Stanford 机器学习笔记 Week9 Anomaly Detection
Density Estimation
Problem Motivation
这个算法的目的是发现一个training set中的不规则点。给定一个training set ,如果我们能设计一个模型p,使得p(test) 等于该点是常规点的概率。那么我们就能通过判断p(test)< ε 来确定test是一个不规则点。
显然越接近原training set的中心p(test)越大。
该算法可用于质量检测等许多领域,因为一个不规则点出问题了的可能性很大。
Gaussian Distribution
首先复习一下正态分布
正态分布 N(μ, σ2 ) :

μ为平均值, σ2 为方差,函数曲线和x轴间面积恒等于1
parameter estimate指的是给定接近正态分布的数据集,找出最适合的μ和 σ2 。
方法是u = mean(X), σ2 = 1/m * sum( (X−u)2 )
Algorithm
使用正态分布来构造模型p:

给定training set X,对于X中的每个属性计算出对应的μ和 σ2 。再使用上面的公式计算。
Building an Anomaly Detection System
Developing and Evaluating an Anomaly Detection System
本节主要讲述如何评价一个异常检测算法的好坏。
上一节把每个数据点视为无label的,本节给每个数据点分类,normal的为0,anomalous的为1
同样使用Training,CV,Test的方法把数据分类。比例如下:

只有CV,Test包含anomalous。
接下来的步骤是:

使用Training Set得到model,然后使用model在CV/Test上做分类,计算上述属性。
回顾:
Precision = true positive / predicted positive = true positive / ( true positive + false positive)
Recall = true positive / actual positive = true positive / (true positive + false negative)
使用这个模型在倾斜(某种分类占据绝大部分)的数据集上有很好的效果。
用这个方法同样可以求得最优ε
Anomaly Detection vs. Supervised Learning
异常检测本质上也是一个分类算法,那么为什么不用之前的监督式算法,比如神经网络或逻辑回归呢?这取决于数据的分布。
适合异常检测的:
如果数据positive examples(比如anomalous点)的数量很少,那么最好使用异常检测。因为anomalous的种类很多而且数量很少,无法提供足够的信息共算法做分类。而且以后出现的anomalous种类可能和之前的都不一样。
适合监督学习的:
如果positive 和negative examples的数量都很多,最好使用监督算法,因为可以提供足够信息,而且之后出现的positive点有很大概率和之前的positive点一样。
Choosing What Features to Use
当某个属性的分布不接近正态分布时,虽然实际上对结果没有太大影响,但是如果能把这个数据处理成更符合正态分布的,将会得到更好的效果。常见方法是取log和开方。
当模型对anomalous和非anomalous点都预测很大的p()值时,说明模型有错误。做错误分析时,可以使用在监督学习中一样的方法。对于算法错误预测的一个个例,人工分析这个个例是否有某个属性是异于其他例子的,然后提取出这个属性假如到模型中。
Multivariate Gaussian Distribution (Optional)
Multivariate Gaussian Distribution
之前版本的anomaly detect有一个问题:
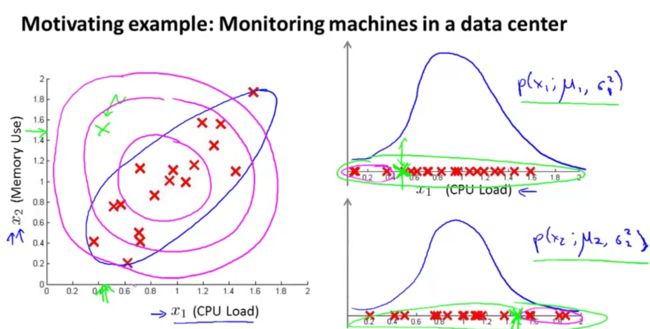
因为把每个属性分开考虑了,所以没有考虑各个属性之间的位置关系。如上图所示,N点应该是一个异常点,但是N点两个属性的值却都在正常范围以内。这种预测方法得到的样本分布是以样本中心为圆心的一个以x,y轴方向为半径的一个椭圆,这就没有考虑样本分布的形状问题。
引入新的模型:
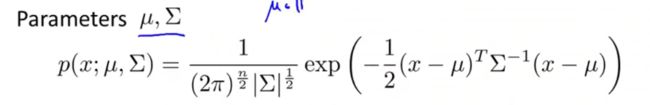
这个模型中,u控制样本中心, Σ (covarience matrix)控制样本分布的形状。
Anomaly Detection using the Multivariate Gaussian Distribution
上节公式中的u和 Σ 一般使用:

Original model是Multivariate model的一种特例,即预测分布是关于x,y轴方向对称的一个椭圆,因此 Σ 主对角线值为:

除主对角线外的位置是表示属性间关系的,因此均为0。
Original和Multivariate Model的应用区别:
Original Model:
1.可以通过手动添加新属性的方法来表示属性间关系,比如添加x3 = x1/x2
2.Original Model的计算速度很快,因为不用计算矩阵的逆
3.当样本数量很少的时候也可以使用,而Multivariate Model对此有要求
Multivariate Model:
1.自动处理属性间关系
2.要求m>n,否则 Σ 无逆(最好m>= 10 * n)