java 堆排序 时间复杂度 空间复杂度 稳定性
1、基本思想:
定义
n个关键字序列Kl,K2,…,Kn称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):
(1)ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n),当然,这是小根堆,大根堆则换成>=号。//k(i)相当于 二叉树的非 叶子结点,K(2i)则是左子节点,k(2i+1)是右子节点
若将此序列所存储的向量R[1..n]看做是一棵
完全二叉树的 存储结构,则堆实质上是满足如下性质的完全二叉树:
 树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
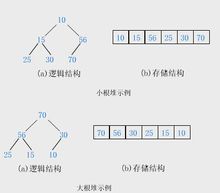
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的 完全二叉树分别如小根堆示例和大根堆示例所示。
大根堆和小根堆:根结点(亦称为堆顶)的 关键字是堆里所有结点关键字中最小者的堆称为小根堆,又称 最小堆。根结点(亦称为堆顶)的 关键字是堆里所有结点关键字中最大者,称为大根堆,又称最大堆。注意: ①堆中任一子树亦是堆。②以上讨论的堆实际上是 二叉堆
(Binary Heap),类似地可定义k叉堆。
高度
堆可以被看成是一棵树,结点在堆中的高度可以被定义为从本结点到叶子结点的最长简单下降路径上边的数目;定义堆的高度为树根的高度。我们将看到,
堆结构上的一些基本操作的运行时间至多是与树的高度成正比,为O(lgn)
。
算法
堆排序利用了大根堆(或小根堆)堆顶记录的 关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
①
先将初始文件R[1..n]建成一个大根堆
,此堆为初始的无序区
② 再
将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换
,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
③
由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆
。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止
。
(2)大根堆排序算法的基本操作:
① 初始化操作:将R[1..n]构造为初始堆;
② 每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意
①只需做n-1趟排序,选出较大的n-1个 关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接 选择排序
相反:在任何时刻堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止
特点
堆排序(HeapSort)是一树形选择排序
。堆排序的特点是:在排序过程中,
将R[l..n]看成是一棵完全二叉树的顺序存储结构
,利用完全二叉树中双亲结点和孩子结点之间的内在关系(参见二叉树的顺序存储结构),
在当前无序区中选择关键字最大(或最小)的记录
区别
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。
事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
2、java实现:
package com.ynu.www.tool;
public class HeapSort {
private static int[] sort = new int[] { 1, 0, 10, 20, 3, 5, 6, 4, 9, 8, 12,
17, 34, 11 };
public static void main(String[] args) {
buildMaxHeapify(sort);//创建初始最大堆 需要从第一个非叶子节点开始调用<span style="font-family: Arial, Helvetica, sans-serif;">maxHeapify()方法</span><span style="font-family: Arial, Helvetica, sans-serif;"> </span>
heapSort(sort);//堆排序,将根节点跟最后一个叶子节点交换,然后对剩下的前n-1个节点调用maxHeapify()方法<span style="font-family: Arial, Helvetica, sans-serif;"> </span>
print(sort);//打印树结构,也比较特别,用到log2,求层次
}
private static void buildMaxHeapify(int[] data) {
// 从最后一个的父节点开始
int startIndex = getParentIndex(data.length - 1);
// 从尾端开始创建最大堆,每次都是正确的堆
for (int i = startIndex; i >= 0; i--) {
maxHeapify(data, data.length, i);
}
}
/**
*创建最大堆
*
*@param data 进行创建最大堆的数组
*@param heapSize需要创建最大堆的大小,为了保证验证左孩子,右孩子跟父节点大小比较的时候,保证不超过data的大小。
*@param index 当前需要创建最大堆的位置
*/
private static void maxHeapify(int[] data, int heapSize, int index) {
// 当前点与左右子节点比较
int left = getChildLeftIndex(index);
int right = getChildRightIndex(index);
int largest = index;
if (left < heapSize && data[index] < data[left]) {
largest = left;
}
if (right < heapSize && data[largest] < data[right]) {
largest = right;
}
// 得到最大值后可能需要交换,如果交换了,其子节点可能就不是最大堆了,需要重新调整
if (largest != index) {
int temp = data[index];
data[index] = data[largest];
data[largest] = temp;
maxHeapify(data, heapSize, largest);
}
}
/**
*排序,最大值放在末尾,data虽然是最大堆,在排序后就成了递增的
*
* @paramdata
*/
private static void heapSort(int[] data) {
// 末尾与头交换,交换后调整最大堆
for (int i = data.length - 1; i > 0; i--) {
int temp = data[0];
data[0] = data[i];
data[i] = temp;
maxHeapify(data, i, 0);
}
}
/**
*父节点位置
*
*@paramcurrent
*@return
*/
private static int getParentIndex(int current) {
return (current - 1) >> 1;
}
/**
*左子节点position注意括号,加法优先级更高
*
* @paramcurrent
*@return
*/
private static int getChildLeftIndex(int current) {
return (current << 1) + 1;
}
/**
*右子节点position
*
*@paramcurrent
*@return
*/
private static int getChildRightIndex(int current) {
return (current << 1) + 2;
}
private static void print(int[] data) {
int pre = -2;
for (int i = 0; i < data.length; i++) {
if (pre < (int) getLog(i + 1)) {
pre = (int) getLog(i + 1);
System.out.println();
}
System.out.print(data[i] + "|");
}
}
/**
*以2为底的对数
*
*@paramparam
*@return
*/
private static double getLog(double param) {
return Math.log(param) / Math.log(2);
}
}
<p style="margin-top: 10px; margin-bottom: 10px; padding-top: 0px; padding-bottom: 0px; color: rgb(51, 51, 51); background-color: rgb(248, 248, 248); text-indent: 28px; font-family: 宋体; font-size: 14px; line-height: 28px;"> </p>
3、算法分析:
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。
堆排序的最坏时间复杂度为O(nlgn)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。
4、补充:
>表示大于,如:if(a>b)...结果是boolean类型
>>表示右移,如:int i=15; i>>2的结果是3,移出的部分将被抛弃。
转为二进制的形式可能更好理解,0000 1111(15)右移2位的结果是0000 0011(3),0001 1010(18)右移3位的结果是0000 0011(3)。
>>>叫什么我也不是很清楚,但是我知道它表示的含义:
j>>>i 与 j/(int)(Math.pow(2,i))的结果相同,其中i和j是整形。