图的匹配问题与最大流问题(五)——计算二分图的最大匹配
二分图的最大匹配问题第一篇已经说过,下面看看百度百科给的一些解释:
给定一个二分图G,M为G边集的一个子集,如果M满足当中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
极大匹配(Maximal Matching)是指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配的边数。最大匹配(maximum matching)是所有极大匹配当中边数最大的一个匹配。选择这样的边数最大的子集称为图的最大匹配问题。
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
计算二分图最大匹配可以用最大流(Maximal Flow)或者匈牙利算法(Hungarian Algorithm)。
如图,所示,最大匹配为4:.
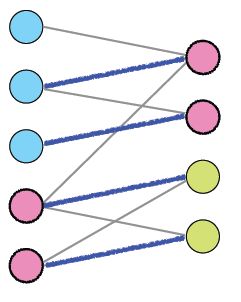
一、最大流方法计算最大匹配
最大流问题已经前面已经解释了很多了,不妨可以回去熟悉下先。 最大流问题Ford-Fulkerson解法
如图所示,对于一个二分图,令已有的边的容量(Capacity)为无穷大,增加一个源点s和一个汇点t,令s和t分别连接二部图中的一个分步,并设置其容量为1。这时得到流网络G’,计算得到的最大流就等于最大二分匹配。
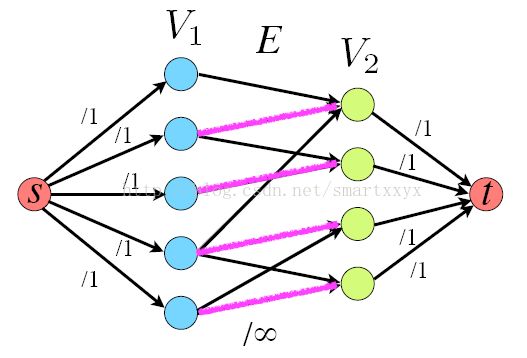
代码就很简单了,构造流网络G‘,然后调用最大流算法即得到结果。因为二分图上任何匹配的势之多为min(L,R)(L代表二分图的左部点集,R代表二分图的右部点集),所以G’中最大流的值为O(V),因此,可以再O(VE‘)=O(VE)的时间内,找出二分图的最大匹配。
二、匈牙利算法
这可是一个大名鼎鼎的算法,它实际上是对最大流算法的一种改进,提高了效率。网上有一篇文章将的很详细,很受用,可以参考: http://imlazy.ycool.com/post.1603708.html。我就不赘述了,直接上代码了,Java实现。
package matchings;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import entry.Edge;
import entry.Node;
import maxflow.FordFulkerson;
public class Matching {
private double graph[][];
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
double graph[][]={
{0,0,0,1,1,0},
{0,0,0,0,1,1},
{0,0,0,0,0,1},
{0,0,0,0,0,0},
{0,0,0,0,0,0},
{0,0,0,0,0,0}
};
double graph2[][]={
{0,0,0,0,0,1,0,0,0},
{0,0,0,0,0,1,0,1,0},
{0,0,0,0,0,0,1,1,1},
{0,0,0,0,0,0,0,1,0},
{0,0,0,0,0,0,0,1,0},
{0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0}
};
Matching m=new Matching(graph2);
int L[]={0,1,2,3,4};
int R[]={5,6,7,8};
/*
double flowNetwork[][]=m.getMaxMachingFromMaxFlow(graph2,L,R);
int length=flowNetwork.length;
for(int i=0;i<length;i++)
{
for(int j=0;j<length;j++)
{
System.out.print((flowNetwork[i][j]>0?flowNetwork[i][j]:0.0)+" ");
}
System.out.println();
}*/
System.out.println(m.getMaxMaching(graph2, L, R));
}
public Matching(double graph[][])
{
this.graph=graph;
}
/**
* Let G be a bipartite graph with partite sets U and W such that r=|U|<=|W|.
* Then G contains a matching of cardinality r if and only if U is neighborly.(which means that :For any nonempty subset X,N(X)>=X)
* 但是这种方法的复杂度为O(2^n),所以可以不如用下面两个算法直接求出最大匹配,然后比对是否是perfect matching
* @return
*/
public boolean hasPerfectMatching(double graph[][],int L[],int R[])
{
return false;
}
/**
* 利用最大流算法实现,返回最大流网络
* @param graph
* @param L
* @param R
* @return
*/
public double[][] getMaxMachingFromMaxFlow(double graph[][],int L[],int R[])
{
int length=graph.length;
double augGraph[][]=new double[length+2][length+2];
for(int i=0;i<L.length;i++)
{
augGraph[0][L[i]+1]=1.0;
}
for(int i=0;i<R.length;i++)
{
augGraph[R[i]+1][length+1]=1.0;
}
for(int i=1;i<length+1;i++)
{
for(int j=1;j<length+1;j++)
{
augGraph[i][j]=graph[i-1][j-1];
}
}
/*for(int i=0;i<length+2;i++)
{
for(int j=0;j<length+2;j++)
{
System.out.print(augGraph[i][j]+" ");
}
System.out.println();
}*/
double maxF=FordFulkerson.edmondsKarpMaxFlow(augGraph, 0, length+1);
double flowNetwork[][]=FordFulkerson.getFlowNetwork();
return flowNetwork;
}
/**
* 匈牙利算法http://imlazy.ycool.com/post.1603708.html
* (1)有奇数条边。
* (2)起点在二分图的左半边,终点在右半边。
(3)路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。)
(4)整条路径上没有重复的点。
(5)起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。(如图1、图2所示,[1,5]和[2,6]在图1中是两对已经配好对的点;而起点3和终点4目前还没有与其它点配对。)
(6)路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。(如图1、图2所示,原有的匹配是[1,5]和[2,6],这两条配匹的边在图2给出的增广路径中分边是第2和第4条边。而增广路径的第1、3、5条边都没有出现在图1给出的匹配中。)
(7)最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中去,并把增广路径中的所有第偶数条边从原匹配中删除(这个操作称为增广路径的取反),则新的匹配数就比原匹配数增加了1个。(如图2所示,新的匹配就是所有蓝色的边,而所有红色的边则从原匹配中删除。则新的匹配数为3。)
* @param graph
* @param L
* @param R
*/
public List<Edge> getMaxMaching(double graph[][],int L[],int R[])
{
int length=graph.length;
for(int i=0;i<length;i++)
{
for(int j=i;j<length;j++)
{
graph[j][i]=graph[i][j];
}
}
Set<Integer> rSet=new HashSet<Integer>();
Set<Integer> lSet=new HashSet<Integer>();
List<Edge> list=new ArrayList<Edge>();
for(int i=0;i<L.length;i++)
{
if(lSet.contains(L[i]))
continue;
Node result=null;
int j=0;
while(j<R.length)
{
result=FordFulkerson.augmentPath(graph, L[i], R[j]);
if(result==null||rSet.contains(R[j]))
j++;
else
{
boolean b=reverse(result,list,rSet,lSet);
//反正成功,直接跳出循环,从下一个左部点继续需找增广路径,否则在继续在该点寻找增广路径,知道找不到为止
if(b)
break;
else
j++;
}
}
}
return list;
}
/**
* 如果证明该增广路径满足上述6个性质,则进行反转操作,并返回true,否则什么也不做,返回false
* @param result
* @param list
* @param rSet
* @param lSet
* @return
*/
private boolean reverse(Node result,List<Edge> list,Set<Integer> rSet,Set<Integer> lSet) {
int idx=0;
List<Edge> oddEdge=new ArrayList<Edge>();
List<Edge> evenEdge=new ArrayList<Edge>();
while(result.getParent()!=null)
{
Node parent=result.getParent();
if(idx%2==0)
{
Edge e=new Edge(parent.nodeId,result.nodeId,0);
evenEdge.add(e);
}
else
{
Edge e=new Edge(result.nodeId,parent.nodeId,0);
oddEdge.add(e);
}
idx++;
result=parent;
}
/**
* 检测第6条性质
*/
for(int i=0;i<oddEdge.size();i++)
{
if(!list.contains(oddEdge.get(i)))
return false;
else
{
list.remove(oddEdge.get(i));
//System.out.println("remove: "+oddEdge.get(i));
}
}
for(int i=0;i<evenEdge.size();i++)
{
list.add(evenEdge.get(i));
lSet.add(evenEdge.get(i).u);
rSet.add(evenEdge.get(i).v);
//System.out.println("add: "+evenEdge.get(i));
}
return true;
}
}