Linux学习笔记(八)--shell编程(下)
第七节 基础正则表达式
7.1正则表达式与通配符
l 正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。Grep、awk、sed等命令可以支持正则表达式。
l 通配符用来匹配符合条件的文件名,通配符是完全匹配。Ls、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来经行匹配。
7.2基础正则表达式
| 元字符 |
作用 |
| * |
前一个字符匹配0次或任意多次 |
| . |
匹配除换行外任意一字符 |
| ^ |
匹配行首。 |
| $ |
匹配行尾。 |
| [] |
匹配中括号内指定的任意一个字符。只匹配一个字符。 |
| [^] |
匹配除中括号内的字符以外的任意一字符。例如【^0-9】匹配任意一位非数字字符。 |
| \ |
转义符 |
| \{n\} |
表示其前面的字符恰好出现n次。例如[0-9]\{\4}匹配4位数字,【1】【3-8】【0-9】\{9\}匹配手机号码。 |
| \{n,\} |
表示其前面出现的字符出现不小于n次。例如,【0-9】\{\2,\}表示两位及以上的字符。 |
| \{n,m\} |
表示其前面的字符至少出现n次,最多出现m次。例如【0-9】\{6,8\}匹配6到8位小写的字母。 |
grep ‘正则表达式或者字符串’文件名
返回匹配符合的行
第八节 字符截取命令
8.1cut字段提取命令
cut 【选项】文件名
选项:
-f列号 提取第几列
-d分隔符 按照指定分隔符分割列
返回值: 列数据
8.2printf命令
print ‘输出类型输出格式’输出内容
输出类型:
%ns: 输出字符串。N是数字指代输出几个字符
%ni: 输出整数。N数字指代输出几个数字
%m.nf 输出浮点数。M和n是数字,指点输出位数和小数位。如%8.2,输出8位数,其中2位是小数,6位是整数。
输出格式:
\a: 输出警告音
\b: 输出退格键,也就是BackSpace键
\f: 轻触屏幕
\n: 换行
\r: 回车,也就是enter键
\t: 水平输出退格键,也就是tab键
\v: 垂直输出退格键,也就是tab键
在awk命令的输出中支持print和printf命令
Print:print会在每个输出后自动换行.(linux中默认没有)
Printf:print是标准格式输出,并不会自动加入换行符。
8.3awk命令
1.语法
[root@altman~]awk ‘条件类型1{动作1} 条件类型2{动作2}…’filename
作用:awk比较倾向将一行数据分成数个‘字段’来处理。
Awk后面接两个单引号并加上大括号{}来设置想要对数据经行的处理动作。
Awk主要处理每一行的字段内的数据,而默认的字段分割符为空格键或【tab】键。
工作流程:
l 读第一行数据,并将第一行的数据填入$0,$1,$2等变量中。其中$0代表一整行,$1代表第一个字段。
l 依据条件类型的限制,判断是否经行后面的动作;
l 做完所有的动作与条件类型
l 若还有后续的‘行’数据,则重复上述3个动作,直到所有的数据都读完为止。
2.内置变量:
| 变量名称 |
代表意义 |
| NF |
每一行拥有的字段总数 |
| NR |
目前awk所处理的是第几行数据 |
| FS |
目前的分隔符,默认是空格键 |
3.逻辑运算符
与传统运算符号规则一样。
4.注意事项
l 所有的awk的动作,即在{}内的动作,如果需要多个命令辅助时,可利用分号‘;’间隔,或者直接以【enter】按键来隔开每个命令。
l 逻辑运算当中,等号用‘==’。
l 格式化输出时,在printf的格式设置中,务必加上\n,才能经行换行
l 与bash、shell的变量不同,在awk当中,变量可以直接使用,不用加$。
8.4sed命令
Sed是一种几乎包括在所有UNIS平台(包括LINUX)的轻量级流编辑器。Sed主要是用来将数据经行选取、替换、删除、新增的命令。
支持管道符操作。
格式:
Sed 【选项】‘【动作】’文件名
选项:
-n 一般sed命令会把所有的数据都输出到屏幕,如果加入此选项,则只会把经过sed命令处理的行输出到屏幕。
-e 允许对输入数据应用多条sed命令编辑,多个动作中间用”;”分开。
-i 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出。
动作:
na\: 追加,在当前行后添加一行或多行。除最后一行外,每行末尾都要用’\’代表数据末完结。n代表行号。
c\: 行替换,用c后面的字符串替换原数据行,替换多行。除最后一行外,每行都要用’\’代表数据末完结。

ni\: 插入,在当前行插入一行或多行。插入多行时,除最后一行外,每行都要用’\’代表数据末完结。n代表行号。
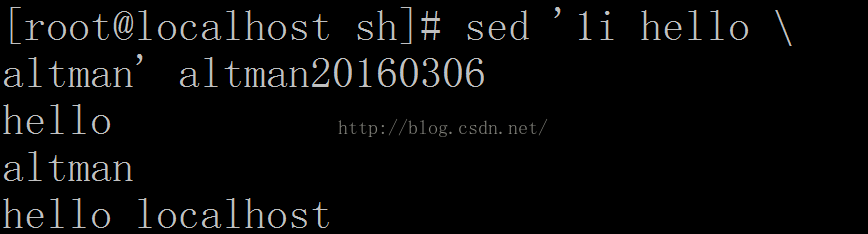
d: 删除,删除指定行。
np: 打印,输出指定行。n代表数字,打印第n行。sed –n ‘2p’,打印第二行。
S: 字串替换,用一个字符串替换另一个字符串。格式为“行范围s/旧字串/新字串/g” (和vim中的替换格式类似)

注意:
不加选项 –i 动作不会影响文件本身。看下图。

第九节 字符处理命令
1. 排序命令sort
sort 【选项】文件名
选项:
-f: 忽略大小写
-n: 以数值排序,默认使用字符串排序
-r: 反向排序
-t: 指定分隔符,默认是制表符tab键
-k n【,m】: 按指定的字段范围排序。从第n字段开始,m字段结束。(默认到行尾)
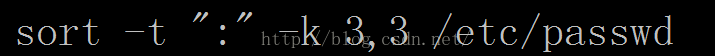
以“:”为分隔符,以第三个字段开始,第三个字段结束经行排序。
2. 统计命令wc
wc 【选项】文件名
选项:
-l: 只统计行号
-w: 只统计单词数
-m: 只统计字符数

1行,2个单词数,字符数13
第十节 条件判断
10.1 if语句
if [ ${变量1} == “条件变量”];then
elif [ ${} == “条件变量” ];then
else
fi
整数变量表达式
if [ int1 -eqint2 ] 如果int1等于int2
if [ int1 -ne int2 ] 如果不等于
if [ int1 -ge int2 ] 如果>=
if [ int1 -gt int2 ] 如果>
if [ int1 -le int2 ] 如果<=
if [ int1 -lt int2 ] 如果<
字符串比较
If [$a == $b] 如果string1等于string2
字符串允许使用赋值号做等号
if [ $string1 != $string2 ] 如果string1不等于string2
if [ -n$string ] 如果string 非空(非0),返回0(true)
if [ -z$string ] 如果string 为空
if [ $sting] 如果string 非空,返回0 (和-n类似)
两个文件比较
文件1–nt 文件2 判断文件1的修改时间是否比文件2新
文件1–ot 文件2 判断文件1的修改时间是否比文件2旧
文件1 –ef 文件2 判断文件1和文件2的inode号是否一致,可以理解为文件是否同一个文件。这个判断方法用于辨别是否为硬链接。
多重条件判断
判断1 –a 判断2 逻辑与,都成立,结果为真
判断1 –o 判断2 逻辑或,
!判断 逻辑非
按文件类型经行判断
-d文件判断文件是否存在,并且是否为目录文件。是目录为真
-e文件判断文件是否存在。存在为真
-f文件判断文件是否存在,并且判断是否为普通文件。是普通文件为真。
按文件权限判断
-r 文件判断文件是否存在,并且是否拥有读权限。
-w 文件判断文件是否存在,并且是否拥有写权限。
-x 文件判断文件是否存在,并且是否拥有执行权限。
-u 文件判断文件是否存在,并且是否拥有SUID权限。
-g 文件判断文件是否存在,并且是否拥有SGID权限。
-k 文件判断文件是否存在,并且是否拥有SBit权限。
10.2case语句
case $变量名称 in
“第一个变量内容”) #每个变量用双引号括起来
程序段
;;
“第二个变量内容”) #
程序段
;;
*) #最后一个变量内容都会用*来代表所有其他值
exit 1
;;
esac
第十一节 流程控制
11.1 while do done
while 【 condition 】
do
程序段
done
当condition条件成立时,就进入循环,直到条件不成立才停止。
11.2until do done
until 【 condition 】
do
程序段
done
当condition条件成立时,就终止循环,否则就持续进行循环的程序段。
11.3 for…do…done固定循环
for var in con1 con2 con3…
do
程序段
done
11.4 for…do...done的数值处理
for (( 初始值;限制符;执行步长))
do
程序段
done
初始值:某个变量在循环当中的初始值,直接以类似i=1设置好
限制值:当变量的值在这个限制值内,就继续经行循环,例如i<100
执行步长:每做一次循环时变量的变化量,例如i=i+1
第十二节 利用function功能
function fname(){
程序段
}
拥有内置变量,与shellscript类似。$0,$1,$2。。。
函数返回值可以通过 $?来获得
Fanme 变量1 变量2
Result=$?
数组:
a=(1 2 3)
调用
${a[$index]}
全部提取
${a[*]}
提取部分
${a[*]:begin:step}
Begin起始指针,step步长
长度
${#a[*]}