Hadoop中HDFS文件系统的Append/Hflush/Read设计文档(HDFS-265:Revisit append)
转帖请注明来自本空间地址:
http://blog.csdn.net/chenpingbupt
chenpingbupt@gmail.com
原文请参:
https://issues.apache.org/jira/secure/attachment/12445209/appendDesign3.pdf
https://issues.apache.org/jira/browse/HDFS-265
译文如下:
- 读取一致性:在某一个时间点上,不同的replica上的最后一个block的大小是不同的,应该提供什么级别的一致性和如何保证在失效情况下的一致性是一个问题数据持久化:如何保证经过hflush的数据在任何错误发生的情况下,都是可以恢复的。
2:replica/block的各种状态
为了区分,在namenode中的数据block,这将DN中的block称为replica。
- 为什么需要新的状态
- 在append/hflush之前,一个replica在DN的状态要么是finalized 要么是temporary,当一个replica在刚刚被创建的时候,状态就是temporary的,在client因为发送完所有这个block的数据而请求关闭的时候,会将状态转换为finallized。在DN的restart过程中,如果replica处于temporary,将会被删除。这个特性在append/hflush之前是可以接受的,因为hdfs只会为append/hflush之前的数据持久性提供最大努力。但是如果支持了append/hflush之后,这就不可接受了,hdfs必须为under-construction的block提供更强的可持久化支持,一些temporary的replica必须要在DNrestart的重启期间持久存在。
- 这个设计中为replica引入一个新的状态叫rbw(replica
being
written)以及其他用来处理error的一些状态。在DN的memory的一个replica具有以下状态
- Finalized:一个Finalized的replica出发reopen来进行append,否则将不会收到新的bytes。所有的该block的replica都具有相同的blockid和同样的bytes,但是gs可能不同,因为gs会在errorrecovery的时候,进行增长。
- Rbw(Replica Being Written to):一旦一个replica刚刚创建或者被append,他就处于rbw状态。在这个状态中个,bytes正被写进这个replica中,所以这也是一个unclosed文件的最后一个block。在这个状态下,这个replica的长度还没确定,磁盘中的data和meta也不一定匹配。这个replica和其他的replica在bytes上也是多少不等的。但是,在这个状态下的bytes还是能够被reader看见的。为了防治失败,这个状态下的byte也要尽可能的持久化。
- Rwr (Replica Waiting to be Recovered):如果一个DN死了并且重启之后,所有的rbw的replica将会转换为rwr,rwr的replica将不会出现在任何的pipeline中,所以他也不会接受任何新的bytes数据。最后他们要么变成过期数据,要么参与到leaserecovery中,如果客户端也dies。
- rur (Replica Under Recovery):当一个lease过期了并发起replica recovery之后replica的状态也会变成rur,细节在后续leaserecovery中详述。
- Temporary:这个状态也是表名一个replilca处于under-construction中,用来进行block备份和cluster reblance,这和rbw有些相似,。但是不同的在于,他对reader是不可见的,另外在dn重启之后,也是可以被删除的。
- 在一个DN的disk中,每个DN具有三个目录:current\tem\rbw,current包含finallized的replica,tmp包含temporary replica,rbw包含rbw,rwr,rur replicas。当一个replica第一次被dfs client发起请求而创建的时候,将会放到rbw中。当第一次创建是在block replication和clust balance过程中发起的话,replica就会放置到tmp中。一旦一个replica被finallized,他就会被move到current中。当一个DN重启之后,tmp中的replica将会被删除,rbw中的将会被加载为rwr状态,current中的会load为finallized状态。
- DN升级过程中,所有的rbw和current的replica将会保存在一个snapshot中。
- NN也为此引入很多新状态,一个Block将会处于以下状态:
- UnderConstruction:一个block被created或appended之后,就是处于underconstruction状态。在这个状态内,bytes继续往这个block中写,length和gs都不是finallized的。data能够被reader看到。underconstruction中的block还会跟踪自身的write pipeline(ie:locations of valid rbw replicas)和rwr的位置,以防client端挂掉。
- UnderRecovery:当一个文件的lease过期了,如果文件的last block是underconstruction,他将会被改为underrecovery在这个block发起recovery时候。
- Committed: 一个Committed的block表名他的bytes和gs都已经被finallized的。但是还没有一个DN具有和这个block的gs/length相同的replicas。这个block的bytes和gs都不会改变了,除非进行了append。为了响应reader的请求,Committed的block仍然留有rbw-replicas的locations,同时也会保存已经进行了finallized的replicas的gs和length。在client调用NN的close file或者add new block的时候,unclose文件的underconstruction的replicas将会转换为Committed状态。如果last block处于Committed状态,那么这个文件无法被关闭,客户端必须重试。addblock和close将会扩展到包含last block的gs和长度。
- Complete:Complete的block的length和gs将不会变化,并且NN已经看到至少一个GS/length与block匹配的replicas。一个complete的block会保存finallized的replicas的locations。只有当文件的所有的block都是finallized的,才能关闭。
- 与replicas的状态不同,NN中block的状态并不持久化,当NN重启时,unclosed file的last block被加载为underconstruction,其他的block被加载为complete。
- Block
Construction
Pipeline
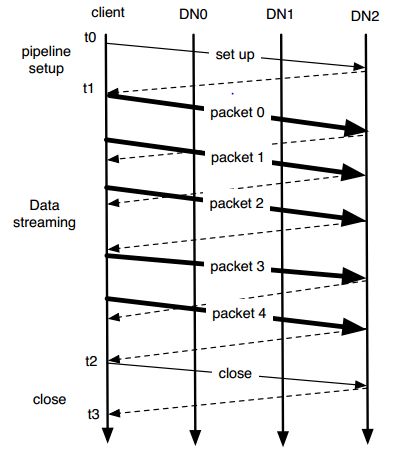
- 如图所示:一个block的是由一个个packet通过pipeline传输构建而成。整个过程分为三个步骤,t0-t1是pipeline构建阶段,t1-t2是数据传输阶段,t2-t3是pipeline清理阶段。其中:
- pipeline设置阶段:client向第一个DN沿着pipeline发起一个write-block请求,在last DN收到这个请求之后,会发送ack到他的上游。这个过程会设置好这个pipeline的网络链接并且,每个DN都会create或者append一个replica来准备写
- 数据传送阶段:用户数据首先在client side缓存着,填满一个packet之后,发布到pipeline中。如果上一个发布到pipeline的packet被ack了的话,下一个pipeline才被发布到pipeline上。在pipeline上的packet数通过client的出窗滑动窗口来限制。如果一个用户显示的call hflush,那么正在写的那个packet立即就会被发布到pipeline中,即使没填满也会如此。hflush是一个同步操作,也就是说在这个hflush的packet被ack之前,再也不能写数据了。
- 在所有的packet都被ack之后,client会发起close请求。这样能确保即使是数据传送过程中失败了的话,recovery不会遇到有些replicas是finallized的,有些是没写完的情况。
- block传送示意图
- Packet handling at a DN
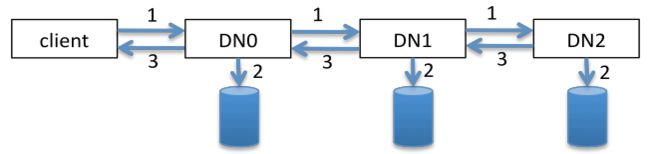
- 如图所示,对于每个packet来说,pipeline中的DN必须要处理三件事情:
- 数据传送,这包括
- 从client或者DN中,接受data。
- 将数据写往下游DN,如果不是最后一个DN。
- 将data和crc写到磁盘的block file和meta file
- Ack传送,这包括
- 接受下游的DN的ack信息,如果不是最后一个DN。
- 将Ack发送上游DN或者client。
- 数据传送,这包括
- 值得注意的是,上面的数字标号并不是执行顺序。如:ack(3)在数据传送(1)之后,数据写磁盘(2)可以发生在接受数据(1.1)之后的任何时候。一般来说,算法会选择将写磁盘的过程放在将数据写往下一个DN之后和接受下一个packet之前。
- 每个DN为每个pipeline提供了两个线程,data线程处理数据传送和磁盘写入。对于每个packet,他顺序执行1.1,1.2,2这些操作。一旦数据被flash到了disk,它就能从DN中的mem上删除。ack线程主要处理ack流,对于每个packet,它顺序执行3.1,3.2这两个操作。这两个并发线程并不会在2和3这两个操作上进行顺序协调,也就是说,ack可能会发生在pakcet写入磁盘之前。
- 这个算法在写入性能,持久性,算法简单性之间选取了折衷,他能够:
- 当ack接受到之后,尽早将数据写往disk来提升data的持久化。
- 并行进行data/ack写完磁盘和下游pipeline的过程
- 简化buffere管理,因为每个pipeline最多只有一个packet在mem中。
- packet数据处理示意图
- 如图所示,对于每个packet来说,pipeline中的DN必须要处理三件事情:
- 一致性支持
- 当一个client从rbw的replica读数据的时候,DN并不一定将他收到的所有数据设置为可见。
- 每个rbw的replicas保存两个计数器:
- BA:下游DN已经ack过的bytes数。这些bytes对于任何reader都是可见的,下文称此为可见长度。
- BR:这个block上已经接受到了的bytes数,包括disk中的和mem中的
- 假定所有的pipeline中的DN具有(BA,BR)=(a,a),client发布一个b个bytes的packet到pipeline之后不再往pipeline写入别的packet,除非收到这一个packet的ack。这时候:
- DN在执行上一节的1.1之后,立即将(BA,BR)改为(a,a+b)。
- DN在执行上一节的3.1之后,立即将(BA,BR)改为(a+b,a+b)。
- 当一个成功的ack发送到ack的时候,所有pipeline的DN都有(BA,BR)=(a+b,a+b)。
- 一个具有N节点的pipeline(DN0,DN1,DN2。。。DNN-1),假定DN0是最靠近writer,依次排序,那么在任何时刻(t)都有以下性质:
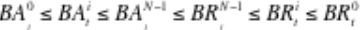
,其中下标为时间t,上标为DN编号。
- 这个性质保证了,一旦一个byte在是可见的,那么所有的pipeline中的DN都有这个byte。
- 假定BS(t,c)是client在时间(t)已经发布到pipeline中的bytes,BA(t,c)是时间(t)client已经收到了Ack的bytes,那么以下性质成立:
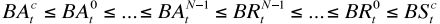
- 当打开一个未关闭的文件来读取的时候,如果最后一个block时候uder construction的是,必须保证任何byte在DNi上可读的话,在DNj上也必须可读,即使BA(i)>BA(j)。
- 算法一
- 当一个reader读取一个uc-block的时候,首先获取一个replicas的BA,如果读取位置大于BA,client将抛出EOF异常。
- 只有小于BA的位置读取请求会被forward到DN上,当DN收到读取位置小于BR的时候,都可以返回所需的数据。
- 当client发起一个(blck, off, len)读取请求的时候,如果DN拥有这个block的replicas,并且replica的gs比请求的gs更新或相等的时候,就可以服务这个请求。
- off+len的大小必须要小于等于BAj,这里的BAj是DNj上该replicas的状态,DNj是cient请求长度的节点
- 如果服务请求的DNi的replicas状态是(BAi,BRi),那么:
- 如果off+len<=BAi,DNi能够安全的服务这个请求
- 如果off+len>BAi,因为off+len<=BAj,BAj>=BAi。那么必须有BRi>=BRj>=BAj,因此BRi>off+len,DNi也可以服务这个请求。
- off+len绝不应该大于BRi,否则,DN将会log这个错误,并且拒绝这个客户端。
- 如果正在服务读请求的DNi挂机了,那么client立即将read请求切换到其他的DN上来完成。
- 这个算法虽然简单,但是需要先去获取数据长度,然后需要重新打开去获取数据。
- 算法二
- 这个算法让client来执行,一致性控制和DN传送数据。
- client发起读请求 (blck, off, len)时,如果某个DN的对应的replica的GS不旧于请求的block的GS,则服务该请求。
- 假定当前block的状态为(BAi, BRi),那么DNi将发送bytes[off, MIN(off+len,BRi)]和BAi到client端
- client接受之后将数据缓存,同时也保存最大的BA。返回数据给应用方的时候,也返回最大BA个bytes
- 如果DNi失败了,client将请求切换到另外一个DN。
- 假定有一个pipeline为N个DN,client在时间(t)提供给application的bytes为BR(t,c),那么有BR(t,c)<=BA(t,N-1)<=BR(t,N-1)<=BR(t,i)<=BR(t,0)。那么不管client从哪个DN中读取数据,所有的DN都有client之前读取的bytes
- 这个算法需要重新设计协议及client,,但是带来的好处是,没有必要打开两次文件。
- 在0.21中仍然还在讨论使用哪个算法来实现。
- Append
API
support
- client向NN发起append请求。
- NN检查文件,并确保文件已经关闭。然后再检查文件的最后一个block,如果这个未满并且没有replicas,那么这个append将失败。否则,如果last block是不满的,NN将其改为under-construction,将其replicas初始化为pipeline,然后将block的id,gs(新的),length和它的locations返回给client。如果last block是满的,那么NN分配一个新的block。
- 如果last block结束位置不是在checksum chunk的边界,为了计算checksum,必须读取最后那个部分crc chunk。
- Durability
support
- NN将确保所有已经complete的blocks将符合replication factor
- under-construction的block在此暂不详述。
- pipeline recovery
- pipeline建立阶段
- 如果一个DN在建立pipeline的时候,检查到错误,那么DN首先发送一个failure ack给上游DN,然后关闭这个block file和tcp链接。如果一个客户端检查到一个错误,那么依据pipeline的用途,处理方法也不一样,分为:
- 如果pipeline是用来创建新block,那么client将abandon这个block,重新向NN请一个新的block。然后重新建立pipeline
- 如果pipeline为了append,那么client在剩下的DN中重建pipeline,并且将GS提高。具体细节后面还会详述。
- 其实有一个特殊情况是在Token失效导致pipeline建立不成功的情况,此时client应该用原来的DNs重建这个pipeline。但是在0.21中,为了避免这种特殊处理,那么在建立pipeline之前,每次都会从NN中获取一次Token
- 如果一个DN在建立pipeline的时候,检查到错误,那么DN首先发送一个failure ack给上游DN,然后关闭这个block file和tcp链接。如果一个客户端检查到一个错误,那么依据pipeline的用途,处理方法也不一样,分为:
- 数据传输阶段
- 数据传送过程中,一旦错误发生,DN将自己从pipeline中退出,然后关闭所有的链接,关闭on-disk文件
- 当client检查到错误,将停止数据发送,使用剩余的DNs重构pipeline,replicas的GS重新增加
- client使用新GS重新从BA(c)这个位置发送数据到pipeline中。可以稍微优化一点,让client从MIN(BR(i) of 所有新的pipeline的DNs)开始发送。
- 如果DN接受到一个packet发现自己已经拥有该packet了,那么简单发送data到pipeline下游,而不写数据到disk中。
- 在pipeline重构过程中,所有在recovery之前的可见的数据,在pipeline recovery的过程中和之后都是可见的。
- 关闭阶段
- 一旦client检查到失效,将会使用剩下的DN重构pipeline,每个DN将replicas的GS更新并且将未finallized的replica进行finallized。网络链接在ack发送之后也被关闭
- pipeline建立阶段
- DN重启
- DN重启过程中,读取所有的rbw目录下的replica并且加载为WaitingToBeRecovered,长度被设置为crc能够match的最大的长度。
- WaitingToBeRecovered状态的replica将不会服务任何读取请求也不参与pipeline重构
- WaitingToBeRecovered最终要么在client存活时会因为过期而被NN删除,要么在client挂了的话被lease recovery设置为finallized。
- NN重启
- NN不会保存block的状态,所以当NN重启之后需要恢复所有block的状态。一个未关闭的文件的最后一个block会变成under-construction,而不管这个block的前世的状态是什么样的。其余的block都将变成complete
- DN在注册NN之后,将所有状态的block(finalized, rbw, rwr, and rur)发送blockreport到NN上。
- NN在至少有一个replica的complete和under-construction的block数目达到一定的数目之后才会退出safemode
- LeaseRecovery
- 当一个文件的lease过期后,NN需要为客户端关闭文件。这有两个问题:1)并发控制,如果一个lease Recovery执行的时候,client仍然还活着,并且在设置pipeline或writing,close,Recovery的时候。2)一致性保障:如果最后一个block是under-construction,所有它的replicas都必须要rollback到一个一致的状态。所有的replica有一致的长度和GS
- NN在更新lease的时候,改变文件的leaseholder为dfs并且将这个改变写入editlog。那样,即使是有client仍然存活,所有的write相关的操作(asking for a new generation stamp, getting a new block, or closing the file)会因为没有lease而无法进行。这就防止了client端并发改变未关闭的文件。
- NN检查最后两个Block,其余的都应该是complete。下表是这两个block所有的可能状态组合:
- BlockRecovery
- NN选择一个primary DN(PD)来做代理发起这个Recovery工作,PD可以是任何一个拥有该Block的replica的DN,如果一个都没有,那么该Recovery将会中止
- NN获取一个新的GS,并将last block由under-construction改为under-Recovery。这个underRecovery的block具有一个唯一的RecoveryID(其实就是新的GS),任何PD和NN的通信必须要使用这个RecoveryID来作为凭证。这样就能并发的进行blockRecovery。基本的规则是最近的Recovery总是preempts之前的Recovery
- NN向PD发送一个新的GS,blkID,oldGS和所有状态(finallized,rbw,rwr)的replica的位置
- PD进行blockRecovery的时候:
- PD要求具有该block的replica的DN去执行replica Recovery:
- PD发送每个相关的DN一个RecoveryID,blkID,GS
- 每个DN检查他的replica状态:
- 检查存在性:如果DN没有replica,或者replica的GS比发来的block的GS要老,或者比RecoveryID要新,那么抛出ReplicaNotExistsException.
- 停止写:如果一个replica处于写状态,并且有对应的写线程,那么interrupted这个写线程并且等待结束。如果interrupted发生在接受packet的时候,写线程将停止并抛出部分packet。然后确保磁盘的bytes和BR一致,最后关闭block文件和crc文件。这样预防client写和blockRecovery并发问题。BlockRecovery禁止了client的写行为,导致了pipeline失效。而后续的pipelineRecovery因为不能从NN中的underrecovery状态block获取新的GS而失败。
- 停止之前的Recovery:当一个replica已经处于rur状态,如果新Recovery请求的RecoveryID比rur中的要老或者等于,将会抛出RecoveryInProgressException。否则将rur的replica的RecoveryID记为新的ID。
- 状态转换:如果没有正在运行的Recovery,那么将replica改为rur,设置它的RecoveryID为新的RecoveryID并设置一个引用到老的状态。任何从PD到DN的交互和这个RecoveryID匹配。为了处理并发的blockRecovery,最新的Recovery永远禁止老的Recovery,另外两个Recovery绝不能交叉执行
- Crc检查:最后检查CRC,如果不能匹配,那么抛出CorruptedReplicaException,如果replica是rbw和finallized的。如果是rwr的,那么将block截断到最后一个能match的位置。
- 检查存在性:如果DN没有replica,或者replica的GS比发来的block的GS要老,或者比RecoveryID要新,那么抛出ReplicaNotExistsException.
- 如果没有异常抛出,每个DN向PD返回<replica id, replica GS, replica on‐disk len, pre‐recovery state>.
- 接受到所有的DN返回之后,PD将决定出一个所有的replica都同意的长度。
- 如果一个DN抛出RecoveryInProgressException,PD将中止Recovery
- 如果所有的DN抛出异常,那么Recovery也就中止
- 如果max(Leni for all reported DNi) ==0,PD请求NN删除该Block
- 否则检查各个replilca的长度,来决策出一个公认的长度,下表是两个replica情况下的,所有的可能性。
- 长度恢复
- PD请求所有的DN去Recover该replica,请求参数为:blkID,newGS,new length
- 如果DN没有该replica处于rur状态或者它的RecoveryID和newGS不相配,将此DN的Recovery返回失败
- 否则,DN在内存和磁盘中都将replica的GS设置为newGS。然后依据newlength更新mem的replica长度,磁盘中的blk文件和crc文件都进行更新。然后如果replica不是处于finallized的,那么进行finallized。这个Recovery是返回成功的。
- PD检查各个DN的返回结果,如果所有的失败了,那么就失败该过程。如果有的成功有的失败,那么PD从NN获取newGs用成功的DN再次进行Recovery过程。如果所有的都成功了,那么PD将newGS和length向NN汇报,NN将finallized这个block并且如果所有的block都是complete的话,也关闭该文件。最终NN强制关闭该文件,如果close多次都不成功的话。
- PD要求具有该block的replica的DN去执行replica Recovery:
- 如果pipeline中至少有一个DN是活的,并且进行Recovery的replica是完好的,那么Leaserecovery的过程也能保证任何在Recovery之前能够被reader看到的数据,在Recovery之后,这些数据还是存在的。这是因为:
- 在case1.2.3中,有一个finallized的replica,说明client在blk创建过程的第一步和第三步死去了。这个算法不会移除任何数据
- 在case4.5中,所有的replica都是在rbw中,说明client在blk创建的第二步中死去了,假定pre-recovery的pipeline中N个DN(DN0,DN1.....DNN-1)。那么DNi在4.1.2中返回的长度必须和等于BR(i)。假定一个子集S参与了长度协商,你们newLength= MIN(BRi, for all DataNodes in S) >=BRN‐1>=BAN‐1>=..>=BA0,这也不会删除数据
- 在case6中,算法不提供任何保证,因为所有的DN都重启过了


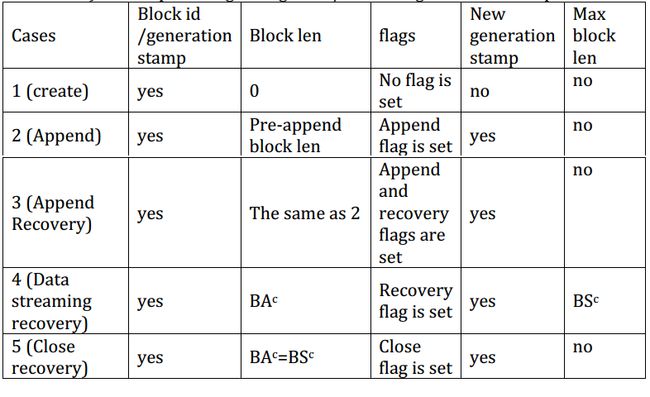
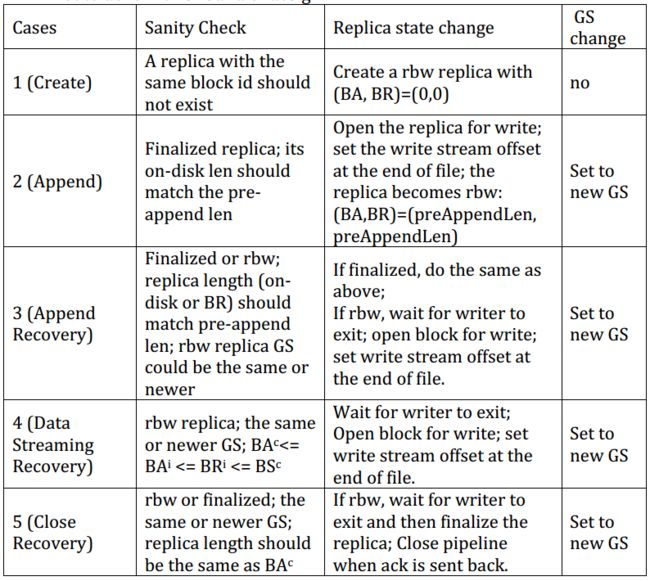
- Pipeline设置原因,总共有5个:
- Create:当一个block被创建时,一个新的Pipeline需要在数据传送之前建立好
- Append:当一个文件被Append的好似好,如果最后一个block不是满的,Pipeline建立在相应的replica的DN上建立
- AppendRecovery:如果case2失败,剩下的DN将建立一个新的Pipeline
- DN-Streaming-Recovery:数据传送失败时候,剩下的DN将建立一个新的Pipeline来续传
- CloseRecovery:当Pipeline关闭失败,剩下的DN需要建立一个Pipeline来finallized这个block
- Pipeline设置步骤
- case2-5都是在已有的block上建立Pipeline,所以blk的GS需要在Pipeline建立时重新增长,client会向NN请求newGs
- client在新的Pipeline发送blk的写请求,请求参数为:blkID,oldGS,blkLength,max replica length,flags,and/or newGS,具体如下表
- 下表展示了当一个DN收到Pipeline设置请求时的操作。注意,rwr的replica不参与到PipelineRecovery,虽然一些特殊情况下,rwr的replica也可以参与进来,但是那些case太难发生了,所以这一轮的设计中,暂时不考虑。
- 在case2-4中,一个成功的Pipeline设置会使得client向NN通知newGS,minLength,新Pipeline中的DN。然后NN更新对应block的GS,len,locations。
- 如果Pipeline设置失败,如果至少还有一个DN在线,设置好RecoveryFlag从第一步开始重做。否则,如果没有一个DN在线将Pipeline设置失效,如果一个用户程序在hflush/write中block住了,那么将unblock这个线程然后抛出EmptyPipelineException。否则下一个 write/hflush/close直接抛出EmptyPipelineException。
- client Reports
- 在以下情况,client通知NN一个under-construction的blk的metainfo或者状态改变了。
- 在Pipeline设置情况(case2,3,4),新的Pipeline建好之后,client会通知NN(blk_newGS,DN in pipeline),然后NN更新under-construction block的GS,length,locations
- 注意case1中建立的Pipeline不会通知NN,这是因为在client发起addBlock/append的时候NN就会生成新的Block,并且put到blockMap中,然后返回blk和locations给client。这个设计有个问题:在NN将新block加入到blockMap和DN创建该Block之间,如果有reader来读取这个新blk的时候,会得到一个“block does not exit”的错误。考虑这个情况不是经常发生。我们忽略这个情况,所以Client在新block建立Pipeline的时候,不通知NN。
- 当client进行addBlock或关闭文件的时候,NN将finallized最后一个blk的GS和length。如果最后一个blk有GS/length匹配的replica时,blk将变成complete,否则变成committed。另外如果最后一个blk的replica比replication factor要小的话,NN将显示的为这个blk进行备份。
- DataNode Reports
- DN有两种方式向NN发送replica的meta信息,一种是周期的发送blockReport,一种是当rbw状态的replica变成finallized的时候发送blockRecevied
- BlockReports
- 每次BlockReports包含两个list:finallized和rbw的。finallized list包含finallized replicas和之前是finallized状态现在under recovery的replicas。rbw list包含rbw/rur/rwr replicas(之前的状态是非finallized),rbw replica长度是BR值,rwr replica的长度是负值
- 每个BlockReport中元素汇报上来的是:<DataNode, blck_id, blck_GS, blck_len, isRbw>.
- 当NN收到BlockReport,将它和内存中的数据对比,产生三个列表(是否需要一个updateStateList):
- deleteList,这里包含所有blk_id是非法,如blk不在blockMap中或不属于任何文件
- addStoredBlockList,如果NN没有blockReport汇报上来的<DataNode, blck_id>,那么会加入到这个列表中
- rmStoredBlockList,如果NN有,但是blockReport汇报上来的<DataNode, blck_id>中没有的话,就加入到这个列表
- updateStateList,如果NN中的状态是rbw,但是汇报上来时已经finallized的,加入该list。
- 为了减轻clientreport和Dnreport之间的竞争,rbw-replicas只能加入deleteList和addStoreBlockList。
- 增加一个新的replica时:
- Block in NN 是complete。
- 如果report过来的replica是finallized的:
- 如果GS和length与NN中的记录不同,将其加入到blockMap中,但是标记为corrupt
- 否则加入这个replica
- 如果report过来的replica是rbw的:
- 如果文件是closed,并且如果汇报过来的GS/length和NN中的不同或者blk已经到达它的备份因子值,那么指示DN将其删除
- 否则,不做处理
- 如果report过来的replica是finallized的:
- Block in NN是committed。
- 和上面的相同,除了一个情况,如果reported replica是finallized的并且和NN中的blk具有相同的GS/length,那么NN将其改为complete。
- Block in NN是under-construction或者under-recover
- 如果汇报上来的replica是finallized的并且replica的GS不旧于NN中的记录,将其加入到NN中。并将其mark为finallized的,记录其长度和GS
- 如果reported replica是rbw的并且replica(GS不旧于NN中的,长度不小于NN的)是合法的,加入这个replica。如果汇报的replica是rbw的,标记为rbw,否则标记为rwr。
- 剩下的情况,直接忽略
- Block in NN 是complete。
- Update a replica‘s state
- 当一个blockreport显示一个replica从rbw改为finallized的。如果block是under-construction,NN将NN保存的replica标记为finallized并且保存replica的GS/length。如果blk是committed的,如果finallized replica符合block的GS/length,NN改block为complete状态,否则将replica从NN移除
- 当DN向NN发送一个blockRecevied的消息时,NN要么将其删除(如果是非法的),要么加入到blockMap中并更新replica的状态(如果NN在rbw时记录了该replica)
- BlockReports
- DN有两种方式向NN发送replica的meta信息,一种是周期的发送blockReport,一种是当rbw状态的replica变成finallized的时候发送blockRecevied
- 在以下情况,client通知NN一个under-construction的blk的metainfo或者状态改变了。
- replica在DN中的状态转移如下图所示
- 新replica被创建
- 如果是client发起,那么新replica以rbw状态开始
- 如果是NN指示去做replicate或者做reblance,那么replica以temporary状态开始
- 当DN重启时,rbw将转换为rwr( replica waiting to be recovered)
- 当lease过期时,replica进行recover时,会将状态改为rur( under recovery replica)
- client关闭,replica成功recover,或replication和copy成功都会将状态置为finallized
- Errorrecovery 总是将GS增加

- 新replica被创建
- block在NN中的状态转移如下图所示,其中:
- 新block被创建时,总是under-construction状态:
- 要么是client发起addBlock去加入一个block到文件中
- 要么是client发起append,但最后一个blk是full的
- 如果last block是未满的,append也可能导致complete的block改为under-construction。
- 当addBlock或close被发起的时候
- 最后一个block要么是complete(如果last block有一个GS/length匹配的finallized的replica),否则就是committed
- addBlock必须等到倒数第二个block变成complete
- 如果最后两个block不是complete的,文件无法关闭
- 当一个lease过期,lease recovery将一个block的under construction改为under recovery
- 一个block recovery将一个under recovery的block改为:
- Removed:如果所有的replica的length为0
- committed:如果recovery成功,但是该block没有GS/length匹配的finallized过的replica
- Complete:如果recovery成功,并且block有一个GS/length匹配的finallized的replica
- lease recovery将强制的把committed的block改为Complete
- 一个block recovery将一个under recovery的block改为:
- Block的状态不会持久化在磁盘中,当NN重启后未关闭文件的last block将变成under-construction,其余的是Complete。注意,如果文件的最后一个block如果是Complete或committed的block在NN重启之后也可能变为under-construction。如果client还在的话,client会再一次finallized。否则blockrecovery会finallized一遍
- 一旦一个block变成了committed或Complete,所有的它的replicas应该一样的GS并且是finallized。当一个block是under-construction,它将有多个代的block同时存在集群。
- 新block被创建时,总是under-construction状态:
