聊聊计算机中的编码(Unicode,GBK,ASCII,utf8,utf16,ISO8859-1等)以及乱码问题的解决办法
作为一个程序员,一个中国的程序员,想来“乱码”问题基本上都遇到过,也为之头疼过。出现乱码问题的根本原因是编码与解码使用了不同而且不兼容的“标准”,在国内一般出现在中文的编解码过程中。
我们平时常见的编码有Unicode,GBK,ASCII,utf8,utf16,ISO8859-1等,弄清这些编码之间的关系,就不难理解“乱码”出现的原因以及解决办法。
所谓字符集编码其实就是将字符(包括英文字符、特殊符号,控制字符,数字,汉子等)与计算机中的一个数字(二进制存储)一一对应起来,用这个数字来表示该字符,存储该字符的时候就存储这个数字。比如a对应数字97。因此,理解编码很简单,所有的编码都是字符与数字的一种对应关系。
ASCII编码
计算机最早出现在美国,因此老美搞编码只需要对26个英文字符大小写以及常用的字符对应数字就可以了,这种对应就是ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)码。标准ASCII 码使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。这样可以表示27=128个字符。标准ASCII码的最高位恒为0,没有使用。
用java输出英文字符的ASCII码如下:
public class TestCode {
public static void main(String[] args) throws Exception {
int code='a';
System.out.println(code);
}
}输出:
97iso8859-1
随着计算机的推广,世界各地都开始使用计算机。各国不同语言对字符编码提出了新的需求,原ASCII的128个字符已经显得严重不足。那怎么办呢,ASCII码不是只用了一个字节中的7位吗,还剩余1位呢?那就赶紧用上吧!于是人们把编码扩展到了8位,即256个字符的编码,这就是ISO8859-1。这种扩展保持了与ASCII的兼容性,即最高位为0的ISO8859-1编码等同于ASCII码。
用java随便输出一个iso8859-1字符如下:
public class TestCode {
public static void main(String[] args) throws Exception {
char code=0xA7;
System.out.println(code);
}
}输出:
§GBK码
等到计算机进入中国,人们又头疼了。常用汉字就有6000多个,像ASCII那样用一个字节来编码撑爆了也不够啊。但是这难不倒智慧的中国人们,我们直接定下标准:小于127的字符与原意义相同(保持与ASCII的兼容性),但是两个大于127的字符连在一起时,就表示一个汉字。这样我们就凑出来了7000多个简体汉字的编码了。此外,这些编码还对ASCII码中已有的标点、数字、字母都用两字节重新编码,这就是通常说的“全角”字符。这种编码就是GB2312。
但是中国的汉字实在太多了,GB2312还是不够用,一些不常用的汉字还是显示不出来啊。于是我们不得不继续挖掘GB2312的潜能,干脆只要求第一个字节大于127而不管后一个字节的大小了。这种扩展之后的编码方案称为GBK。
下图为中文“你好”二字的GB2312编码输出(GBK输出相同):
public class TestCode {
public static void main(String[] args) throws Exception {
String s = "你好";
byte[] code = s.getBytes("gb2312");
for (byte b : code) {
System.out.print(Integer.toHexString(b & 0xFF) + " ");
}
}
}输出:
c4 e3 ba c3Unicode码
中国造出了GBK编码,其他国家呢,他们也要显示自己的文字啊。于是各个国家都搞出了一套自己的编码标准,结果相互之间谁也不懂谁的编码,互不兼容。这样不行啊,于是乎ISO(国际标谁化组织)不得不站出来说话了:“你们都不要各自搞编码了,我给你们搞一套统一的!”。于是ISO搞了一个全球统一的字符集编码方案,叫UCS(Universal Character Set),俗称Unicode。
Unicode标准最早是1991年发布了,目前实际应用的版本是UCS-2,即使用两个字节编码字符。这样理论上一共可以编码216=65536个字符,基本能够满足各种语言的需求。
UTF8、UTF16码
其实Unicode码已经完美解决编码国际化问题了,那utf8和utf16又是神马东东,用来解决什么问题呢?
前面已经说过,编码只是字符与数字的一种对应关系,这完全是一个数学问题,跟计算机和存储以及网络都没有半毛钱关系。Unicode码就是这样一种对应关系,它并没有涉及到如何存储以及传输的问题。看下面一个例子:
假如某个字符的Unicode编码为0xabcd,也就是两个字节。那存储的时候是哪个字节在前哪个在后呢?网络传输的时候又是先传输哪个字节呢?计算机从文件中读取到0xabcd又是怎么知道这是两个ASCII码还是一个Unicode码呢?
因此需要一种统一的存储和传输格式来标示Unicode码。这种统一的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。编码utf8和utf16就是因此而产生的。
其中utf16与16位的Unicode码完全对应。在Mac和普通PC上,对于字节顺序的理解是不一致的。比如MAC是从低字节开始读取的,因此前文的0xabcd如果按照所见的顺序存储,则会被MAC认为是0xcdab,而windows会从高字节开始读取,得到的是0xabcd,这样根据Unicode码表对应出来的字符就不一致了。
因此,utf16使用了大端序(Big-Endian,简写为UTF-16 BE)、小端序(Little-Endian,简写为UTF-16 LE)以及BOM(byte order mark)的概念。如果在windows上用记事本写上一些中文字符并以Unicode码格式保存,然后使用十六进制查看器打开即可以看到文件的前两个字节为0xfffe(0xfffe在Unicode码中不对应字符),用来标记使用小端序存储(windows平台默认使用小端序),
下图为中文“你好”二字在windows7上的十六进制数据。
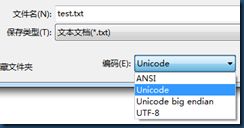
如果用java程序输出“你好”二字的utf16码,则如下:
public class TestCode {
public static void main(String[] args) throws Exception {
String s = "你好";
byte[] code = s.getBytes("utf16");
for (byte b : code) {
System.out.print(Integer.toHexString(b & 0xFF) + " ");
}
}
}输出:
fe ff 4f 60 59 7d可以看到java默认输出的是大端序的utf16编码(BOM为0xfeff)。
由于Unicode统一采用16位二进制编码字符,试想一篇英文文章如果用UTF16来存储的话整整比用ASCII存储多占用一倍的存储空间(英文字符的Unicode码高字节是0),这样白白的浪费让人于心不忍啊。于是utf8诞生了。utf8是一种变长编码,根据不同的Unicode码值采用不同的存储长度。那么问题又来了,既然是变长的系统怎么知道几个字节表示一个字符编码呢?对于这类问题计算机中通用的处理方式就是使用标志位,就像ip段的划分一样。具体如下:
0xxxxxxx,如果是这样的01串,也就是以0开头后面是啥就不用管了XX代表任意bit.就表示把一个字节做为一个单元.就跟ASCII完全一样.
110xxxxx 10xxxxxx.如果是这样的格式,则把两个字节当一个单元
1110xxxx 10xxxxxx 10xxxxxx 如果是这种格式则是三个字节当一个单元.
用java输出“你好”的utf8编码如下:
public class TestCode {
public static void main(String[] args) throws Exception {
String s = "你好";
byte[] code = s.getBytes("utf8");
for (byte b : code) {
System.out.print(Integer.toHexString(b & 0xFF) + " ");
}
}
}输出:
e4 bd a0 e5 a5 bd我们可以跟上面对应一下,“你”字的第一个字节0xe4的高四位二进制是1110,因此这是一个三字节编码,系统识别时就一次读取三个字节再组合成Unicode码数字,然后就可以对应到字符“你”了。字符“好”类似。
Unicode码的发展
Unicode码采用16位编码世界字符其实还是有点捉襟见肘的。因此从 Unicode 3.1 版本开始,设立了16个辅助平面(相当于Unicode码又扩充了4位),使 Unicode 的可使用空间由六万多字增至约一百万字。用白话说就是增加了几个区段,比如原始版本的Unicode码的范围是0x0000 ~ 0xffff,第一辅助平面的范围是0x10000~0x1FFFD,第二辅助平面的范围是0x20000 ~ 0x2FFFD,……
最新版的Unicode码规范提出了UCS-4,即使用4字节做Unicode编码。类似前面的utf16,对于UCS-4的Unicode码,可以采用utf32来存储,同样需要定义大小端序和BOM信息。
URLEncode
URL编解码是WEB开发中常用的编解码方法,这种编码不同于上面介绍的几种编码。上文中介绍的编码都是将一个字符对应到一个数字上,而URL编码则是字符替换,将一些非ASCII字符和一些容易引起问题的字符替换为其编码字符,解码时原样替换回来,从而解决url在网络传输中的乱码问题。
看下面一个例子:
public class TestUrlCode {
public static void main(String[] args) throws Exception {
String url="http://www.baidu.com?username=你好";
String encodeStr=java.net.URLEncoder.encode(url, "utf8");
System.out.println(encodeStr);
}
}输出:
http%3A%2F%2Fwww.baidu.com%3Fusername%3D%E4%BD%A0%E5%A5%BD我们将原url与编码后的url做一个对比(这里为了让原字符与编码字符对照起来加了一些空格):
http: / / www.baidu.com? username= 你 好
http%3A%2F%2Fwww.baidu.com%3Fusername%3D%E4%BD%A0%E5%A5%BD对比发现,编码后http、www.baidu.com、username这一些并没有改变,“:”被替换为“%3A”, “/”被替换为“%2F”, “?”被替换为“%3F”,“=”被替换为“%3D”, “你好”被替换为“%E4%BD%A0%E5%A5%BD”,这些%后面的十六进制字符都是哪里来的呢,其实就是原字符的utf8码值。前面我们已经看过“你好”的utf8码为“e4 bd a0 e5 a5 bd”,这些十六进制转换为字符串形式然后在前面加上% 就是URL编码了。因此解码就是将这些字符串去掉%然后用utf8码译出来 。
常见乱码问题
前文提到,文件保存、网络传输时,所保存和传输的都是字符对应的码值,因此查看文件时必须将这些码值反过来对应到相应的字符(解码),才能形成我们人能够看懂的字符串形式。如果解码时选取的解码方式与编码方式不一致呢,这就是乱码问题的根本原因了。看下面几个例子:
例子1
在中文版的windows系统(本文中使用win7 64位 简体中文旗舰版)桌面上新建txt文件,写上“联通”二字,保存,关闭。然后再双击打开,看到了什么?哇!乱码!
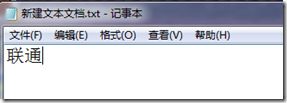
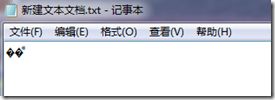
我们看看windows都做了什么。我们写的“联通”俩字没问题,保存,也就是将这俩字对应出几个数字(码值)保存起来,也没问题。等等,windows是选用哪种编码进行保存的呢?用搜索引擎查一下,原来默认选用ANSI编码,对应在中文版windows系统中就是GBK,我们用十六进制查看器验证一下:

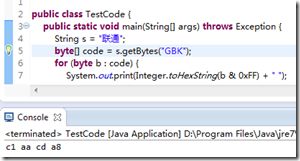
果然是GBK。然后我们将这几个十六进制数字的二进制写出来:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000看第一个字节,以110开头,第二个字节,以10开头,第三个字节,以110开头,第四个字节,以10开头。这不正好符合utf8双字节编码格式吗?因此我们再次双击打开的时候记事本就错误地认为这是utf8编码的文件,这当然的就形成乱码了。
下面使用notepad++打开,同样乱码。然后选择 格式–以ANSI格式编码 瞬间看到亲切的“联通”二字了!

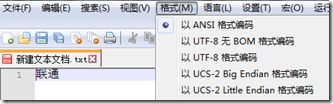
例子2
做java开发的童鞋经常遇到原Project导入Eclipse乱码问题,如下图(其实这几个乱码的原字符是“你好”二字)
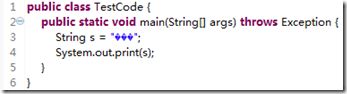
这个就比较简单了,因为原项目采用GBK编码保存的,新导入项目的Eclipse配置的是utf8编码,用utf8来解码读取gbk编码,乱码是必须滴。解决办法就是将两者保持一致即可。
例子3
有时候编码信息是在文件开始的地方声明的,比如xml文件和html文件,如下:
百度首页的源码精简后摘出一部分源码如下:
<html><head><meta http-equiv="content-type" content="text/html;charset=8”ead><body></body></html>常用的xml文件开头标示如下:
<?xml version='1.0' encoding='utf-8'?>这样的头部标示可以明确地看到文件的编码信息,然而有时候却会引发另一个问题(主要针对开发者):
比如我们写一个html文件:
<html><head><meta charset="utf-8"><title>test</title></head>
<body>
aaa你好bbb
</body>
</html>然后在保存这个文件的时候我们不小心选择了GBK编码保存。这样问题就来了,浏览器在读取这个html文件的时候会按照文件中声明的编码utf8的规则读取,这样中文又成乱码了。(因此各位coder要注意文件保存时的编码,遇到类似的问题也要知道原因和解决办法)
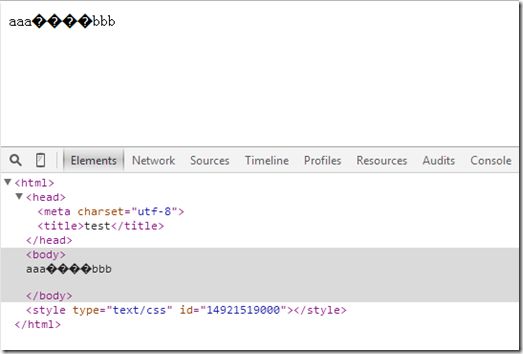
例子4
网络流的乱码问题,看下面java小程序socket通信的例子
服务器端
public class TestSocket {
public static void main(String[] args) throws Exception {
java.net.ServerSocket ss=new java.net.ServerSocket(7777);
java.net.Socket socket=ss.accept();
byte[] buffer=new byte[1024];
int len=socket.getInputStream().read(buffer);
String outStr=new String(buffer,0,len,"utf8");
System.out.println(outStr);
socket.close();
ss.close();
}
}客户端
public class TestSocketClient {
public static void main(String[] args) throws Throwable {
java.net.Socket client=new java.net.Socket("localhost",7777);
String input="你好";
client.getOutputStream().write(input.getBytes("gbk"));
client.close();
}
}先启动服务器端,再启动客户端,最后可以看到服务器端输出
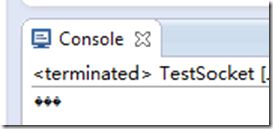
这里故意将客户端发送的编码(GBK)与服务器端接收的解码(utf8)设的不一致,出现乱码是必然的。这个错误也是显而易见的。然后并不是所有的通信乱码都是这么明显。比如java中不明确指定编码而使用默认编码,比如使用Reader和Writer对象,这时候编码信息是隐藏的,就不是那么容易发现了。
如果不确定网络中传输的编码,我们可以用wireshark抓个包看看就知道了。由于wireshark抓本地回环包比较麻烦,所以这里我们做实验的时候把客户端程序中的localhost改为百度的ip,把数据包发给百度好了。对应端口也改为80. 首先我们用nslookup命令查看百度域名对应的ip,然后随便选一个(不同地区可能得到的ip不一样,这里选择第一个180.149.132.47来当小白鼠吧)
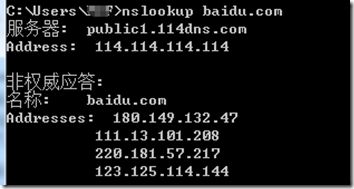
public class TestSocketClient {
public static void main(String[] args) throws Throwable {
java.net.Socket client=new java.net.Socket("180.149.132.47",80);
String input="你好";
client.getOutputStream().write(input.getBytes("gbk"));
client.close();
}
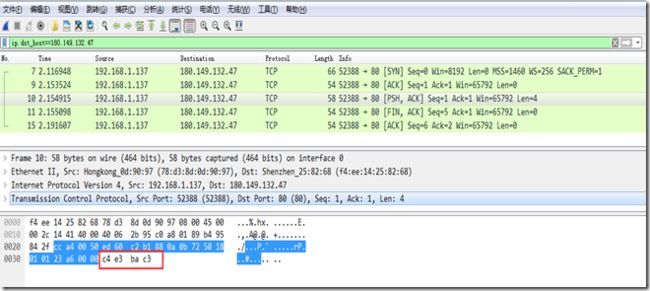
}抓到的数据包如下图,其中10号数据包就是我们程序发出的数据,数据包前面是各种协议的头信息,最后四个字节(c4 e3 ba c3)才是传输的内容。这4个字节正好是“你好”二字的GBK编码。
本文转自
聊聊计算机中的编码(Unicode,GBK,ASCII,utf8,utf16,ISO8859-1等)以及乱码问题的解决办法