详述执行map reduce 程序的步骤(本地执行MR、服务器上执行MR)
MR程序的执行环境有两种:本地测试环境、服务器环境。
1、本地环境执行MR程序的步骤:
(1)在windows下配置hadoop的环境变量
(2)拷贝debug工具(winutils)到HADOOP_HOME/bin
(3)从源码中拷贝org.apache.hadoop.io.nativeio.NativeIO.java到我们的mr的src目录下,修改NativeIO.java。(大家可去http://download.csdn.net/detail/u013226462/9516657下载。)注意:确保项目的lib需要真实安装的jdk的lib
(4)MR程序调用配置文件的代码需要改变:
a、src不能有服务器的hadoop配置文件
b、在调用时使用:
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://lida1:8020");
config.set("yarn.resourcemanager.hostname", "lida1");
下面详细介绍如何在本地直接调用MR,在服务器上执行MR。
说明:输入文件、输出路径、项目结构如下图所示

1)、编写MR代码
/**2016年4月29日
*auther:lida
*wordCount
*com.dada.wordCount
*RunTest.java
* */
package com.dada.mr;
/**
* @author lida
*
*/
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WC {
public static Text k = new Text();
public static IntWritable v = new IntWritable(1);
public static void main(String[] args) {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://lida1:8020");
config.set("yarn.resourcemanager.hostname", "lida1");
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(WC.class);
job.setJobName("wc");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setCombinerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置MR执行的输入文件
FileInputFormat.addInputPath(job, new Path("/lida-hdfs_1/input_files/wordCount"));
// 该目录表示MR执行之后的结果数据所在目录,必须不能存在
Path outputPath = new Path("/lida-hdfs_1/output_files");
// 注意:输入文件的绝对路径为:/lida-hdfs_1/input_files/wordCount/wordCount.txt,但是,命令行里不用写其绝对路径。
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("job 成功执行");
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// map task执行过程中调用的方法,计算框架会循环调用该方法,默认每行数据调用一次
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String word = st.nextToken();
k.set(word);
context.write(k, v);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text arg0, Iterable<IntWritable> arg1, Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : arg1) {
sum = sum + i.get();
}
v.set(sum);
arg2.write(arg0, v);
}
}
}
如果eclipse控制台没报错,那么该MR程序是没问题的。可从下图看到MR的执行过程。

当MR执行完毕后,可从下面两图中看到执行结果。


然后在DFS Location就能看到MR程序的执行结果。如下图所示:

2、服务器环境执行MR程序的步骤:
2.1、在本地直接调用MR,执行MR的过程在服务器上(真正企业运行环境)
(1)在src下放置服务器上的hadoop配置文件
(2)从源码中拷贝 org.apache.hadoop.mapred.YRANRunner.java到我们的mr的src目录下,修改YARNRunner.java。注意:确保项目的lib需要真实安装的jdk的lib
(3)把MR程序打包(jar),直接放到本地
(4)本地执行main方法,servlet调用MR。
下面详细介绍如何在本地直接调用MR,在服务器上执行MR。
说明:输入文件、输出路径、项目结构如下图所示
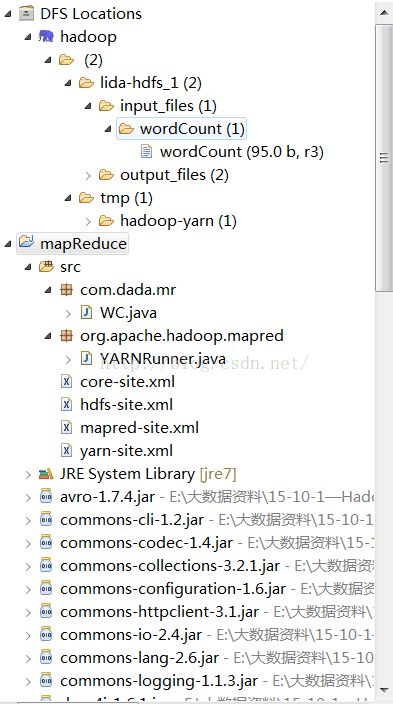
1)、编写代码
/**2016年4月29日
*auther:lida
*wordCount
*com.dada.wordCount
*RunTest.java
* */
package com.dada.mr;
/**
* @author lida
*
*/
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WC {
public static Text k = new Text();
public static IntWritable v = new IntWritable(1);
public static void main(String[] args) {
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJar("C:\\Users\\lida\\Desktop\\wc.jar"); //此处的写法和其他人的写法(job.setJarByClass(XX.class) )可能不同,原因是这样写会报错,下面的错误总结会讲到。
job.setJobName("wc");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setCombinerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置MR执行的输入文件
FileInputFormat.addInputPath(job, new Path("/lida-hdfs_1/input_files/wordCount"));
// 该目录表示MR执行之后的结果数据所在目录,必须不能存在
Path outputPath = new Path("/lida-hdfs_1/output_files");
// 注意:输入文件的绝对路径为:/lida-hdfs_1/input_files/wordCount/wordCount.txt,但是,命令行里不用写其绝对路径。
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("job 成功执行");
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// map task执行过程中调用的方法,计算框架会循环调用该方法,默认每行数据调用一次
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String word = st.nextToken();
k.set(word);
context.write(k, v);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text arg0, Iterable<IntWritable> arg1, Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : arg1) {
sum = sum + i.get();
}
v.set(sum);
arg2.write(arg0, v);
}
}
}

5)、监控。监控方式同上。
2.2、直接在服务器上使用命令的方式调用MR程序,执行过程也在服务器上
(1)把MR程序打包(jar),传送到服务器上
(2)通过命令:hadoop jar jar路径 类的全限定名 例如:hadoop jar /examples/wc.jar com.dada.mr.WordCount(wc.jar为打包好的jar包名;com.dada.mr为man方法所在的包名;WordCount为man方法所在的类)执行MR程序。
下面详细介绍如何在服务器上执行MR程序。
说明:输入文件、输出路径、项目结构如下图所示

1)、编写MR代码
/**
*
*/
package com.dada.mr;
/**
* @author 李达
*
* 2016年5月5日
* wordCount
* com.dada.wc
*/
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WC {
public static Text k = new Text();
public static IntWritable v = new IntWritable(1);
public static void main(String[] args) {
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(WC.class);
job.setJobName("wc");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setCombinerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 有两种方式解决输入、输出路径的问题:
// 1、代码中写死
// 设置MR执行的输入文件
// FileInputFormat.addInputPath(job, new
//Path("/lida-hdfs_1/input_files/wordCount"));
// 该目录表示MR执行之后的结果数据所在目录,必须不能存在
// Path outputPath = new Path("/lida-hdfs_1/output_files");
// 2、代码中不写死,写个参数,当在命令行执行MR时,再传参(官网是这么干的)。
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputPath = new Path(args[1]);
// 命令行脚本如下:
// ./hadoop jar /examplesByLiDa/wc.jar com.dada.mr.WC /lida-hdfs_1/input_files/wordCount /lida-hdfs_1/output_files
// 注意:输入文件的绝对路径为:/lida-hdfs_1/input_files/wordCount/wordCount.txt,但是,命令行里不用写其绝对路径。
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("job 成功执行");
}
} catch (Exception e) {
e.printStackTrace();
}
}
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// map task执行过程中调用的方法,计算框架会循环调用该方法,默认每行数据调用一次
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String word = st.nextToken();
k.set(word);
context.write(k, v);
}
}
}
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text arg0, Iterable<IntWritable> arg1, Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : arg1) {
sum = sum + i.get();
}
v.set(sum);
arg2.write(arg0, v);
}
}
}
2)、打包。和普通java程序的打包方式相同。
3)、执行
(1)把打好的jar包传到hdfs(actvice)所在的服务器上
(2)进入hadoop/bin/下,执行脚本
./hadoop jar /examplesByLiDa/wc.jar com.dada.mr.WC /lida-hdfs_1/input_files/wordCount /lida-hdfs_1/output_files
4)、监控。监控方式同上。
到此,全剧终!
附:测试过程中遇到的问题及解决方法
问题1:
org.apache.hadoop.security.AccessControlException: Permission denied: user=aolei, access=EXECUTE, inode="/tmp":root:supergroup:drwx------ at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:208) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:171) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5904) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5886) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOwner(FSNamesystem.java:5842) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermissionInt(FSNamesystem.java:1626) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(FSNamesystem.java:1607) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(NameNodeRpcServer.java:579) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setPermission(ClientNamenodeProtocolServerSideTranslatorPB.java:416) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source) at java.lang.reflect.Constructor.newInstance(Unknown Source) at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106) at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73) at org.apache.hadoop.hdfs.DFSClient.setPermission(DFSClient.java:2165) at org.apache.hadoop.hdfs.DistributedFileSystem$23.doCall(DistributedFileSystem.java:1236) at org.apache.hadoop.hdfs.DistributedFileSystem$23.doCall(DistributedFileSystem.java:1232) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.setPermission(DistributedFileSystem.java:1232) at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:597) at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:179) at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:301) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:389) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) at com.dada.mr.WC.main(WC.java:66) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=aolei, access=EXECUTE, inode="/tmp":root:supergroup:drwx------ at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:208) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:171) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5904) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5886) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOwner(FSNamesystem.java:5842) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermissionInt(FSNamesystem.java:1626) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(FSNamesystem.java:1607) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(NameNodeRpcServer.java:579) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setPermission(ClientNamenodeProtocolServerSideTranslatorPB.java:416) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007) at org.apache.hadoop.ipc.Client.call(Client.java:1411) at org.apache.hadoop.ipc.Client.call(Client.java:1364) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206) at com.sun.proxy.$Proxy14.setPermission(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.setPermission(ClientNamenodeProtocolTranslatorPB.java:314) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source) at java.lang.reflect.Method.invoke(Unknown Source) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy15.setPermission(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.setPermission(DFSClient.java:2163) ... 16 more
解决方法:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
hadoop dfsadmin -refreshNodes或者
hadoop fs -chmod 777 /tmp
问题2:
ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control
at org.apache.hadoop.util.Shell.runCommand(Shell.java:538)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:195)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:300)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:81)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 1
.Failing this attempt.. Failing the application.
2016-05-09 16:43:11,531 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Counters: 0
解决方法:http://www.360doc.com/content/14/0728/11/597197_397616444.shtml
问题3:
2016-05-09 17:15:03,121 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2016-05-09 17:15:06,883 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(150)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-05-09 17:15:06,909 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(259)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-05-09 17:15:06,947 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(281)) - Total input paths to process : 1
2016-05-09 17:15:07,237 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(396)) - number of splits:1
2016-05-09 17:15:07,419 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(479)) - Submitting tokens for job: job_1462791130009_0014
2016-05-09 17:15:07,535 INFO [main] mapred.YARNRunner (YARNRunner.java:createApplicationSubmissionContext(374)) - Job jar is not present. Not adding any jar to the list of resources.
2016-05-09 17:15:07,575 INFO [main] impl.YarnClientImpl (YarnClientImpl.java:submitApplication(236)) - Submitted application application_1462791130009_0014
2016-05-09 17:15:07,605 INFO [main] mapreduce.Job (Job.java:submit(1289)) - The url to track the job: http://lida1:8088/proxy/application_1462791130009_0014/
2016-05-09 17:15:07,606 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1334)) - Running job: job_1462791130009_0014
2016-05-09 17:15:11,665 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1355)) - Job job_1462791130009_0014 running in uber mode : false
2016-05-09 17:15:11,668 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 0% reduce 0%
2016-05-09 17:15:11,700 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1375)) - Job job_1462791130009_0014 failed with state FAILED due to: Application application_1462791130009_0014 failed 2 times due to AM Container for appattempt_1462791130009_0014_000002 exited with exitCode: 1 due to: Exception from container-launch: ExitCodeException exitCode=1:
ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:538)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:195)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:300)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:81)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 1
.Failing this attempt.. Failing the application.
2016-05-09 17:15:11,723 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Counters: 0
另外,从图形化界面上可看到还有一个报错信息,如下图:


解决方法:http://www.cnblogs.com/gaoxing/p/4466924.html 在mapred-site.xml中添加进hadoopjar包即可。
问题4:2016-05-09 17:49:30,572 INFO [main] mapreduce.Job (Job.java:printTaskEvents(1441)) - Task Id : attempt_1462791130009_0020_m_000000_2, Status : FAILED Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.dada.mr.WC$WordCountMapper not found at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1905) at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:722) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163) Caused by: java.lang.ClassNotFoundException: Class com.dada.mr.WC$WordCountMapper not found at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1811) at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1903) ... 8 more 2016-05-09 17:49:37,635 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 100% reduce 100% 2016-05-09 17:49:37,670 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1375)) - Job job_1462791130009_0020 failed with state FAILED due to: Task failed task_1462791130009_0020_m_000000 Job failed as tasks failed. failedMaps:1 failedReduces:0 2016-05-09 17:49:37,761 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Counters: 9 Job Counters Failed map tasks=4 Launched map tasks=4 Other local map tasks=3 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=16275 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=16275 Total vcore-seconds taken by all map tasks=16275 Total megabyte-seconds taken by all map tasks=16665600参考链接:http://stackoverflow.com/questions/21373550/class-not-found-exception-in-mapreduce-wordcount-job
解决方法:job.setJar("wordcount.jar");