CUDA 学习(二)
CUBLAS_Library.pdf 学习记录
Chapter 1. INTRODUCTION
从CUDA6.0之后,cuBLAS 库有两套API,第一个称为cuBLAS API,第二个是CUBLASXT API,这个文档讲的是cuBLAS API。
使用cuBLAS API ,应用一定要在GPU的内存空间中分配需要的矩阵和向量,并进行赋值,然后调用适用的cuBLAS函数,之后从GPU内存读取数据到host端。cuBLAS API 提供了读写GPU内存的帮助函数。
使用CUBLASXT API,应用需要把数据放在HOST,然后库会根据用户的要求将数据调度到GPUS的处理上。
1.1. Data layout
为了最大限制满足已有的Fortran 环境,cuBLAS 采用的是列优先的存储方式和基于1的检索。

但是,c和c++用的是行优先存储,因此用宏定义(maros)或者内联函数(inline)。Fortran移植到c语言里面,为了保持基于1检索避免在循环中过多的操作,这种情况,对于矩阵row i 和 column j 可以通过下面的宏实现
#define IDX2F(i,j,ld) ((((j)-1)*(ld))+((i)-1))这里,ld表示的是矩阵的主要尺寸(the leading dimension of the matrix,比如是列优先,ld表示行数)(翻译很奇怪)。反之用下面这个宏
#define IDX2C(i,j,ld) (((j)*(ld))+(i))1.2. New and Legacy cuBLAS API
从4.0版本之后,cuBLAS库提供传统的API的同时也提供新更新的API。这个地方将介绍新提供的API和它的优点以及传统的API的区别。
通过加下面的头文件使用新的API:
#include "cublas_v2.h"下面的特征是 传统API没有的:
1、cuBLAS的上下文句柄用函数初始化并且被传递到后续每一个使用的库函数。这使得用户在多主机线程和多GPU时对库的设置有更多的控制权。这使得cuBLAS API可以重入(reentrant)。
2、标量 α 和 β 可以通过在主机或者设备中声明然后进行传递,而不是在主机上被分配然后通过值进行传递。这个改变使得库函数可以用流进行执行同步,即使 α 和 β 是在前面的核产生的。
3、当一个库函数返回一个标量结果,它可以通过一个在主机或者设备声明的变量返回,而不是返回主机中的数值。这个使得库函数可以直接使用返回值。
4、错误状态 cublasStatus_t,更好调试。
5、the cublasAlloc() and cublasFree() functions have been deprecated. This change removes these unnecessary wrappers around cudaMalloc() and cudaFree(), respectively.
5、cublasSetKernelStream() 从命名为cublasSetStream()
传统的cuBLAS API 使用时候包含以下头文件:
#include "cublas.h"1.3. Example code
下面的两个使用cuBLAS 库的c程序,用了两种不同的索引风格:
(Example 1. “1-based indexing” and Example 2.”0-based Indexing”)
//Example 1. Application Using C and CUBLAS: 1-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#define M 6
#define N 5
#define IDX2F(i,j,ld) ((((j)-1)*(ld))+((i)-1))
static __inline__ void modify (cublasHandle_t handle, float *m, int ldm, int
n, int p, int q, float alpha, float beta){
cublasSscal (handle, n-p+1, &alpha, &m[IDX2F(p,q,ldm)], ldm);
cublasSscal (handle, ldm-p+1, &beta, &m[IDX2F(p,q,ldm)], 1);
}
int main (void){
cudaError_t cudaStat;
cublasStatus_t stat;
cublasHandle_t handle;
int i, j;
float* devPtrA;
float* a = 0;
a = (float *)malloc (M * N * sizeof (*a));
if (!a) {
printf ("host memory allocation failed");
return EXIT_FAILURE;
}
for (j = 1; j <= N; j++) {
for (i = 1; i <= M; i++) {
a[IDX2F(i,j,M)] = (float)((i-1) * M + j);
}
}
cudaStat = cudaMalloc ((void**)&devPtrA, M*N*sizeof(*a));
if (cudaStat != cudaSuccess) {
printf ("device memory allocation failed");
return EXIT_FAILURE;
}
stat = cublasCreate(&handle);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("CUBLAS initialization failed\n");
return EXIT_FAILURE;
}
stat = cublasSetMatrix (M, N, sizeof(*a), a, M, devPtrA, M);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("data download failed");
cudaFree (devPtrA);
cublasDestroy(handle);
return EXIT_FAILURE;
}
modify (handle, devPtrA, M, N, 2, 3, 16.0f, 12.0f);
stat = cublasGetMatrix (M, N, sizeof(*a), devPtrA, M, a, M);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("data upload failed");
cudaFree (devPtrA);
cublasDestroy(handle);
return EXIT_FAILURE;
}
cudaFree (devPtrA);
cublasDestroy(handle);
for (j = 1; j <= N; j++) {
for (i = 1; i <= M; i++) {
printf ("%7.0f", a[IDX2F(i,j,M)]);
}
printf ("\n");
}
free(a);
return EXIT_SUCCESS;
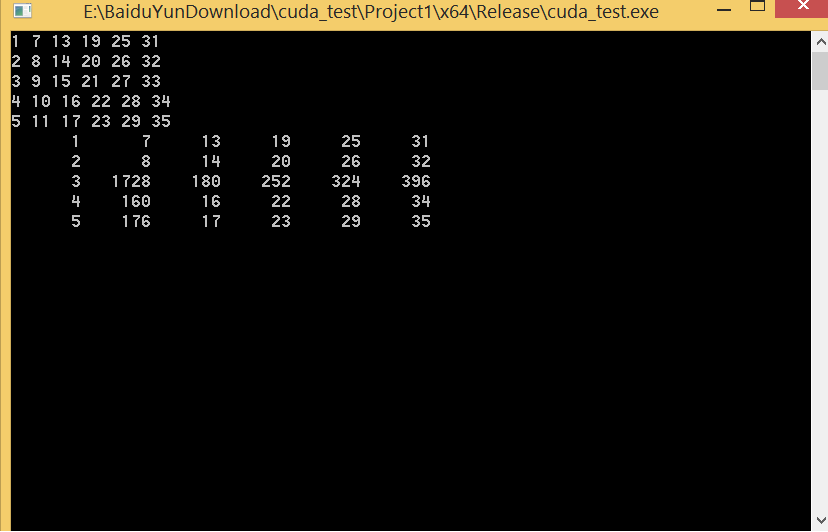
}运行结果
Chapter 2. USING THE CUBLAS API
2.1. General description
2.1.1. Error status
所有的cuBLAS库函数都返回the error status cublasStatus_t
2.1.2. cuBLAS context
应用必须通过调用cublasCreate()函数来初始化cuBLAS 库的上下文句柄。通过cublasDestory()来释放。应用程序可以使用cudaSetDevice()结合初始化的独特上下文句柄,应用程序根据不同的句柄将数据传递到不同的设备进行计算。如果在一个主机里面使用不同的设置,在使用新设备前调用cudaSetDevice(),然后cublasCreate()根据当前的设置设备来初始化不同的上下文句柄。
2.1.3. Thread Safety
库的线程安全即使它被同一个句柄的多个主机进程调用。当多个线程使用同一个句柄,需要注意,当 句柄被改变时候,这个改变会影响到后续使用它的线程。因此不建议多个进程同时时候同一个CUBLAS 句柄。
2.1.4. Results reproducibility
By design, all CUBLAS API routines from a given toolkit version, generate the same bitwise results at every run when executed on GPUs with the same architecture and the same number of SMs. However, bit-wise reproducibility is not guaranteed across toolkit version because the implementation might differ due to some implementation changes.
For some routines such as cublassymv and cublashemv, an alternate significantly faster routines can be chosen using the routine cublasSetAtomicsMode(). In that case, the results are not guaranteed to be bit-wise reproducible because atomics are used for the computation.
2.1.5.Scalar Parameters
有两种类别的函数使用标量参数:
1、将在主机或者设备内定义的 α 或者 β 作为变化因子的函数,如gemm
2、返回在设备或者主机上的标量的函数,如 amax(), amin(), asum(), rotg(), rotmg(), rotmg(), dot() 和 nrm2()。
对于第一种类别,当指针模式设置为”CUBLAS_POINTER_MODE_HOST”,这种情况标量 α 或者 β 可以在栈或者分配在堆中。Underneath the CUDA kernels related tothat functions will be launched with the value of alpha and/or beta. 因此如果他们在堆中被分配,他们可以在调用放回后被释放即使内核是异步的。当指针的模式设置为“CUBLAS_POINTER_MODE_DEVICE” α 或者 β 应该在设备上可以被访问并且不能被修改直到核调用完成。注意由于cudaFree隐式调用cudaDeviceSynchronize(),cudaFree() can still be called on alpha and/or beta just after the call but it would defeat the purpose of using this pointer mode in that case.
第二种模式:指针模式为”CUBLAS_POINTER_MODE_HOST”,GPU计算完成后结果会赋值回Host。指针模式设置为 “CUBLAS_POINTER_MODE_DEVICE“这函数立即返回。这种情况,和矩阵或者向量结果相似,标量结果只有等例程在GPU上完成。为了从主机里面读结果,这个就要求正确的同步。
在任何一种情况,指针模式为“CUBLAS_POINTER_MODE_DEVICE“库函数允许在完全异步时执行,即使alpha 和 beta是前一个核产生。比如,当用cuBLAS库循环的方法解决线性系统和特征值的问题是会出现。