Ubuntu14上安装配置Hadoop2.6.0
Hadoop是使用java编写的,所以在进行Hadoop开发之前,需要安装配置java环境:
JAVA安装和配置
jdk下载地址(我下载的是jdk1.8.0_92):
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
使用一下命令解压:
sudo -xvf jdk1.8.0_92.tar.gz
我将解压之后的文件(jdk1.8.0_92)拷贝到 /opt/java目录下面,将 /opt/java/jdk1.8.0_92作为JAVA_HOME:
export JAVA_HOME=/opt/java/jdk1.8.0_92
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
设置java环境变量也可以如下:
sudo gedit /etc/profile
在打开的文件中将下面的拷贝进去,并保存:
#java Home
export JAVA_HOME=/opt/java/jdk1.8.0_92
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/jre:${CLASSPATH}
export PATH=${JAVA_HOME}/bin:${PATH}
输入以下命令使得配置生效:
sudo source /etc/profile
经过以上的配置java的环境变量就配置好了,可以使用以下的命令检测:

HADOOP的安装配置
首先,需要下载hadoop2.6.0(华中科技大学的镜像下载地址):
http://mirrors.hust.edu.cn/apache/hadoop/common/
解压下载好的hadoop-2.6.0.tar.gz文件:
sudo tar -xvf hadoop-2.6.0.tar.gz
解压之后,将文件夹改名为hadoop(个人喜好),之后移动到/usr/local目录下:
sudo mv hadoop /usr/local
之后就是配置hadoop的开发环境了:
因为我们的ubuntu中可能安装了不止一个版本的jdk,所以首先需要设置首选的jdk,就像windows中设置默认打开的软件一样:
update-alternatives --config java
[注意] 执行上面的命令为了查看电脑中的jdk路径,有可能报下面的错误:
update-alternatives: 错误: 无 java 的候选项
解决方法:
(使用/opt/java/jdk1.8.0_92/bin/java来提供/usr/bin/java,需要注意的是,/opt/java/jdk1.8.0_92处是之前保存jdk的路径)
update-alternatives --install /usr/bin/java java /opt/java/jdk1.8.0_92/bin/java
这样再次运行 update-alternatives --config java就不会报错了。
编辑/.bashrc文件:
sudo gedit ~/.bashrc
打开/.bashrc文件之后,粘贴下面的代码:
#HADOOP VARIABLES START export JAVA_HOME=/opt/java/jdk1.8.0_92 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
[注意] JAVA_HOME和HADOOP_INSTALL需要根据自己java_home以及hadoop的安装路径进行配置。
执行下面的命令,更新/.bashrc的信息:
sudo source ~/.bashrc
还需要配置一项很重要的地方:编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME,并改写为自己配置的JAVA_HOME:

为了方便开发,我们可以讲/usr/local/hadoop的读写权限修改一下:
sudo chmod 774 /usr/local/hadoop
WordCount测试:

如上图,在/usr/local/hadoop下新建两个文件夹,input用于存放目标文件,output用于输出结果:
sudo mkdir input sudo mkdir output
并在input目录下放置一个num.txt文件,程序开始之后,去统计num.txt文件中各个单词出现的数量:

使用下面的命令开始WordCount程序:
// 在/usr/local/hadoop路径下执行 bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-sources.jar org.apache.hadoop.examples.WordCount input output/result
[注意]因为我使用的是hadoop-2.6.0,故而上面是hadoop-mapreduce-examples-2.6.0-sources.jar,此处需要注意一定要和你的hadoop版本号一致!!!
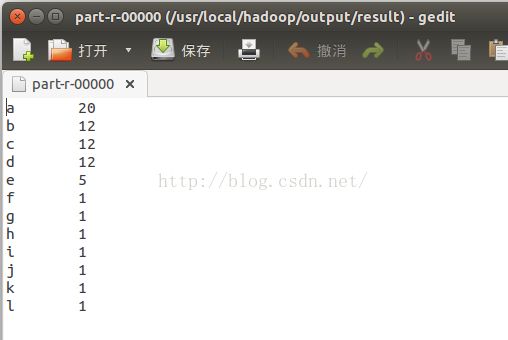
如果有下面的输出,说明Hadoop已经安装配置好了,并已经统计出了结果:

.................输出太长,只截取头部和尾部的输出内容.............

此时,在/usr/local/hadoop/output目录下可以看到下面的文件:
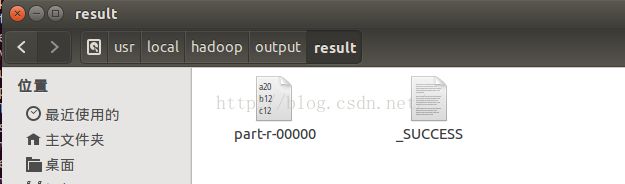
会生成result文件夹,其中part-r-00000就是统计的结果: