RankNet与LambdaRank
在使用搜索引擎的过程中,对于某一Query(或关键字),搜索引擎会找出许多与Query相关的URL,然后根据每个URL的特征向量对该URL与主题的相关性进行打分并决定最终URL的排序,其流程如下:
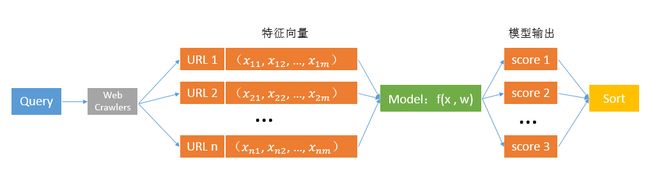
排序的好坏完全取决于模型的输出,而模型又由其参数决定,因而问题转换成了如何利用带label的训练数据去获得最优的模型参数w。Ranknet提供了一种基于Pairwise的训练方法,它最早由微软研究院的Chris Burges等人在2005年ICML上的一篇论文Learning to Rank Using Gradient Descent中提出,并被应用在微软的搜索引擎Bing当中。
相关性概率
Cost function是RankNet算法的核心,在介绍Cost function前,我们先定义两个概率:预测相关性概率、真实相关性概率。
预测相关性概率
对于任意一个URL对( Ui , Uj ),模型输出的score分别为 si 和 sj ,那么根据模型的预测, Ui 比 Uj 与Query更相关的概率为:Pij=P(Ui>Uj)=11+e−σ(si−sj)由于RankNet使用的模型一般为神经网络,根据经验sigmoid函数能提供一个比较好的概率评估。参数 σ 决定sigmoid函数的形状,对最终结果影响不大。
真实相关性概率
对于训练数据中的 Ui 和 Uj ,它们都包含有一个与Query相关性的真实label,比如 Ui 与Query的相关性label为good, Uj 与Query的相关性label为bad,那么显然 Ui 比 Uj 更相关。我们定义 p¯ij 为 Ui 比 Uj 更相关的真实概率,有p¯ij=12(1+Sij)如果 Ui 比 Uj 更相关,那么 Sij=1 ;如果 Ui 不如 Uj 相关,那么 Sij=−1 ;如果 Ui 、 Uj 与Query的相关程度相同,那么 Sij=0 。
代价函数
对于一个排序,RankNet从各个URL的相对关系来评价排序结果的好坏,排序的效果越好,那么有错误相对关系的pair就越少。所谓错误的相对关系即如果根据模型输出 Ui 排在 Uj 前面,但真实label为 Ui 的相关性小于 Uj ,那么就记一个错误pair,RankNet就是以错误的pair最少为优化目标。对于每一个pair,我们使用交叉熵来度量其预测代价,即:
化简
下图展示了 Cij 随 P¯¯¯ij 、 Pij 的变化情况:
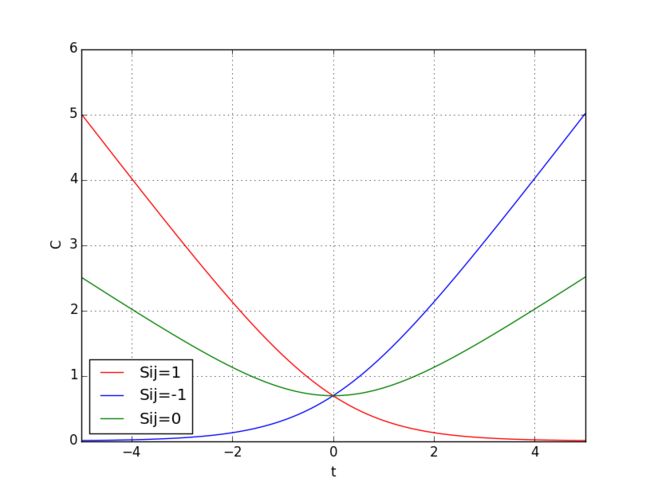
图中t表示 si−sj ,可以看到当 Sij=1 时,模型预测的 si 比 sj 越大,其代价越小; Sij=−1 时, si 比 sj 越小,代价越小; Sij=0 时,代价的最小值在 si 与 sj 相等处取得。该代价函数有以下特点:
- 当两个相关性不同的文档算出来的模型分数相同时,损失函数的值大于0,仍会对这对pair做惩罚,使他们的排序位置区分开
- 损失函数是一个类线性函数,可以有效减少异常样本数据对模型的影响,因此具有鲁棒性
总代价
梯度下降迭代
我们获得了一个可微的代价函数,下面我们就可以用梯度下降法来迭代更新模型参数 wk 了,即
η 为步长,代价 C 沿负梯度方向变化:
这表明沿负梯度方向更新参数确实可以降低总代价。我们对 ∂C∂wk 继续分解
其中
我们令 λij=∂Cij∂si=σ(12(1−Sij)−11+eσ(si−sj)) ,有
下面我们来看看这个 λi 是什么。前面讲过集合I中只包含label不同的URL的集合,且每个pair仅包含一次,即( Ui , Uj )与( Uj , Ui )等价。为方便起见,我们假设I中只包含( Ui , Uj )表示 Ui 相关性大于 Uj 的pair,即I中的pair均满足 Sij=1 ,那么
这个写法是Burges的paper上的写法,我对此好久都没有理清,下面我们用一个实际的例子来看:有三个URL,其真实相关性满足 U1>U2>U3,那么集合I中就包含 {(1,2), (1,3), (2,3)}共三个pair
显然 λ1=λ12+λ13,λ2=λ23−λ12,λ3=−λ13−λ23 ,因此我所理解的 λi 应为
λi 决定着第i个URL在迭代中的移动方向和幅度,真实的排在 Ui 前面的URL越少,排在 Ui 后面的URL越多,那么文档 Ui 向前移动的幅度就越大(实际 λi 负的越多越向前移动)。这表明每个URL下次调序的方向和强度取决于所有同一Query的其他不同label的文档。
LambdaRank
上面我们介绍了以错误pair最少为优化目标的RankNet算法,然而许多时候仅以错误pair数来评价排序的好坏是不够的,像NDCG或者ERR等评价指标就只关注top k个结果的排序,当我们采用RankNet算法时,往往无法以这些指标为优化目标进行迭代,以下图为例:

图中每个线条表示一个URL,蓝色表示与Query相关的URL,灰色表示不相关的URL。下面我们用Error pair和NDCG分别来评估左右两个排序的好坏:
Error pair指标
对于排序1,排序错误的pair共13对,故 cost=13 ,分别为:
(2,15)、(3,15)、(4,15)、(5,15)、(6,15)、(7,15)、(8,15)、
(9,15)、(10,15)、(11,15)、(12,15)、(13,15)、(14,15)对于排序2,排序错误的pair共11对,故 cost=11 ,分别为:
(1,4)、(2,4)、(3,4)
(1,10)、(2,10)、(3,10)、(5,10)、(6,10)、(7,10)、(8,10)、(9,10)所以,从Error pair角度考虑,排序2要优于排序1
NDCG指标
排序1与排序2具有相同的 maxDCG@16 ,
maxDCG@16=21−1log(1+1)+21−1log(1+2)=1.63对排序1,有
DCG@16=21−1log(1+1)+21−1log(1+15)=1.25
NDCG@16=DCG@16maxDCG@16=1.251.63=0.767对排序2,有
DCG@16=21−1log(1+4)+21−1log(1+10)=0.72
NDCG@16=DCG@16maxDCG@16=0.721.63=0.442所以,从NDCG指标来看,排序1要优于排序2。
那么我们是否能以RankNet的思路来优化像NDCG、ERR等不连续、不平滑的指标呢?答案是肯定,我们只需稍微改动一下RankNet的 λij 的定义即可
式中 ΔZij 表示,将 Ui 和 Uj 交换位置后,待优化指标的变化,如 ΔNDCG 就表是将 Ui 和 Uj 进行交换,交换后排序的 NDCG 与交换前排序的 NDCG 的差值,我们把改进后的算法称之为LambdaRank。
排序2中以箭头展示了RankNet和LambdaRank的下一轮迭代的调序方向和强度(箭头长度),黑色箭头表示RankNet算法下 U4和U10 的调序方向和强度,红色箭头表示以NDCG为优化目标的LambdaRank算法下的调序方向和强度。
以上就是我对RankNet和LambdaRank的理解,如有不对之处还请指正。
参考:
From RankNet to LambdaRank to LambdaMART: An Overview
http://blog.csdn.net/huagong_adu/article/details/40710305
http://www.cnblogs.com/kemaswill/p/kemaswill.html