Hadoop join 关联提升版 开发代码调整解决 reduce时候 OOM问题
1、数据文件
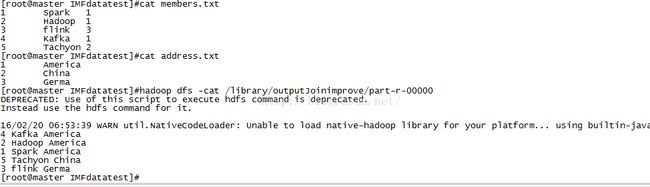
[root@master IMFdatatest]#cat members.txt
1 Spark 1
2 Hadoop 1
3 flink 3
4 Kafka 1
5 Tachyon 2
[root@master IMFdatatest]#cat address.txt
1 America
2 China
3 Germa
2、上次文件到hdfs
=======================================================
代码分析
1、自定义MemberKey hadoop如何定义key体现开发人员的水准
private int keyID
private boolean flag
compareTo方法
hashCode方法,就以keyID作为hashCode值
2、自定义类Member_Information,包含成员ID 成员名字 地址
ID 地址
String memberNo
String memberName
String addresNo
String addressName
3、自定义GroupComparator
定义组的compare方法
4、map
读入成员和地址文件,如每行分割的数据为2列,是地址文件,读入类
Member_Information的地址ID和地址,KEY值读入MemberKey, 地址ID,及
flag=true;map输出MemberKey、Member_Information;
读入成员和地址文件,如每行分割的数据不为2列,是成员文件,读入类
Member_Information的成员ID和成员名称和地址编号,KEY值读入
MemberKey, 地址ID,及flag=false;map输出MemberKey、
Member_Information
5、值的比大小。
在MemberKey中比大小,keyID 就是地址ID和flag都相等,则两个
MemberKey相等;如果地址ID一样,如果flag为true,则这个MemberKey就
小,对应的是地址文件的情况,因此就地址文件就排到了第一个元素;如
果地址ID不一样,就按地址ID比大小。
public int compareTo(MemberKey member) {
if (this.keyID == member.keyID){
if(this.flag == member.flag){
return 0;
} else {
return this.flag? -1:1;
}
} else {
return this.keyID - member.keyID > 0? 1
:-1;
}
}
分组比大小:
分组时只按KeyID()比大小,地址ID大的就大。就按地址ID进行了分组,这样地址ID相同的地址文件和成员文件中的值就组合在一起了。
class GroupComparator extends WritableComparator{
public GroupComparator() {
super(MemberKey.class, true);
}
@Override
public int compare(WritableComparable a,
WritableComparable b) {
MemberKey x = (MemberKey)a;
MemberKey y = (MemberKey)b;
System.out.println("GroupComparator has been
invoked!!!");
if(x.getKeyID() == y.getKeyID()){
return 0;
} else {
return x.getKeyID() > y.getKeyID()? 1 :
-1;
}
}
5、reduce
地址ID相同的地址文件和成员文件中的值就组合在一起,这样地址ID一样,如果flag为true,则这个MemberKey就
小,对应的是地址文件的情况,因此就地址文件就排到了第一个元素,第一个元素我们不输出,仅仅输出之后的成员文件的值,
输出 Member_Information
就避免了之前的例子join建立一个list,不停给list内存中放数据而产生的OOM溢出情况,完成了性能优化
=============================================================================================
3、运行结果
[root@master IMFdatatest]#hadoop dfs -cat /library/outputJoinimprove/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/20 06:53:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
4 Kafka America
2 Hadoop America
1 Spark America
5 Tachyon China
3 flink Germa
4、截图
5、源代码
package com.dtspark.hadoop.hellomapreduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class JoinImproved {
public static class DataMapper
extends Mapper<LongWritable, Text, MemberKey, Member_Information>{
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
System.out.println("Map Methond Invoked!!!");
String data = value.toString();
String[] dataSplited = data.split("\t");
if(dataSplited.length == 2){
Member_Information member = new Member_Information();
member.setAddresNo(dataSplited[0]);
member.setAddressName(dataSplited[1]);
// member.setFlag(0);
MemberKey memberKey = new MemberKey();
memberKey.setKeyID(Integer.valueOf(dataSplited[0]));
memberKey.setFlag(true);
context.write(memberKey, member);
} else {
Member_Information member = new Member_Information();
member.setMemberNo(dataSplited[0]);
member.setMemberName(dataSplited[1]);
member.setAddresNo(dataSplited[2]);
// member.setFlag(1);
MemberKey memberKey = new MemberKey();
memberKey.setKeyID(Integer.valueOf(dataSplited[2]));
memberKey.setFlag(false);
context.write(memberKey, member);
}
}
}
public static class DataReducer
extends Reducer<MemberKey,Member_Information,NullWritable, Text> {
public void reduce(MemberKey key, Iterable<Member_Information> values,
Context context
) throws IOException, InterruptedException {
System.out.println("Reduce Methond Invoked!!!" );
Member_Information member = new Member_Information();
int counter = 0;
for(Member_Information item : values){
if(0 == counter){
member = new Member_Information(item);
} else {
Member_Information mem = new Member_Information(item);
mem.setAddressName(member.getAddressName());
context.write(NullWritable.get(), new Text(mem.toString()));
}
counter++;
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: JoinImproved <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "JoinImproved");
job.setJarByClass(JoinImproved.class);
job.setMapperClass(DataMapper.class);
job.setReducerClass(DataReducer.class);
job.setMapOutputKeyClass(MemberKey.class);
job.setMapOutputValueClass(Member_Information.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setGroupingComparatorClass(GroupComparator.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class GroupComparator extends WritableComparator{
public GroupComparator() {
super(MemberKey.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
MemberKey x = (MemberKey)a;
MemberKey y = (MemberKey)b;
System.out.println("GroupComparator has been invoked!!!");
if(x.getKeyID() == y.getKeyID()){
return 0;
} else {
return x.getKeyID() > y.getKeyID()? 1 : -1;
}
}
}
class MemberKey implements WritableComparable<MemberKey>{
private int keyID;
private boolean flag;
public MemberKey(){}
@Override
public int hashCode() {
return this.keyID;
}
public MemberKey(int keyID, boolean flag) {
this.keyID = keyID;
this.flag = flag;
}
public int getKeyID() {
return keyID;
}
public void setKeyID(int keyID) {
this.keyID = keyID;
}
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
@Override
public void readFields(DataInput input) throws IOException {
this.keyID = input.readInt();
this.flag = input.readBoolean();
}
@Override
public void write(DataOutput output) throws IOException {
output.writeInt(this.keyID);
output.writeBoolean(this.flag);
}
@Override
public int compareTo(MemberKey member) {
if (this.keyID == member.keyID){
if(this.flag == member.flag){
return 0;
} else {
return this.flag? -1:1;
}
} else {
return this.keyID - member.keyID > 0? 1 :-1;
}
}
}
class Member_Information implements WritableComparable<Member_Information>{
private String memberNo = "";
private String memberName = "";
private String addresNo = "";
private String addressName = "";
public Member_Information(){}
public Member_Information(String memberNo, String memberName, String addresNo, String addressName) {
super();
this.memberNo = memberNo;
this.memberName = memberName;
this.addresNo = addresNo;
this.addressName = addressName;
}
public Member_Information(Member_Information info){
this.memberNo = info.memberNo;
this.memberName = info.memberName;
this.addresNo = info.addresNo;
this.addressName = info.addressName;
}
@Override
public void readFields(DataInput input) throws IOException {
this.memberNo = input.readUTF();
this.memberName = input.readUTF();
this.addresNo = input.readUTF();
this.addressName = input.readUTF();
}
@Override
public void write(DataOutput output) throws IOException {
output.writeUTF(this.memberNo);
output.writeUTF(this.memberName);
output.writeUTF(this.addresNo);
output.writeUTF(this.addressName);
}
public String getMemberNo() {
return memberNo;
}
public void setMemberNo(String memberNo) {
this.memberNo = memberNo;
}
public String getMemberName() {
return memberName;
}
public void setMemberName(String memberName) {
this.memberName = memberName;
}
public String getAddresNo() {
return addresNo;
}
public void setAddresNo(String addresNo) {
this.addresNo = addresNo;
}
public String getAddressName() {
return addressName;
}
public void setAddressName(String addressName) {
this.addressName = addressName;
}
@Override
public String toString() {
return this.memberNo + " " + this.memberName + " " + this.addressName;
}
@Override
public int compareTo(Member_Information o) {
// TODO Auto-generated method stub
return 0;
}
}