1-2、Spark的standalone模式安装
提前安装好hadoop,
我准备了两个节点,jdk和hadoop先安装好。
我用的两个节点,电脑配置不行,3个节点演示能更好些
1、解压
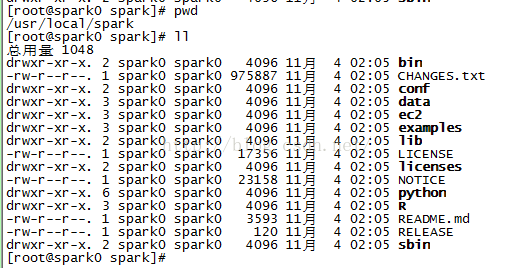
2、编辑文件:
[root@spark0 conf]# cpspark-env.sh.template spark-env.sh [root@spark0 conf]# vim spark-env.sh SPARK_MASTER_IP=192.168.6.2 [root@spark0 conf]# cp slaves.templateslaves [root@spark0 conf]# vim slaves # A Spark Worker will be started on each ofthe machines listed below. 192.168.6.2 192.168.6.3
3、配置好的拷贝到另一个几点上面去:
[root@spark0 local]# scp -r sparkspark1:/usr/local/
4、查看主节点的进程,除了worker还有master
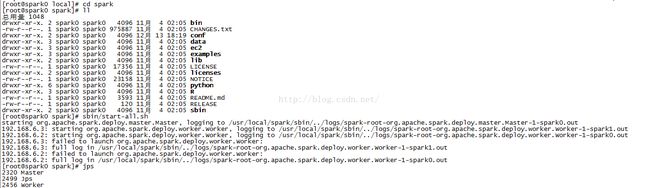
5、查看另一个节点,除了hadoop进程,只有worker,没有master进程

6、例子,先在本地设置一个文件

7、打开spark-shell,运行一个小例子:
scala> val rdd=sc.textFile("/home/spark0/spark.txt").collect

8、关闭,两个节点的spark集群:
