spark源码阅读笔记Spark原理(一)基本前提
集群是个物理形态,分布式是个工作方式。
集群:一堆机器,进行统一管理。集群可以运行多个分布式系统,比如同时有hadoop和spark
分布式:一个程序或系统运行在不同的机器上,這些机器可以是来自同一个集群也可以是不同集群
集群下编程环境的挑战有哪些?
第一个是并行化: 这需要以并行的方式重写应用程序,同时这种编程模型能够处理范围广泛的的计算。然而,与其他并行平台相比,集群的第二个挑战是容错:在大规模的情况下节点故障和 straggler (慢节点)将变得很常见,而且可以极大地影响应用程序的性能。最后,集群通常在多个用户之间共享,因此需要在运行时可以动态地扩展和缩减
计算资源,而且加剧了应用互相干扰的可能性深入了解可以参考:http://www.cnblogs.com/CareySon/p/3627594.html
master节点和node节点什么鬼?
master节点和node节点,就像我们自己的一台电脑一样。也就是说一个node节点可以是 4核、8核、12核,16核、
32核,每一个CPU将对应运行2-4个slice(分片),每个分片可以有多个partition ,partition是数据集的基本组成
单位,每个partition会被一个计算任务处理
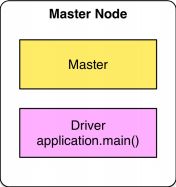
master节点有什么宏观组件?
粗粒度:表示类别级,即仅考虑对象的类别(the type of object),不考虑对象的某个特
定实例。比如,用户管理中,创建、删除,对所有的用户都一视同仁,并不区分操作的具体对象实例。
细粒度:表示实例级,即需要考虑具体对象的实例(the instance of object),当然,细
粒度是在考虑粗粒度的对象类别之后才再考虑特定实例。比如,合同管理中,列表、删除,需要区分该合同实
例是否为当前用户所创建。 一般全县权限的设计是解决了粗粒度的问题,因为这部分具有通用性,而细粒度可
以看成业务部分,因为其具有不确定性
Spark中Executor和Task這些术语什么鬼?
spark官网提供了這些术语的官方说明,具体查看:http://spark.apache.org/docs/latest/cluster-overview.html
参考文献
http://www.zhihu.com/question/20004877
http://www.cnblogs.com/CareySon/p/3627594.html
http://spark.apache.org/docs/latest/cluster-overview.html