:

其中,x轴表示到0.5的距离;
可以发现初始时,brief有一个0.5的均值和一个很大的方差(这是BRIEF的优越性之一),steered BRIEF也是如此,一般来说,较大的方差值往往是好事,因为它会产生不同的响应,可以让特征更加具有区分性,但是接着会看到,BRIEF和steered BRIEF随着均值的减小,方差会剧烈下降,损失的很严重。从数学上说,拥有较大的方差便意味着有较大的特征值,包含的信息量也越多,所以方差的剧烈下降也意味着BRIEF特征信息的丢失,我们再来看一幅图,就很清晰了:
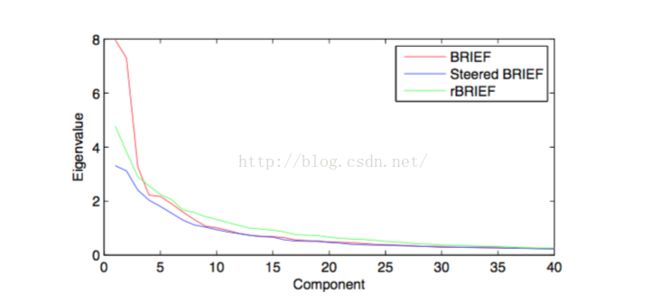
不难看出,特征值剧烈下降,信息大量丢失,基本上所有的信息都保留在前面的10个主成分中;
另一方面,如果binary tests之间都是独立的,相关性小,那么他们每个test都会对结果产生贡献,不会浪费空间和时间。那么面对此种情况,我们应该如何恢复那些丢失的信息呢?或者说如何恢复方差的损失并且降低binary tests之间的相关性呢?
方法如下:
-获取训练集:从PASCAL 2006数据集中提取出300k个特征点,作为训练集;
-列举出所有可能的binary test:设每一个patch的尺寸为MxM(通常取31x31),在每一个patch上取出NxN(通常取5x5)的子窗口,这样就会得到(M-N)*(M-N)个子窗口,于是有![]() 个binary tests;
个binary tests;
-对所有训练图像patch进行binary test;
-按照到均值0.5的距离从大到小将所有tests进行排序,生成有关tests的向量T;
-将第一个test存入结果向量R中,并将其从T中移除;
-从T中取出第二个test,将其与R中所有元素进行比较,计算两个向量之间的相关系数绝对值,如果大于一个阈值thres,就剔除之;反之,保留入R;
-重复上述步骤,直到R中有256个test;如果不足256个test,就要考虑增大阈值再进行操作;
很明显,这个算法是一个在0.5均值附近对所有不相关的tests进行贪婪搜索,这就是rBRIEF的主要思想;从上面的图可以看出,rBRIEF有效的改善了steered BRIEF中方差损失以及相关的问题,因为rBRIEF的特征值出现了缓慢的下降。
2.ORB
至此,应该知道了什么是ORB,它就是带有方向的fast和rBRIEF的结合,即检测出有方向的FAST keypoints,然后利用这些points提取出rBRIEF特征描述子;它可以被用来检测特征点,也可以用来计算特征点描述子,就像sift和surf一样。