(Cuda)存储器Memory(二)
本文地址:http://blog.csdn.net/mounty_fsc/article/details/51092925
本部分内容为[1]CUDA_C_Programming_Guide中笔记
1 Device Memory
- 这是对后边的shared memory, global memory等的总称
- 可分为linear memory和 CUDA arrays
- CUDA arrays为纹理获取做了优化,见纹理存储器
对于线性存储器,一般用以下函数处理:
| 函数 | 描述 |
|---|---|
| cudaMalloc() | |
| cudaMemcpy() | |
| cudaMallocPitch() | 2D,返回的pitch需要在访问时使用 |
| cudaMemcpy2D() | 2D |
| cudaMalloc3D() | 3D |
| cudaMemcpy3D() | 3D |
| cudaFree() |
cudaMallocPitch例子
// Host code
int width = 64, height = 64;
float* devPtr;
size_t pitch;
cudaMallocPitch(&devPtr, &pitch,
width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
// Device code
__global__ void MyKernel(float* devPtr,
size_t pitch, int width, int height)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
2 shared Memory
2.1 不使用共享内存
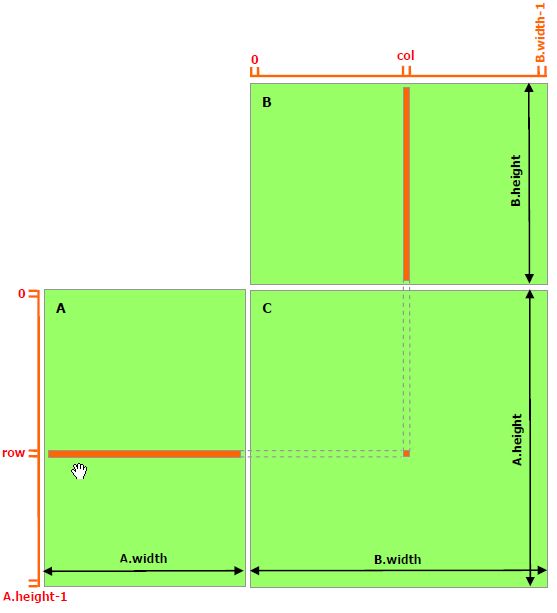
- 对于C中每个元素,使用一个线程去计算。
- 共访问全局存储器次数:对矩阵A中的每个元素,共B.width次,对矩阵B中的元素,共访问了A.height次
2.2 使用共享内存
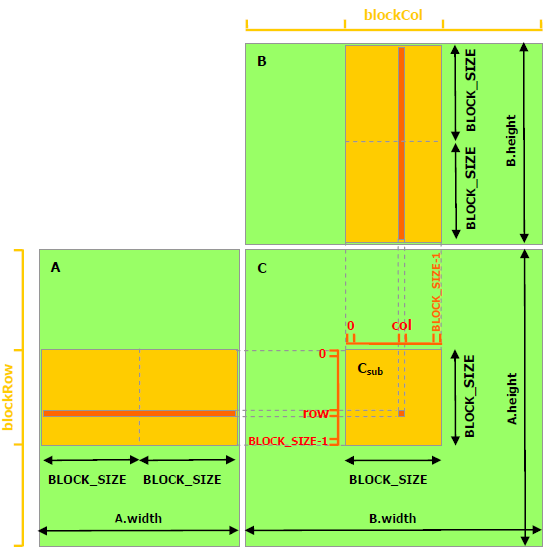
- 本质上还是,使用一个线程去计算C中的一个元素。只是角度不一样了,一个block计算一个Csub,一个block中的线程计算一个Csub中的元素。
- 策略是,对于同一个block中的线程,只读取一次全局存储器。
- 共访问全局存储器次数:对矩阵A中的每个元素,共(B.width/block_size)次,对矩阵B中的元素,共访问了(A.height/block_size)次
- 共享存储器示例代码见最后一部分
3 Page-Locked Host Memory
- 分页锁定主机存储器(也叫pinned),区别为malloc()分配的可分页的主机存储器(可分页为操作系统策略,将导致内存中只保存部分数据)
- 分页锁定主机存储器资源有限,比可分页的要容易分配失败。
相关函数:
函数 说明 cudaHostAlloc() cudaFreeHost() cudaHostRegister() 分页锁定一段malloc()分配的内存 类别
中文 英文 说明 符号 可分享存储器 Portable Memory cudaHostAllocPortable,
cudaHostRegisterPortable写结合存储器 Write-Combining Memory 映射存储器 Mapped Memory
4 Texture Memory
5 Surface Memory
相关代码
- 共享存储器示例代码:
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.stride + col)
typedef struct {
int width;
int height;
int stride;
float* elements;
} Matrix;
// Get a matrix element
__device__ float GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
// Set a matrix element
__device__ void SetElement(Matrix A, int row, int col,
float value)
{
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, int row, int col)
{
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row
+ BLOCK_SIZE * col];
return Asub;
}
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = d_A.stride = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = d_C.stride = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
// 这里因为cuda中为列优先,事实上对C作了个转置
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Block row and column
// 可以理解为在物理上是列优先,从逻辑上又转成行优先
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub
// by accumulating results into Cvalue
float Cvalue = 0;
// Thread row and column within Csub
int row = threadIdx.y;
int col = threadIdx.x;
// Loop over all the sub-matrices of A and B that are
// required to compute Csub
// Multiply each pair of sub-matrices together
// and accumulate the results
for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// Get sub-matrix Asub of A
Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B
Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory
// Each thread loads one element of each sub-matrix
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded
// before starting the computation
__syncthreads();
// Multiply Asub and Bsub together
for (int e = 0; e < BLOCK_SIZE; ++e)
Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write Csub to device memory
// Each thread writes one element
SetElement(Csub, row, col, Cvalue);
}[1]. CUDA_C_Programming_Guide