汽车分类——多元分类
Dataset
本文的数据集包含了各种与汽车相关的信息,如点击的位移,汽车的重量,汽车的加速度等等信息,我们将通过这些信息来预测汽车的来源:北美,欧洲或者亚洲,这个问题中类标签有三个,不同于之前的二元分类问题。
- 由于这个数据集不是csv文件,而是txt文件,并且每一列的没有像csv文件那样有一个行列索引(不包含在数据本身里面),而txt文件只是数据。因此采用一个通用的方法read_table()来读取txt文件:
mpg – Miles per gallon, Continuous.
cylinders – Number of cylinders in the motor, Integer, Ordinal, and Categorical.(汽缸数 )
displacement – Size of the motor, Continuous.
horsepower – Horsepower produced, Continuous.
weight – Weights of the car, Continuous.
acceleration – Acceleration, Continuous.
year – Year the car was built, Integer and Categorical.(每年生产量)
origin – 1=North America, 2=Europe, 3=Asia. Integer and Categorical
car_name – Name of the Car, will not be needed in this analysis.
- 通过read_table读取数据后,返回的auto是个DataFrame对象
import pandas
import numpy as np
# Filename
auto_file = "auto.txt"
# Column names, not included in file
names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'year', 'origin', 'car_name']
# Read in file
# Delimited by an arbitrary number of whitespaces
auto = pandas.read_table(auto_file, delim_whitespace=True, names=names)
# Show the first 5 rows of the dataset
print(auto.head())
''' mpg cylinders displacement horsepower weight acceleration year \ 0 18 8 307 130.0 3504 12.0 70 1 15 8 350 165.0 3693 11.5 70 2 18 8 318 150.0 3436 11.0 70 3 16 8 304 150.0 3433 12.0 70 4 17 8 302 140.0 3449 10.5 70 origin car_name 0 1 chevrolet chevelle malibu 1 1 buick skylark 320 2 1 plymouth satellite 3 1 amc rebel sst 4 1 ford torino '''
print(auto.describe())
''' mpg cylinders displacement weight acceleration \ count 398.000000 398.000000 398.000000 398.000000 398.000000 mean 23.514573 5.454774 193.425879 2970.424623 15.568090 std 7.815984 1.701004 104.269838 846.841774 2.757689 min 9.000000 3.000000 68.000000 1613.000000 8.000000 25% 17.500000 4.000000 104.250000 2223.750000 13.825000 50% 23.000000 4.000000 148.500000 2803.500000 15.500000 75% 29.000000 8.000000 262.000000 3608.000000 17.175000 max 46.600000 8.000000 455.000000 5140.000000 24.800000 year origin count 398.000000 398.000000 mean 76.010050 1.572864 std 3.697627 0.802055 min 70.000000 1.000000 25% 73.000000 1.000000 50% 76.000000 1.000000 75% 79.000000 2.000000 max 82.000000 3.000000 '''Clean Dataset
- 由于auto有很多缺省值和无关的列信息,因此需要先做数据清洗:首先car_name 是无关的属性,其次horsepower这个属性在统计分析时没出现,可能是因为有缺失值,观察数据集发现确实是有缺失,在数据集中缺失的值用?表示的。
# Delete the column car_name
del auto["car_name"]
# Remove rows with missing data
auto = auto[auto["horsepower"] != '?']Categorical Variables
观察属性有连续性数据和分类型数据,比如类标签是{1,2,3}是个分类型数据。倘若我们的特征中有分类型数据,比如:根据球的颜色判断球的大小,给的球的颜色{红,緑,蓝},那么如果简单的定义红=1,緑=2,蓝=3,这样是不对的。因为这默认了緑是红的两倍,而原本并不是这样的关系。我们应该重新定义2个属性{红,緑}。一个红球的特征向量是[1,0],緑球的特征向量是[0,1],而篮球的特征向量是[0,0],这些被称为虚拟变量并且在实践中经常使用。
Using Dummy Variables
在本例中,cylinders,year,origin都是分类变量(枚举型)。因此cylinders,year这两个属性不能直接应用到模型中去。year这个属性表示每年的生产量,由于每年生产量不是一个任意数,可能是一个枚举型的数字(我们没有充足的信息表明它是任意的数值),因此将其看为分类变量是比较安全的方法,所以必须要用到虚拟变量。比如汽缸数的有5类{3,4,5,6,8},因此可以设置4个虚拟变量。
- cylinders_3 – Does the car have 3 cylinders? either a 0 or a 1
- cylinders_4 – Does the car have 4 cylinders? either a 0 or a 1
- cylinders_5 – Does the car have 5 cylinders? either a 0 or a 1
- cylinders_6 – Does the car have 6 cylinders? either a 0 or a 1
- 由于8个气缸可以通过其他4个变量表示出来[0,0,0,0],因此不设置这个变量。
# input a column with categorical variables
def create_dummies(var):
# 获得该属性的取值,然后将其排序
var_unique = var.unique()
var_unique.sort()
dummy = pandas.DataFrame()
# 最后一个取值不用设置为虚拟变量
for val in var_unique[:-1]:
# d是一个布尔型数组,比如,所有为3个气缸的行值为True
d = var == val
# 产生虚拟变量时最好与原变量名称相关如:此处的cylinders_3
# astype(int)将布尔型数据转换为1(true),0(False)数据
dummy[var.name + "_" + str(val)] = d.astype(int)
# return dataframe with our dummy variables
return(dummy)
# lets make a copy of our auto dataframe to modify with dummy variables
modified_auto = auto.copy()
# make dummy varibles from the cylinder categories
cylinder_dummies = create_dummies(modified_auto["cylinders"])
# merge dummy varibles to our dataframe
modified_auto = pandas.concat([modified_auto, cylinder_dummies], axis=1)
# delete cylinders column as we have now explained it with dummy variables
del modified_auto["cylinders"]
# make dummy varibles from the year categories
year_dummies = create_dummies(modified_auto["year"])
# merge dummy varibles to our dataframe
modified_auto = pandas.concat([modified_auto, year_dummies], axis=1)
# delete cylinders column as we have now explained it with dummy variables
del modified_auto["year"]Multiclass Classification
多元分类技术可以分为以下几种:
- 一对多法(one-versus-rest,简称1-v-r)。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样就将多元分类问题转化为二元分类问题。这样k个类别的样本就构造出了k个分类器。分类时将未知样本分类为具有最大分类函数值的那类。
假如我有四类要划分(也就是4个Label),它们是A、B、C、D。于是我在抽取训练集的时候,分别抽取A所对应的向量作为正集,B,C,D所对应的向量作为负集;B所对应的向量作为正集,A,C,D所对应的向量作为负集;C所对应的向量作为正集, A,B,D所对应的向量作为负集;D所对应的向量作为正集,A,B,C所对应的向量作为负集,这四个训练集分别进行训练,然后的得到四个训练结果文件,在测试的时候,在四个模型上都进行预测。最后每个模型都有一个结果f1(x),f2(x),f3(x),f4(x).于是最终的结果便是这四个值中最大的一个。
p.s.: 这种方法有种缺陷,因为训练集是1:M,这种情况下存在biased.因而不是很实用.
一对一法(one-versus-one,简称1-v-1)。其做法是在任意两类样本之间设计一个二元分类器,因此k个类别的样本就需要设计k(k-1)/2个分类器。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
将数据集划分为训练集和测试集:
# get all columns which will be used as features, remove 'origin',因为'origin'是类标签
features = np.delete(modified_auto.columns, modified_auto.columns == 'origin')
# shuffle data
shuffled_rows = np.random.permutation(modified_auto.index)
# Select 70% of the dataset to be training data
highest_train_row = int(modified_auto.shape[0] * .70)
# Select 70% of the dataset to be training data
train = modified_auto.loc[shuffled_rows[:highest_train_row], :]
# Select 30% of the dataset to be test data
test = modified_auto.loc[shuffled_rows[highest_train_row:], :]Training A Multiclass Logistic Regression
from sklearn.linear_model import LogisticRegression
# find the unique origins
unique_origins = modified_auto["origin"].unique()
unique_origins.sort()
# 由于有三个类别,采用一对多,总共三个模型
models = {}
for origin in unique_origins:
models[origin] = LogisticRegression()
X_train = train[features]
# 每次都要修改训练集的标签数据,将当前类的标签设置为1,其它类为0
y_train = (train["origin"] == origin).astype(int)
models[origin].fit(X_train, y_train)
# testing_probs用来收集每个分类器的预测概率
testing_probs = pandas.DataFrame(columns=unique_origins)
for origin in unique_origins:
X_test = test[features]
#一个测试集要放到三个模型中求属于1的概率,[:,1]返回的是属于1的概率,[:,0]是属于0的概率
testing_probs[origin] = models[origin].predict_proba(X_test)[:,1]
Choose The Origin
- 找到概率最大的列标签
predicted_origins = testing_probs.idxmax(axis=1)
'''
Series (<class 'pandas.core.series.Series'>)
0 1
1 1
2 1
3 1
4 1
'''Confusion Matrix

# Remove pandas indicies
predicted_origins = predicted_origins.values
origins_observed = test['origin'].values
# fill in this confusion matrix
confusion = pandas.DataFrame(np.zeros(shape=(unique_origins.shape[0], unique_origins.shape[0])),
index=unique_origins, columns=unique_origins)
# Each unique prediction
for pred in unique_origins:
# Each unique observation
for obs in unique_origins:
# Check if pred was predicted
t_pred = predicted_origins == pred
# Check if obs was observed
t_obs = origins_observed == obs
# True if both pred and obs
t = (t_pred & t_obs)
# Count of the number of observations with pred and obs
confusion.loc[pred, obs] = sum(t)
print(confusion)
''' 1 2 3 1 74 5 0 2 0 13 0 3 0 1 25 '''- 在前面 美国议员党派——K均值聚类中提到了一个较为简单的方法,结果是一致的,只是细节不一样:
# Remove pandas indicies
predicted_origins = predicted_origins.values
origins_observed = test['origin'].values # fill in this confusion matrix
confusion = pandas.crosstab(predicted_origins, origins_observed)
print(confusion)
'''
col_0 1 2 3 row_0
1 74 5 0
2 0 13 0
3 0 1 25
'''Confusion Matrix Cont
- 对于1来说混淆矩阵是这样的:
'''
col_0 1 0 row_0
1 74 5
0 0 39
'''- 对于2来说混淆矩阵是这样的:
'''
col_0 2 0 row_0
2 13 0
0 6 99
'''- 对于3来说混淆矩阵是这样的:
'''
col_0 3 0 row_0
3 79 0
0 1 25
'''- 计算2的FP:
fp2 = confusion.ix[2,[1,3]].sum()
print(fp2)
'''
0
'''Average Accuracy
- 下列公式就是计算多元分类问题的精度公式,其中l表示的是类的个数:
![]()
# The confusion DataFrame is in memory# The confusion DataFrame is in memory
# The total number of observations in the test set
n = test.shape[0]
# Variable to store true predictions
sumacc = 0
# Loop over each origin
for i in confusion.index:
# True Positives
tp = confusion.loc[i, i]
# True negatives
# 计算除去第i行第i列的其他所有元素之和
tn = confusion.loc[unique_origins[unique_origins != i], unique_origins[unique_origins != i]]
# Add the sums
sumacc += tp + tn.sum().sum()
# Compute average accuracy
denominator = n*unique_origins.shape[0]
avgacc = sumacc/denominator
''' avgacc :0.96610169491525422 '''Precision And Recall
多元分类的查准率:
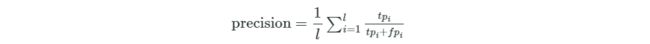
多分类的查全率:
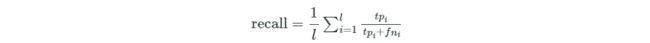
# Variable to add all precisions
ps = 0
# Loop through each origin (class)
for j in confusion.index:
# True positives
tps = confusion.ix[j,j]
# Positively predicted for that origin
positives = confusion.ix[j,:].sum()
# Add to precision
ps += tps/positives
# divide ps by the number of classes to get precision
precision = ps/confusion.shape[0]
print('Precision = {0}'.format(precision))
'''
Precision = 0.9660824407659852
'''
rcs = 0
for j in confusion.index:
# Current number of true positives
tps = confusion.ix[j,j]
# True positives and false negatives
origin_count = confusion.ix[:,j].sum()
# Add recall
rcs += tps/origin_count
# Compute recall
recall = rcs/confusion.shape[0]
'''
0.89473684210526316
'''F-Score
在银行信用卡批准——模型评估ROC&AUC一文中,画出了查准率和查全率的关系图,可以发现当查全率增加时,查准率会降低,而我们期望的是这两个值都尽可能的大,因此需要找到这两个值之间的一个平衡点,因此产生了F度量,F的取值在0到1之间,当F=1是是最完美的模型。其公式如下:
- 对于每一个类别计算一个Fi值:
![]()
- 然后计算总的F值:
![]()
# Variable to add all precisions
scores = []
# Loop through each origin (class)
for j in confusion.index:
# True positives
tps = confusion.ix[j,j]
# Positively predicted for that origin
positives = confusion.ix[j,:].sum()
# True positives and false negatives
origin_count = confusion.ix[:,j].sum()
# Compute precision
precision = tps / positives
# Compute recall
recall = tps / origin_count
# Append F_i score
fi = 2*precision*recall / (precision + recall)
scores.append(fi)
fscore = np.mean(scores)
''' fscore : 0.92007080610021796 '''Metrics With Sklearn
前面都是自己计算这些度量值,然而sklearn中有內建的函数帮忙计算。比如:precision_score, recall_score, 以及 f1_score这三个函数,他们需要输入最基本的两个参数:真实的分类,预测的分类,然后是一些可选参数,其中重点关注average这个参数:

# Import metric functions from sklearn
from sklearn.metrics import precision_score, recall_score, f1_score
# Compute precision score with micro averaging
pr_micro = precision_score(test["origin"], predicted_origins, average='micro')
pr_weighted = precision_score(test["origin"], predicted_origins, average='weighted')
rc_weighted = recall_score(test["origin"], predicted_origins, average='weighted')
f_weighted = f1_score(test["origin"], predicted_origins, average='weighted')