spark学习十一 spark中的sql
为什么需要SQL
SQL是一种标准,一种用来进行数据分析的标准,已经存在多年。
在大数据的背景下,随着数据规模的日渐增大,原有的分析技巧是否就过时了呢?答案显然是否定的,原来的分析技巧在既有的分析维度上依然保持有效,当然对于新的数据我们想挖掘出更多有意思有价值的内容,这个目标可以交给数据挖掘或者机器学习去完成。
那么原有的数据分析人员如何快速的转换到Big Data的平台上来呢,去重新学一种脚本吗,直接用scala或python去编写RDD。显然这样的代价太高,学习成本大。数据分析人员希望底层存储机制和分析引擎的变换不要对上层分析的应用有直接的影响,需求用一句话来表达就是,”直接使用sql语句来对数据进行分析“。
这也是为什么Hive兴起的原因了。Hive的流行直接证明这种设计迎合了市场的需求。由于Hive是采用了Hadoop的MapReduce作为分析执行引擎,其处理速度上不是尽如人意。Spark以快著称,很快有好事者写出了Shark,Shark取得了非常不俗的成绩,迎得了极好的口碑。
毕竟Shark是游离于Spark之外的一个项目,不受Spark节制,那么Spark开发团队的目标是将对SQL支持作用Spark的核心功能里面。以上分析就是Spark中的sql功能的由来。
应用举例
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
import sqlContext._
case class Person(name: String, age: Int)
val person = sc.textFile("examples/src/main/resources/people.txt").map(_.split(" ")).map(p => Person(p(0), p(1).trim.toInt))
person.registerAsTable("person")
val teenagers = sql("SELECT name, age FROM person WHERE age >= 13 and age <= 19")
teenagers.map(t => "name:" + t(0)).collect().foreach(println)
上述代码的逻辑非常清晰,就是将存在于person.txt中年龄界于13到19岁的年轻人名字打印出来。
SQL通用执行过程
SQL的组成部分
SQL语句大家都很熟悉,那么有没有仔细想过其有几大部分组成呢?可能你会说,”这还用问,不就是“select * from tablex where f1=?”,有什么好想吗?“
还是先来看看再说吧,说不定有些新的思维在里面呢?
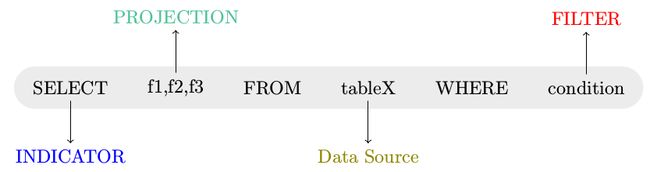
上图是对最简单的sql语句的重新标注,SELECT表示是一种具体的操作,即查询数据,”f1,f2,f3"表示返回的结果,tableX是数据源,condition部分是查询条件。有没有发觉SQL表达式中的顺序与常见的RDD处理逻辑其在表达的顺序上有差异。还是继续用图来表示不同吧。
SQL语句在分析执行过程中会经历下图所示的几个步骤
- 语法解析
- 操作绑定
- 优化执行策略
- 交付执行
语法解析
语法解析之后,会形成一棵语法树,如下图所示。树中的每个节点是执行的rule,整棵树称之为执行策略。
策略优化
形成上述的执行策略树还只是第一步,因为这个执行策略可以进行优化,所谓的优化就是对树中节点进行合并或是进行顺序上的调整。
以大家熟悉的join操作为例,下图给出一个join优化的示例。A JOIN B等同于B JOIN A,但是顺序的调整可能给执行的性能带来极大的影响,下图就是调整前后的对比图。
再举一例,一般来说尽可能的先实施聚合操作(Aggregate)然后再join
小结
上述一大通分析,希望达到的目的就两个。
- 语法解析之后生成一个执行策略树
- 执行策略树可以优化,优化的过程就是对树中节点进行合并或者顺序调整
有关SQL查询分析优化的具体过程,强烈推荐参考query optimizer deep dive系列文章
SQL在spark中的实现
有了上述内容的铺垫,想必你已经意识到Spark如果要很好的支持sql,势必也要完成,解析,优化,执行的三大过程。
整个SQL部分的代码,其大致分类如下图所示
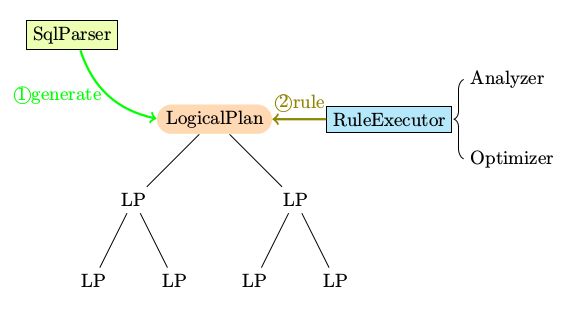
- SqlParser生成LogicPlan Tree
- Analyzer和Optimizer将各种rule作用于LogicalPlan Tree
- 最终优化生成的LogicalPlan生成Spark RDD
- 最后将生成的RDD交由Spark执行
阶段1:生成LogicalPlan
在sql中引入了一种新的RDD,即SchemaRDD
且看SchemaRDD的构造函数
class SchemaRDD( @transient val sqlContext: SQLContext, @transient protected[spark] val logicalPlan: LogicalPlan)
构造函数中总共两入参一为SparkContext,另一个LogicalPlan。LogicalPlan又是如何生成的呢?
要回答这个问题,不得不回到整个问题的入口点sql函数,sql函数的定义如下
def sql(sqlText: String): SchemaRDD = {
val result = new SchemaRDD(this, parseSql(sqlText))
result.queryExecution.toRdd
result
}
parseSql(sqlText)负责生成LogicalPlan,parseSql就是SqlParser的一个实例。
SqlParser这一部分的代码要理解起来关键是要搞清楚StandardTokenParsers的调用规则,里面有一大堆的符号,如果不理解是什么意思,估计很难理清头绪。
由于apply函数可以不被显示调用,所以parseSql(sqlText)一句其实会隐式的调用SqlParser中的apply函数
def apply(input: String): LogicalPlan = {
phrase(query)(new lexical.Scanner(input)) match {
case Success(r, x) => r
case x => sys.error(x.toString)
}
}
最最最让人蛋疼的一行代码就是phrase(query)(new lexical.Scanner(input))这里了,翻译过来就是如果输入的input字符串符合Lexical中定义的规则,则继续使用query处理。
看一下query的定义是什么
protected lazy val query: Parser[LogicalPlan] =
select * (
UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) } |
UNION ~ opt(DISTINCT) ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
) | insert
到了这里终于看到有LogicalPlan了,也就是说将普通的string转换成LogicalPlan在这里发生了。
query这段代码同时说明,在目前的spark sql中仅支持select和insert两种操作,至于delete, update暂不支持。
注:即便是到现在,估计你和当初一样对于SqlParser的使用还是一头雾水,不要紧,请参考ref[3]和[4]中的内容,至于那些稀奇古怪的符号到底是什么意思,请参考ref[5].
阶段2:QueryExecution
第一阶段,将string转换成为logicalplan tree,第二阶段将各种规则作用于LogicalPlan。
在第一阶段中展示的代码,哪一句会触发优化规则呢?是sql函数中的"result.queryExecution.toRdd",此处的queryExecution就是QueryExecution。这里又涉及到scala的一个语法糖问题。QueryExecution是一个抽象类,但却看到了下述的代码
protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
new this.QueryExecution { val logical = plan }
怎么可以创建抽象类的实例?我的世界坍塌了,呵呵。不要紧张,这在scala的世界是允许的,只不过scala是隐含的创建了一个QueryExecution的子类并初始化而已,java里的原则还是对的,人家背后有猫腻。
Ok,轮到阶段2中最重要的角色QueryExecution闪亮登场了
protected abstract class QueryExecution {
def logical: LogicalPlan
lazy val analyzed = analyzer(logical)
lazy val optimizedPlan = optimizer(analyzed)
lazy val sparkPlan = planner(optimizedPlan).next()
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
/** Internal version of the RDD. Avoids copies and has no schema */
lazy val toRdd: RDD[Row] = executedPlan.execute()
protected def stringOrError[A](f: => A): String =
try f.toString catch { case e: Throwable => e.toString }
def simpleString: String = stringOrError(executedPlan)
override def toString: String =
s"""== Logical Plan == |${stringOrError(analyzed)} |== Optimized Logical Plan == |${stringOrError(optimizedPlan)} |== Physical Plan == |${stringOrError(executedPlan)} """.stripMargin.trim
def debugExec() = DebugQuery(executedPlan).execute().collect()
}
三大步
- lazy val analyzed = analyzer(logical)
- lazy val optimizedPlan = optimizer(analyzed)
- lazy val sparkPlan = planner(optimizedPlan).next()
无论analyzer还是optimizer,它们都是RuleExecutor的子类,
RuleExecutor的默认处理函数是apply,对所有的子类都是一样的,RuleExecutor的apply函数定义如下,
def apply(plan: TreeType): TreeType = {
var curPlan = plan
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val result = rule(plan)
if (!result.fastEquals(plan)) {
logger.trace(
s""" |=== Applying Rule ${rule.ruleName} === |${sideBySide(plan.treeString, result.treeString).mkString("\n")} """.stripMargin)
}
result
}
iteration += 1
if (iteration > batch.strategy.maxIterations) {
logger.info(s"Max iterations ($iteration) reached for batch ${batch.name}")
continue = false
}
if (curPlan.fastEquals(lastPlan)) {
logger.trace(s"Fixed point reached for batch ${batch.name} after $iteration iterations.")
continue = false
}
lastPlan = curPlan
}
if (!batchStartPlan.fastEquals(curPlan)) {
logger.debug(
s""" |=== Result of Batch ${batch.name} === |${sideBySide(plan.treeString, curPlan.treeString).mkString("\n")} """.stripMargin)
} else {
logger.trace(s"Batch ${batch.name} has no effect.")
}
}
curPlan
}
对于RuleExecutor的子类来说,最主要的是定义自己的batches,来看analyzer中的batches是如何定义的
val batches: Seq[Batch] = Seq(
Batch("MultiInstanceRelations", Once,
NewRelationInstances),
Batch("CaseInsensitiveAttributeReferences", Once,
(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*),
Batch("Resolution", fixedPoint,
ResolveReferences ::
ResolveRelations ::
NewRelationInstances ::
ImplicitGenerate ::
StarExpansion ::
ResolveFunctions ::
GlobalAggregates ::
typeCoercionRules :_*),
Batch("AnalysisOperators", fixedPoint,
EliminateAnalysisOperators)
)
batch中定义了一系列的规则,这里再次出现语法糖问题。“如何理解::这个操作符”? ::表示cons的意思,即连接生成一个list.
Batch构造函数中需要指定一系列的Rule,像ResolveReferences就是Rule,有关Rule的代码就不一一分析了。
阶段3:LogicalPlan转换成Physical Plan
在阶段3最主要的代码就两行
- lazy val executePlan: SparkPlan = prepareForExecution(sparkPlan)
- lazy val toRdd: RDD[Row] = executedPlan.execute()
与LogicalPlan不同,SparkPlan最重要的区别就是有execute函数
针对Sparkplan的具体实现,又要分成UnaryNode, LeafNode和BinaryNode,简要来说即单目运算符操作,叶子结点,双目运算符操作。每个子类的具体实现可以自行参考源码。
阶段4: 触发RDD执行
RDD被触发真正执行的过程在看了前面几篇文章之后想来难不住你来,所有的所有都在这一行代码。
teenagers.map(p => "name:"+p(0)).foreach(println)
如果真的不明白,建议回头再读一下Spark Job的执行过程分析。
总结
行为至此,可以收笔了。应该说SQL部分的代码涉及到的知识点还是比较多的,最重要的是理清两点,即SQL语句的通用处理过程。另一个是Spark SQL子系统中具体实现机制。
Spark Sql子模块的具体实现紧紧围绕LogicalPlan Tree展开,一是用sqlparser来生成logicalplan,二是用RuleExecutor将各种Rule作用于LogicalPlan。最后生成普通的RDD将会给Spark core处理。