spark streaming原理与实践
原理部分:
1.概述
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用,训练机器学习模型的应用,还有自动检测异常的应用。spark streaming是spark为这些应用而设计的模型。它允许用户使用一套和批处理非常接近的API来编写流式计算应用,这样就可以大量重用批处理应用的技术甚至代码。
Spark streaming使用离散化流(discretized stream)作为抽象表示,叫做DStream。DStream是随时间推移而收到的数据的序列。在内部每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列(所以得名“离散化”)。DStream可以从各种输入源创建,比如:Flume,Kafka或者HDFS。创建出来的Dstream支持两种操作:
一种是转化操作(transformation)会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream提供了许多与RDD所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
和批处理程序不同,Spark Streaming应用需要进行额外配置来保证24/7不间断工作。检查点机制:把数据存储到可靠文件系统(比如HDFS)上的机制,这也是SPark Streaming用来实现不间断工作的主要方式。
2.spark Streaming架构
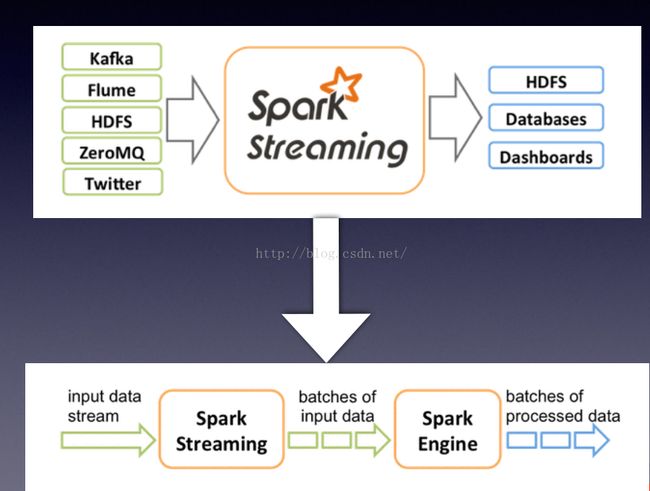
spark streaming使用”微批次“的架构,把流式计算当作一系列连续的小规模批处理来对待。spark streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设置在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以Spark作业的方式处理并生成其他的RDD。处理的结果可以以批处理的方式传给外部系统。
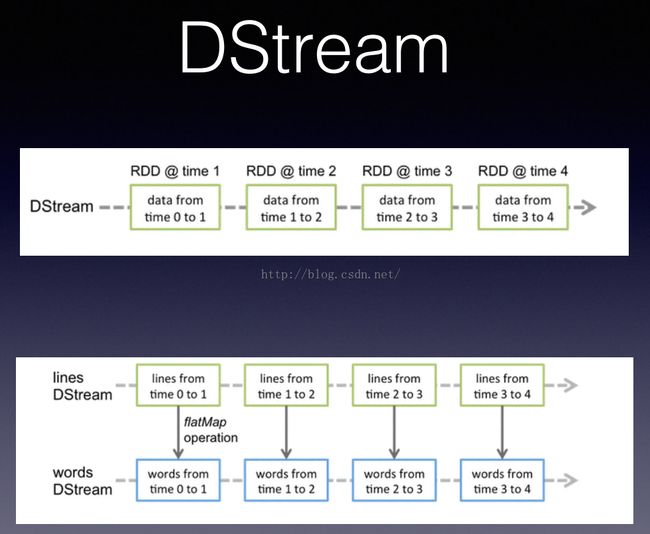
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个RDD序列,每个RDD代表数据流中一个时间片内的数据。将流式计算分解成一系列确定并且较小的批处理作业;将失败或者执⾏较慢的任务在其它节点上并⾏执⾏;较强的容错能⼒(基于Lineage)。
3.Spark Streaming在Spark的驱动器程序-工作节点的结构的执行过程
Spark Streaming为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存RDD方式一样。驱动器程序中的StreamingContext会周期性的运行Spark作业来处理这些数据,把数据与之前时间区间的RDD进行整合。
4.输入源
Kafka;Flume;Twitter;ZeroMQ;TCP sockets;HDFS....
5.转化操作(transformation)
1)无状态Stateless
在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。map, flatMap, filter, count, reduce, etc;groupByKey, reduceByKey, sortByKey, join, etc。
无状态转化操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream的每一个RDD。其也可以在多个DStream间整合数据,不过也是在各个时间区间内。eg:reduceByKey会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
2)有状态Stateful
DStream的有状态转化操作是跨时间区间跟踪数据的操作;也就是说,一些先前批次的数据也被用来在新的批次中计算结果。主要的两种类型是滑动窗口和updateStateByKey(),前者是以一个时间阶段为滑动窗口进行操作,后者则用来跟踪每个键的状态变化。
有状态转化操作需要在StreamingContext中打开检查点机制来确保容错性。
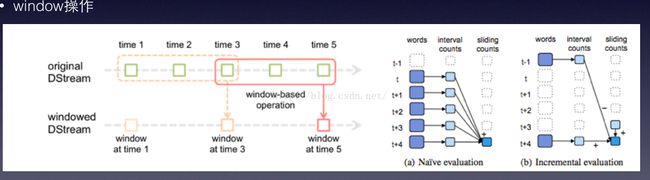
(1)基于窗口的转化操作
基于窗口的转化操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。所有基于窗口的操作都需要两个参数:窗口时长和滑动步长,两者必须是StreamContext的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的windowDuration/batchInterval个批次。
(2)updateStateByKey()转化操作
保持状态。updateStateByKey()提供了对一个状态变量的访问,用于键值对形式的DStream。
6.输出操作
print:会在每个批次中抓取DStream的前十个元素打印出来;
foreachRDD:用来对DStream中的RDD运行任意计算。也可以提供当前批次的时间,允许将不同时间的输出结果存到不同的位置。
saveAsObjectFiles
saveAsTextFiles
saveAsHadoopFiles
7.持久化
仍然允许⽤用户调⽤用persist来持久化;
默认级别为<内存+序列化>;
对于window和stateful操作默认持久化;
对于来⾃自网络的数据源,每份数据会在内存中存两份。
8.24/7不间断运行
Spark Streaming的一大优势在于它提供了强大的容错性保障。只要输入数据存储在可靠的系统中,Spark Streaming就可以根据输入计算出正确的结果,提供“精确一次”执行的语义(就好象所有的数据都是在没有任何节点失败的情况下处理一样),即使是工作节点或者驱动器程序发生了失败。
1)check point是用来保障容错性的主要机制。对于window和stateful操作必须checkpoint;通过StreamingContext的checkpoint来指定目录;通过DStream的checkpoint指定间隔时间;间隔必须是slide interval的倍数。
它可以使spark Streaming阶段性地把应用数据存储到诸如HDFS上,以供恢复时使用。
两个目的:
(1)控制发生失败时需要重算的状态数。前面已经提到过,Spark Streaming可以通过转化图的谱系图来重新计算状态,check point则可以控制需要在转化图中回溯多远。
(2 )提供驱动器程序容错。如果流计算应用中的驱动器程序崩溃了,可以重新启动驱动器程序并让驱动器程序从检查点恢复,这样spark streaming就可以读取之前运行的程序处理数据的进度,并从那里继续。
2)容错
Spark容错(确定的不可变分布式数据集基于lineage恢复);
RDD的某些partition丢失了,可以通过lineage信息重新计算恢复;
Streaming也是基于RDD计算,所以⼀一切仍然适⽤用。
3)worker节点失败
(1)数据源来⾃自外部⽂文件系统,如HDFS;一定可以通过重新读取数据来恢复,绝对不会有数据丢失。(2)数据源来⾃自网络,默认会在两个不同节点加载数据到内存,一个节点fail了,系统可以通过另⼀一个节点的数据重算.
4)Driver节点失败
会定期将元数据写到指定的checkpoint目录;
Driver失败后可以通过读取元数据重新启动Driver;
Spark 0.9.0开始已经提供⾃自动重启功能。
注意:假设代码重新编译过,必须要生成新的context,假设使⽤了getOrCreate,(getOrCreate会重新从检查点目录中初始化出StreamingContext, 然后继续处理)必须确保每次重新编译后清空 checkpoint目录。
5)接收器容错
9.性能考量
1)批次和窗口大小。500ms已经证实是比较好的最小批次大小。
选择合适的batch size 。没有最好的size,只有最合适的size,⼀一切以系统反馈的数据说话。原则:要来得及消化流进系统的数据
2)并行度
减少批处理所消耗时间的常见方式。提高并行的方法:增加接收器数目;将收到的数据显示地重新分区;提高聚合计算的并行度。
3)减少任务启动开销
使任务更⼩小(更好的序列化);
在Standalone及coarse-grained模式下的任务启动要⽐比fine-grained省时。
实践部分: