Caffe学习——使用自己的数据(非图像)训练网络
Caffe学习——使用自己的数据(非图像)训练网络
1. 鸢尾花卉数据集
鸢尾花卉数据集包含150个样本,4个特征(花萼长度,花萼宽度,花瓣长度和花瓣宽度),3个类别(山鸢尾,变色鸢尾和维吉尼亚鸢尾)[1]。
2. 所需的准备文件说明
(1)prototxt文件
xx_
deploy.prototxt:设置网络
中间层的结构。data层仅定义4D的
input_dim(分别表示batch大小,通道数,滤波器高度,滤波器宽度),最后一层没有loss层。提取特征或预测输出时使用[2];
xx_
solver.prototxt:设置训练网络所需的
网络结构文件(xx_train_test.prototxt)和
超参数,训练网络时使用;
xx_
train_test.prototxt:设置网络
每层的结构。data层中include的phase为TRAIN或TEST区分是输入数据是训练数据还是测试数据。data层有完整的定义,最后一层为loss层,训练和测试网络时都用。
(2)txt文件
xx_train_data.txt:设置xx_train_data.hdf5文件名[4];
xx_test_data.txt:设置xx_test_data.hdf5文件名。
(3)hdf5文件
xx_train_data.hdf5:存放训练数据的data和label;
xx_test_data.hdf5:存放测试数据的data和label。
3. 代码各部分说明[3]
设置Python编译环境,导入需要的库。
加载iris数据。targets的列数为3(标签或类的个数),把整数变成one-hot格式,比如2->[0 0 1]。new_data是字典:input,output分别为输入数据和输出标签的索引,输入数据为4D张量,如data层的input_dim定义。输出标签为2D矩阵(列为样本数,行为标签one-hot格式)。
def load_data():
'''
Load Iris Data set
'''
data = load_iris()
print(data.data)
print(data.target)
targets = np.zeros((len(data.target), 3))
for count, target in enumerate(data.target):
targets[count][target]= 1
print(targets)
new_data = {}
#new_data['input'] = data.data
new_data['input'] = np.reshape(data.data, (150,1,1,4))
new_data['output'] = targets
#print(new_data['input'].shape)
#new_data['input'] = np.random.random((150, 1, 1, 4))
#print(new_data['input'].shape)
#new_data['output'] = np.random.random_integers(0, 1, size=(150,3))
#print(new_data['input'])
return new_data
保存hdf5文件:将data这个块(blob)写入磁盘。这里写入的是train_data和test_data(都是new_data),分别得到xx_train_data.hdf5文件和xx_test_data.hdf5文件。
def save_data_as_hdf5(hdf5_data_filename, data):
'''
HDF5 is one of the data formats Caffe accepts
'''
with h5py.File(hdf5_data_filename, 'w') as f:
f['data'] = data['input'].astype(np.float32)
f['label'] = data['output'].astype(np.float32)
设置训练网络的模式(CPU还是GPU),get_solver从xx_solver.prototxt文件获得训练网络的超参数给solver,xx_solver.prototxt文件中的net参数定义为xx_train_test.prototxt,所以 xx_solver.prototxt不仅包含了训练用到的超参数,还把训练和测试的网络结构链接进来了。solver获得网络结构和训练用到的超参数后,solve开始训练。
def train(solver_prototxt_filename):
'''
Train the ANN
'''
caffe.set_mode_cpu()
solver = caffe.get_solver(solver_prototxt_filename)
solver.solve()
打印网络参数:打印了输入,输出,块和参数的网络结构。
def print_network_parameters(net):
'''
Print the parameters of the network
'''
print(net)
print('net.inputs: {0}'.format(net.inputs))
print('net.outputs: {0}'.format(net.outputs))
print('net.blobs: {0}'.format(net.blobs))
print('net.params: {0}'.format(net.params))
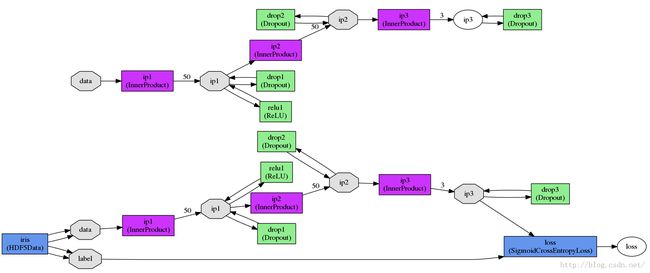
Net搭网络:根据网络参数(NetParameter)将网络的每层连接成有向循环图(DAG)[5],这里需要的文件是xxx_deploy.prototxt,同时网络类型为TEST,所以生成的网络不包含损失层,同时生成后缀为caffemodel的文件。forward得到前向输出的结果给out,out.outputs[0]返回的是块中第1个样本的结果。
def get_predicted_output(deploy_prototxt_filename, caffemodel_filename, input, net = None):
'''
Get the predicted output, i.e. perform a forward pass
'''
if net is None:
net = caffe.Net(deploy_prototxt_filename,caffemodel_filename, caffe.TEST)
out = net.forward(data=input)
return out[net.outputs[0]]
根据NetParameter打印网络结构,用于保存deploy和train_test的网络结构。
import google.protobuf
def print_network(prototxt_filename, caffemodel_filename):
'''
Draw the ANN architecture
'''
_net = caffe.proto.caffe_pb2.NetParameter()
f = open(prototxt_filename)
google.protobuf.text_format.Merge(f.read(), _net)
caffe.draw.draw_net_to_file(_net, prototxt_filename + '.png' )
print('Draw ANN done!')

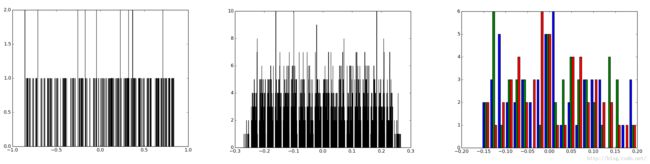
打印网络权重时用的是train_test.prototxt,用deploy.prototxt也行。绘制的网络结构图中的data和loss层为蓝色矩形块,而ip1~ip3为灰色八边形块。因为 data层的输出和loss层的输出为不带权重的真实值,所以它俩在即使在net.params中,各自的所有权重也是相同的。实验保存的图片中没有xxx_weights_xx_data/loss.png也验证了这一点。heatmap反映了 某网络中间层的输入节点和输出节点之间的权重,而histogram反映同一层网络中间层的 权重值的分布。
def print_network_weights(prototxt_filename, caffemodel_filename):
'''
For each ANN layer, print weight heatmap and weight histogram
'''
net = caffe.Net(prototxt_filename,caffemodel_filename, caffe.TEST)
for layer_name in net.params:
# weights heatmap
arr = net.params[layer_name][0].data
plt.clf()
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111)
cax = ax.matshow(arr, interpolation='none')
fig.colorbar(cax, orientation="horizontal")
plt.savefig('{0}_weights_{1}.png'.format(caffemodel_filename, layer_name), dpi=100, format='png', bbox_inches='tight') # use format='svg' or 'pdf' for vectorial pictures
plt.close()
# weights histogram
plt.clf()
plt.hist(arr.tolist(), bins=20)
plt.savefig('{0}_weights_hist_{1}.png'.format(caffemodel_filename, layer_name), dpi=100, format='png', bbox_inches='tight') # use format='svg' or 'pdf' for vectorial pictures
plt.close()
def get_predicted_outputs(deploy_prototxt_filename, caffemodel_filename, inputs):
'''
Get several predicted outputs
'''
outputs = []
net = caffe.Net(deploy_prototxt_filename,caffemodel_filename, caffe.TEST)
for input in inputs:
outputs.append(copy.deepcopy(get_predicted_output(deploy_prototxt_filename, caffemodel_filename, input, net)))
return outputs
get_predicted_output深拷贝后的predicted_outputs的每个位阈值化为0或1,这样好和one-hot格式的true_outputs比较。output_number为标签类数(这里为3)。predicted_outputs由很多深拷贝的output数组组成,每个数组都是1个维数为(1*3)的数据类型为float32的矩阵。所以predicted_outputs[i][0][j]表示第i个样本的第j个标签位的概率。
def get_accuracy(true_outputs, predicted_outputs):
number_of_samples = true_outputs.shape[0]
number_of_outputs = true_outputs.shape[1]
threshold = 0.0 # 0 if SigmoidCrossEntropyLoss ; 0.5 if EuclideanLoss
for output_number in range(number_of_outputs):
predicted_output_binary = []
for sample_number in range(number_of_samples):
#print(predicted_outputs)
#print(predicted_outputs[sample_number][output_number])
if predicted_outputs[sample_number][0][output_number] < threshold:
predicted_output = 0
else:
predicted_output = 1
predicted_output_binary.append(predicted_output)
print('accuracy: {0}'.format(sklearn.metrics.accuracy_score(true_outputs[:, output_number], predicted_output_binary)))
print(sklearn.metrics.confusion_matrix(true_outputs[:, output_number], predicted_output_binary))
主函数中:
(1)定义需要用到的prototxt文件名称;
(2)加载训练和测试数据;
(3)保存数据为hdf5文件格式;
(4)训练网络;
(5)预测输出;
(6)打印网络结构和权重;
(7)根据预测输出计算准确度。
def main():
'''
This is the main function
'''
# Set parameters
solver_prototxt_filename = 'iris_solver.prototxt'
train_test_prototxt_filename = 'iris_train_test.prototxt'
deploy_prototxt_filename = 'iris_deploy.prototxt'
deploy_prototxt_filename = 'iris_deploy.prototxt'
deploy_prototxt_batch2_filename = 'iris_deploy_batchsize2.prototxt'
hdf5_train_data_filename = 'iris_train_data.hdf5'
hdf5_test_data_filename = 'iris_test_data.hdf5'
caffemodel_filename = 'iris_iter_5000.caffemodel' # generated by train()
# Prepare data
data = load_data()
print(data)
train_data = data
test_data = data
save_data_as_hdf5(hdf5_train_data_filename, data)
save_data_as_hdf5(hdf5_test_data_filename, data)
# Train network
train(solver_prototxt_filename)
# Get predicted outputs
input = np.array([[ 5.1, 3.5, 1.4, 0.2]])
print(get_predicted_output(deploy_prototxt_filename, caffemodel_filename, input))
input = np.array([[[[ 5.1, 3.5, 1.4, 0.2]]],[[[ 5.9, 3. , 5.1, 1.8]]]])
#print(get_predicted_output(deploy_prototxt_batch2_filename, caffemodel_filename, input))
# Print network
print_network(deploy_prototxt_filename, caffemodel_filename)
print_network(train_test_prototxt_filename, caffemodel_filename)
print_network_weights(train_test_prototxt_filename, caffemodel_filename)
# Compute performance metrics
#inputs = input = np.array([[[[ 5.1, 3.5, 1.4, 0.2]]],[[[ 5.9, 3. , 5.1, 1.8]]]])
inputs = data['input']
outputs = get_predicted_outputs(deploy_prototxt_filename, caffemodel_filename, inputs)
get_accuracy(data['output'], outputs)
4. 参考链接
[1] https://zh.wikipedia.org/wiki/安德森鸢尾花卉数据集
[2] dirlt.com/caffe.html
[3] https://github.com/Franck-Dernoncourt/caffe_demos
[4] https://github.com/BVLC/caffe/issues/1519
[5] caffe.berkeleyvision.org/doxygen/classcaffe_1_1Net.html#details