Java LinkedHashMap工作原理及实现(一)
LinkedHashMap是Hash表和链表的实现,并且依靠着双向链表保证了迭代顺序是插入的顺序。非线程安全。
首先来段代码(与HashMap那篇类似):
Map<String,Integer> map = new LinkedHashMap<>();
map.put("s1", 1);
map.put("s2", 2);
map.put("s3", 3);
map.put("s4", 4);
map.put("s5", 5);
map.put(null, 9);
map.put("s6", 6);
map.put("s7", 7);
map.put("s8", 8);
map.put(null, 11);
for(Map.Entry<String,Integer> entry:map.entrySet())
{
System.out.println(entry.getKey()+":"+entry.getValue());
}
System.out.println(map);</span>
输出结果:
s1:1
s2:2
s3:3
s4:4
s5:5
null:11
s6:6
s7:7
s8:8
{s1=1, s2=2, s3=3, s4=4, s5=5, null=11, s6=6, s7=7, s8=8}
</span>
通过结果可以看到,LinkedHashMap会记录插入的顺序,允许null的键值,当key值重复时,后面的会替换前面的。通过工作看下LinkedHashMap的结构图(ppt画图不容易,求点赞~)
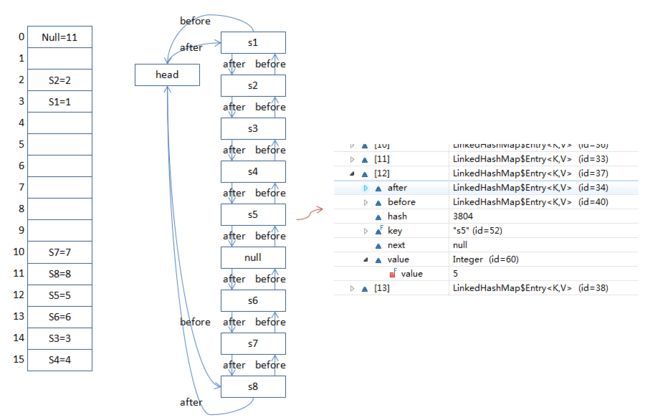
可以看到LinkedHashMap比HashMap多了一个头指针head(private权限),header指针是一个标记指针不存储任何数据。标记after和before两个指针。可以看到bullet的实体Entry也比HashMap的Entry多了before和after两个指针。(private static class Entry<K,V> extends HashMap.Entry<K,V>{Entry<K,V> before, after;} )LinkedHashMap还有一个私有变量accessOrder(private final boolean accessOrder;),默认为false,即按照插入顺序遍历,譬如开篇的例子中,如果设置为true则按照访问顺序遍历,只能通过这个构造函数设置:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
接下来举个例子(和开篇的例子类似):
Map<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("s1", 1);
map.put("s2", 2);
map.put("s3", 3);
map.put("s4", 4);
map.put("s5", 5);
map.put(null, 9);
map.put("s6", 6);
map.put("s7", 7);
map.put("s8", 8);
map.put(null, 11);
map.get("s6");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}</span>
输出结果:
s1:1 s2:2 s3:3 s4:4 s5:5 s7:7 s8:8 null:11 s6:6</span>
可以看到遍历顺序改为了访问顺序。
如果将上面的遍历方式改为:
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String name = iterator.next();
System.out.println(name + "->" + map.get(name));
}</span>
运行结果出人意料:
s1->1 Exception in thread "main" java.util.ConcurrentModificationException at java.util.LinkedHashMap$LinkedHashIterator.nextEntry(LinkedHashMap.java:394) at java.util.LinkedHashMap$KeyIterator.next(LinkedHashMap.java:405) at com.citigroup.TestLinkedHashMap.main(TestLinkedHashMap.java:24) </span>
LinkedHashMap非但没有排序,反而程序出现了异常,这是为什么呢?
ConcurrentModificationException异常一般会在集合迭代过程中被修改事抛出。不仅仅是LinkedHashMap,所有的集合都不允许在迭代器模式中修改集合的结构。一般认为,put()、remove()方法会修改集合的结构,因此不能在迭代器中使用。但是,这段代码中并没有出现类似修改集合结构的代码,为何也会发生这样的问题?
问题就出在get()方法上。虽然一般认为get()方法是只读的,但是当前的LinkedHashMap缺工作在按照元素访问顺序排序的模式中,get()方法会修改LinkedHashMap中的链表结构,以便将最近访问的元素放置到链表的末尾,因此,这个操作便引起了这个错误。所以,当LinkedHashMap工作在这个模式时,不能再迭代器中使用get()操作。Map的遍历建议使用entrySet的方式。
不要在迭代器模式中修改被迭代的集合。如果这么做,就会抛出ConcurrentModificationException异常。这个特性适用于所有的集合类,包括HashMap,Vector,ArrayList等。
LinkedHashMap可以根据访问顺序排序。那这个功能有什么牛逼之处呢?提示一下:LRU
LinkedHashMap提供了一个protected的方法:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}</span>
LinkedHashMap中的put方法直接继承HashMap的put方法,并没有重写,但是put方法中需要用到addEntry方法,并且LinkedHashMap对其进行了重写如下:
void addEntry( int hash, K key, V value int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
Entry<K,V> eldest = header.after;
if(removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}</span>
方法中调用了removeEldestEntry()方法,如果重写这个方法就可以实现LRU。
譬如:
public class LRUCache {
private int capacity;
private Map<Integer, Integer> cache;
public LRUCache(final int capacity) {
this.capacity = capacity;
this.cache = new java.util.LinkedHashMap<Integer, Integer> (capacity, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
if (cache.containsKey(key)) {
return cache.get(key);
} else
return -1;
}
public void set(int key, int value) {
cache.put(key, value);
}
}
引用《关于Java集合的小抄》来做一下总结:
扩展HashMap增加双向链表的实现,号称是最占内存的数据结构。支持iterator()时按Entry的插入顺序来排序(但是更新不算, 如果设置accessOrder属性为true,则所有读写访问都算)。
实现上是在Entry上再增加属性before/after指针,插入时把自己加到Header Entry的前面去。如果所有读写访问都要排序,还要把前后Entry的before/after拼接起来以在链表中删除掉自己。
参考资料:
1. 《Java LinkedHashMap工作原理及实现》
2. 《关于Java集合的小抄》
3. 《Java程序优化》葛一鸣等编著