C语言入门基础篇,内存与变量关系
变量与内存
在前面一节中简单介绍了变量的使用,当我们定义一个变量的时候,系统就会为变量分配一块存储空间。而变量的数值在内存中是以二进制的形式存储的,这讲来深入研究变量在内存中的一些存储细节。
一、字节和地址
为了更好地理解变量在内存中的存储细节,先来认识一下内存中的“字节”和“地址”。
1.计算机中的内存是以字节为单位的存储空间。内存的每一个字节都有一个唯一的编号,这个编号就称为地址。就好像酒店是以房间为单位的,每个房间都有一个唯一的房号,我们根据房号就能找到对应的房间。
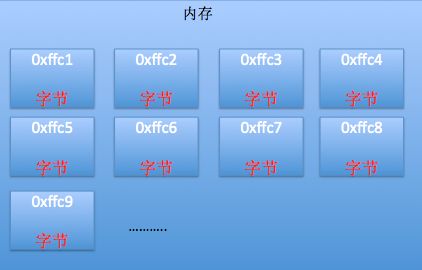
里面的每个小框框就代表着内存中的一个字节,白色数字就是每个字节的地址(这里采取十六进制来显示,地址值是随便写的,仅作为参考,真实情况中的地址值不一定是这个),可以发现,内存中相邻字节的地址是连续的。
2.大家都知道,一个字节有8位,所能表示的数据范围是非常有限的,因此,范围较大的数据就要占用多个字节,也就是说,不同类型的数据所占用的字节数是不一样的。
二、变量的存储
1.变量类型的作用
跟其他编程语言一样,C语言中用变量来存储计算过程使用的值,任何变量都必须先定义类型再使用。为什么一定要先定义呢?因为变量的类型决定了变量占用的存储空间,所以定义变量类型,就是为了给该变量分配适当的存储空间,以便存放数据。比如char类型,它是用来存储一个字符的,一个字符的话只需要1个字节的存储空间, 因此系统就只会给char类型变量分配1个字节,没必要分配2个字节、3个字节乃至更多的存储空间。
2.变量占用多少存储空间
1> 一个变量所占用的存储空间,不仅跟变量类型有关,而且还跟编译器环境有关系。同一种类型的变量,在不同编译器环境下所占用的存储空间又是不一样的。我们都知道操作系统是有不同位数的,比如Win7有分32位、64位,编译器也是一样的,也有不同位数:16位、32位、64位(Mac系统自带的GCC编译器是64bit的)。由于我们是Mac系统下开发,就以64位编译器为标准。
2> 下面的表格描述了在64位编译器环境下,基本数据类型所占用的存储空间,了解这些细节,对以后学习指针和数组时是很有帮助的。
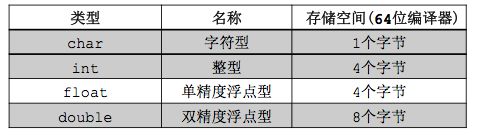
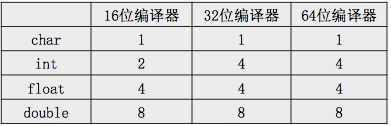
3> 下面的表格描述了在不同编译器环境下的存储空间占用情况
3.变量示例
当定义一个变量时,系统就会为这个变量分配一定的存储空间。
1 int main() 2 { 3 char a = 'A'; 4 5 int b = 10; 6 7 return 0; 8 }
1> 在64bit编译器环境下,系统为变量a、b分别分配1个字节、4个字节的存储单元。也就是说:
- 变量b中的10是用4个字节来存储的,4个字节共32位,因此变量b在内存中的存储形式应该是0000 0000 0000 0000 0000 0000 0000 1010。
- 变量a中的'A'是用1个字节来存储的,1个字节共8位,变量a在内存中的存储形式是0100 0001,至于为什么'A'的二进制是这样呢,后面再讨论。
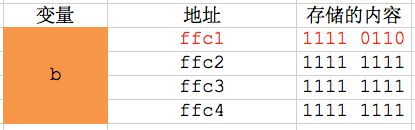
2> 上述变量a、b在内存中的存储情况大致如下表所示:
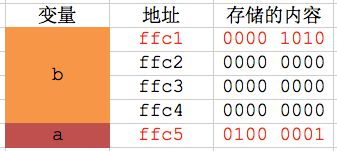
(注:"存储的内容"那一列的一个小格子就代表一个字节,"地址"那一列是指每个字节的地址)
- 从图中可以看出,变量b占用了内存地址从ffc1~ffc4的4个字节,变量a占用了内存地址为ffc5的1个字节。每个字节都有自己的地址,其实变量也有地址。变量存储单元的第一个字节的地址就是该变量的地址。变量a的地址是ffc5,变量b的地址是ffc1。
- 内存寻址是从大到小的,也就是说做什么事都会先从内存地址较大的字节开始,因此系统会优先分配地址值较大的字节给变量。由于是先定义变量a、后定义变量b,因此你会看到变量a的地址ffc5比变量b的地址ffc1大。
- 注意看表格中变量b存储的内容,变量b的二进制形式是:0000 0000 0000 0000 0000 0000 0000 1010。由于内存寻址是从大到小的,所以是从内存地址最大的字节开始存储数据,存放顺序是ffc4 -> ffc3 -> ffc2 -> ffc1,所以把前面的0000 0000都放在ffc2~ffc4中,最后面的八位0000 1010放在ffc1中。
4.查看变量的内存地址
在调试过程中,我们经常会采取打印的方式查看变量的地址
1 #include <stdio.h> 2 3 int main() 4 { 5 int a = 10; 6 printf("变量a的地址是:%p", &a); 7 return 0; 8 }
第6行中的&是一个地址运算符,&a表示取得变量a的地址。格式符%p是专门用来输出地址的。输出结果是:
变量a的地址是:0x7fff5fbff8f8
这个0x7fff5fbff8f8就是变量a的内存地址
三、负数的二进制形式
1 int main() 2 { 3 int b = -10; 4 return 0; 5 }
在第3行定义了一个整型变量,它的值是-10。-10的二进制形式是怎样的呢?一个负数的二进制形式,其实就是对它的正数的二进制形式进行取反后再+1。(取反的意思就是0变1、1变0)
1> 先算出10的二进制形式:0000 0000 0000 0000 0000 0000 0000 1010
2> 对10的二进制进行取反:1111 1111 1111 1111 1111 1111 1111 0101
3> 对取反后的结果+1:1111 1111 1111 1111 1111 1111 1111 0110
因此,整数-10在内存中的二进制形式是:1111 1111 1111 1111 1111 1111 1111 0110。这里还能得出一个结论:负数的二进制形式的最高位一定是1。
四、变量的作用域
1.作用域简介
变量的作用域就是指变量的作用范围。先来看看下面的程序:
1 int main() 2 { 3 int a = 7; 4 5 return 0; 6 }
- 在第3行定义了一个变量a,当执行到这行代码时,系统就会为变量a分配存储空间
- 当main函数执行完毕,也就是执行完第5行代码了,变量a所占用的内存就会被系统自动回收
- 因此,变量a的作用范围是从定义它的那行开始,一直到它所在的大括号{}结束,也就是第3~6行,一旦离开这个范围,变量a就失效了
2.代码块
1> 代码块其实就是用大括号{}括住的一块代码。
1 int main() 2 { 3 { 4 int a = 10; 5 6 printf("a=%d", a); 7 } 8 9 a = 9; 10 11 return 0; 12 }
- 注意第3~7行的大括号,这就是一个代码块
- 当执行到第4行时,系统会分配内存给变量a
- 当代码块执行完毕,也就是执行完第6行代码后,变量a所占用的内存就会被系统回收
- 因此,变量a的作用范围是从定义它的那行开始,一直到它所在的大括号{}结束,也就是第4~7行,离开这个范围,变量a就失效了
- 所以,上面的程序是编译失败的,第9行代码是错误的,变量a在第7行的时候已经失效了,不可能在第9行使用
2> 如果是下面这种情况
1 int main() 2 { 3 int a = 9; 4 5 { 6 int a = 10; 7 8 printf("a=%d", a); 9 } 10 11 return 0; 12 }
- 注意第3、6行,各自定义了一个变量a,这种情况是没问题的。C语言规定:在不同作用域中允许有同名变量,系统会为它们分配不同的存储空间。
- 在第3行定义的变量a的作用域是:第3~12行;在第6行定义的变量a的作用域是:第6~9行。
- 最后注意第8行:尝试输出变量a的值。那这里输出的是哪一个变量a呢?先看输出结果:
a=10
这里采取的是“就近原则”,也就是第8行访问的是在第6行定义的变量a,并不是在第3行的变量a。
五、变量的初始化
变量在没有进行初始化之前,不要拿来使用,因为它里面存储的是一些垃圾数据
1 #include <stdio.h> 2 3 int main() 4 { 5 int c; 6 7 printf("%d", c); 8 return 0; 9 }
注意第5行的变量c,只是定义了变量,并没有给它赋初值。输出结果:
1606422622
可以发现,变量c里面存储的是一些乱七八糟的数据